【Java递归秘籍】:初学者必学的递归逻辑掌握术
发布时间: 2024-11-17 02:46:35 阅读量: 12 订阅数: 21 

# 1. 递归算法概述
递归算法是计算机科学中一个基本且强大的概念,它允许算法调用自身来解决问题。在这一章节,我们将探讨递归算法的核心思想及其在编程中的应用。
## 1.1 递归算法的重要性
递归是一种将大问题分解为小问题,直至它们能够直接解决的方法。这种方法不仅逻辑清晰,而且能够将复杂的任务简化为更易管理的单元。尽管递归可能会引入额外的性能开销,但它的简洁性和表达能力使其成为许多领域不可或缺的工具,尤其是在数据结构和算法设计中。
## 1.2 递归与计算机科学
递归与计算机科学中的许多核心概念紧密相连,例如函数式编程和人工智能中的搜索算法。递归函数能够通过自身的重复执行来模拟复杂的决策过程,这对于解决需要分层或重复逻辑的问题非常有用。
在接下来的章节中,我们将深入分析递归算法的工作原理,探讨其与迭代的差异,以及如何高效地使用递归解决实际问题。我们将通过具体的代码示例和案例分析,帮助读者更好地理解这一重要概念。
# 2. 递归的基本原理
在第一章中,我们介绍了递归算法的概念和重要性,为理解递归打下了基础。现在,我们将深入探讨递归的内部机制、其与迭代的关系,以及构建递归函数时需要遵循的三要素。这些知识将帮助我们更好地理解递归工作原理,并在后续章节中,应用于各种算法实践。
## 2.1 递归的定义和工作原理
### 2.1.1 递归的数学基础
递归的概念最初来源于数学中的递归关系。一个递归序列的定义依赖于其前几个项的值。例如,自然数的阶乘可以定义为:`n! = n * (n-1)!`,其中 `0! = 1`。在递归函数中,我们用函数的输出定义函数的输入,通过这种方式,递归函数可以一直调用自身,直到达到基本情况(Base Case),这时不再进行自我调用。
```python
def factorial(n):
if n == 0: # 基本情况
return 1
else:
return n * factorial(n-1) # 递归情况
print(factorial(5)) # 输出: 120
```
### 2.1.2 递归函数的自我引用
递归函数是一个能够自我调用的函数。它将问题分解为更小的子问题,并在子问题解决后再将结果合并起来得到原问题的解。在实现递归时,必须有明确的终止条件(即基本情况),否则函数会无限自我调用,直至栈溢出。
递归函数的自我引用特性使得一些问题的算法实现异常简洁。比如斐波那契数列的第 `n` 项可以表示为前两项之和,这很容易用递归函数来实现:
```python
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
print(fibonacci(10)) # 输出: 55
```
## 2.2 递归与迭代的比较
### 2.2.1 递归与迭代的效率分析
递归和迭代都是编程中常用的算法结构,两者在效率上往往有所区别。递归实现通常更为直观,易于理解和实现,但可能会引入额外的性能开销,如函数调用的开销、栈空间的使用等。迭代实现则是通过循环结构逐次逼近结果,通常比递归具有更小的内存占用和更快的执行速度。
```python
# 递归方式计算阶乘
def factorial_recursive(n):
if n == 0:
return 1
return n * factorial_recursive(n-1)
# 迭代方式计算阶乘
def factorial_iterative(n):
result = 1
for i in range(1, n+1):
result *= i
return result
```
### 2.2.2 递归到迭代的转换技巧
尽管递归在某些情况下写起来更简单,但在实际应用中,特别是在函数调用栈深度有限的情况下,递归可能会导致栈溢出。将递归算法转换为迭代算法可以解决这个问题。转换的技巧通常包括使用循环、状态变量和队列或栈结构。
以二分查找为例,递归实现可能如下:
```python
def binary_search_recursive(arr, target):
if not arr:
return -1
mid = len(arr) // 2
if arr[mid] == target:
return mid
elif arr[mid] > target:
return binary_search_recursive(arr[:mid], target)
else:
result = binary_search_recursive(arr[mid+1:], target)
return -1 if result == -1 else mid + 1 + result
```
而迭代实现则可能使用循环:
```python
def binary_search_iterative(arr, target):
low, high = 0, len(arr) - 1
while low <= high:
mid = (low + high) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
low = mid + 1
else:
high = mid - 1
return -1
```
## 2.3 递归的三要素
### 2.3.1 基本情况(Base Case)
基本情况是递归函数中不需要再次调用自身就能得出答案的条件。它是递归能够停止递归调用、返回结果的关键。没有基本情况,递归将无限进行下去,最终导致栈溢出。
### 2.3.2 递归情况(Recursive Case)
递归情况是递归函数中需要再次调用自身来解决一个更小问题的条件。递归情况是递归函数执行的核心,它不断地将问题分解为更小的问题,直到达到基本情况。
### 2.3.3 边界条件(Boundary Conditions)
边界条件定义了函数作用范围的限制。在递归函数中,边界条件是递归继续执行的条件,它指出了函数需要处理的数据范围。在有些情况下,边界条件和基本情况是重合的。
```mermaid
graph TD;
A[开始] -->|基本情况| B[返回结果];
A -->|递归情况| C[问题分解];
C -->|边界条件| B;
```
递归函数需要恰当的处理这三个要素,以确保能正确、高效地解决目标问题。在下一章节中,我们将详细讨论如何在排序算法和搜索算法中应用递归。
# 3. 递归算法实践
## 3.1 递归在排序算法中的应用
递归算法在排序问题中的应用是经典且广泛的教学案例。这里主要探讨两种通过递归实现的高效排序算法:快速排序和归并排序。
### 3.1.1 递归实现快速排序
快速排序(Quick Sort)是一种分而治之的排序算法,通过递归将大数据集分割成小数据集来提高效率。快速排序的核心思想是选择一个元素作为"基准"(pivot),然后将数组分为两部分,一部分包含小于基准的元素,另一部分包含大于基准的元素,之后再递归地对这两部分继续进行快速排序。
下面是一个递归实现快速排序的代码示例:
```python
def quick_sort(arr):
if len(arr) <= 1:
return arr
else:
pivot = arr[0]
less = [x for x in arr[1:] if x <= pivot]
greater = [x for x in arr[1:] if x > pivot]
return quick_sort(less) + [pivot] + quick_sort(greater)
```
### 3.1.2 递归实现归并排序
归并排序(Merge Sort)也是一种分而治之的算法,它将数组分成两半,分别排序,然后将结果合并起来。归并排序在合并两个有序子数组时使用递归。
以下是一个归并排序的代码实现:
```python
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
```
### 3.1.3 快速排序与归并排序对比
快速排序和归并排序都是高效的排序算法,通常它们在最坏情况下的时间复杂度都是O(n log n)。然而,它们在空间复杂度、实际运行时间、稳定性等方面各有优劣。快速排序通常是就地排序,节省空间,但不稳定;归并排序需要额外空间来合并数组,但它稳定且一般情况下运行时间较均匀。
## 3.2 递归在搜索算法中的应用
递归同样在搜索算法中有其独特的应用,尤其是在需要深入搜索数据结构的算法中。
### 3.2.1 二分搜索的递归实现
二分搜索(Binary Search)是另一种递归算法的典型应用。二分搜索通过不断将搜索区间一分为二,只在可能包含目标值的那部分区间内继续搜索。以下是二分搜索的递归实现代码:
```python
def binary_search(arr, target):
return binary_search_helper(arr, target, 0, len(arr) - 1)
def binary_search_helper(arr, target, left, right):
if left > right:
return -1
mid = left + (right - left) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
return binary_search_helper(arr, target, mid + 1, right)
else:
return binary_search_helper(arr, target, left, mid - 1)
```
### 3.2.2 深度优先搜索(DFS)算法
深度优先搜索(Depth-First Search, DFS)是一种用于遍历或搜索树或图的算法。DFS利用递归或栈的后进先出(LIFO)特性,尽可能深地搜索树的分支。
下面是DFS的一个简单图遍历示例代码:
```python
def dfs(graph, start, visited=None):
if visited is None:
visited = set()
visited.add(start)
print(start)
for next_node in graph[start] - visited:
dfs(graph, next_node, visited)
return visited
```
在树或图的遍历中,DFS非常适合寻找路径或者检测是否存在环。
## 3.3 递归在数学问题中的应用
递归在解决某些数学问题时也显示出其独特的优势。
### 3.3.1 斐波那契数列的递归实现
斐波那契数列是一个著名的数学递归序列,每一项都是前两项的和。递归实现斐波那契数列非常直观:
```python
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n - 1) + fibonacci(n - 2)
```
虽然递归代码清晰,但当n较大时,其效率低下,因为重复计算了大量子问题。
### 3.3.2 阶乘函数的递归实现
阶乘函数是另一个递归的经典案例。n的阶乘表示为n!,即从1乘到n的所有整数的乘积。
以下是阶乘函数的递归实现:
```python
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
```
递归方法实现阶乘函数简洁明了,适用于教学演示,但并不适合大规模计算。
通过递归算法实践章节,我们已经了解了递归在各种算法中的具体应用,下一章节将进一步探讨如何优化这些递归算法,提升性能。
# 4. 递归算法的优化技巧
在前面的章节中,我们已经了解了递归算法的基础知识和实践应用。然而,在实际编程中,递归算法的效率和性能往往是一个需要重点关注的问题。本章将深入探讨递归算法的优化技巧,这些技巧可以帮助我们编写更高效、更稳定的代码。
## 4.1 记忆化递归(Memoization)
### 4.1.1 记忆化技术的基本概念
记忆化是一种优化递归算法的技术,它通过存储已经计算过的结果来避免重复计算,从而提高程序效率。简单来说,记忆化就是使用一个数据结构(通常是一个数组或者字典)来缓存已经计算过的子问题的答案。
### 4.1.2 实现记忆化的递归示例
以计算斐波那契数列为例,传统的递归方法由于重复计算,效率非常低。下面展示了如何使用记忆化技术来优化斐波那契数列的递归实现。
```python
def fibonacci(n, memo={}):
if n in memo:
return memo[n]
if n <= 2:
return 1
memo[n] = fibonacci(n-1, memo) + fibonacci(n-2, memo)
return memo[n]
# 使用记忆化技术计算斐波那契数列的第10项
print(fibonacci(10)) # 输出 55
```
#### 代码逻辑解读
- 我们定义了一个名为 `fibonacci` 的函数,它接受两个参数:`n` 表示要计算的斐波那契数列的项数,`memo` 是用于存储已经计算过的值的字典。
- 首先检查 `memo` 字典中是否已经存在 `n` 的值,如果存在,则直接返回该值,避免重复计算。
- 如果 `n` 是小于或等于2的基本情况,则直接返回1,因为斐波那契数列的前两项都是1。
- 如果当前项不在 `memo` 中,递归计算 `n-1` 和 `n-2` 的值,并将它们相加,然后存入 `memo`。
- 最终返回 `n` 对应的斐波那契数。
通过使用记忆化技术,我们显著减少了递归的计算次数,避免了大量重复工作,从而大幅提高了算法效率。
## 4.2 尾递归优化
### 4.2.1 尾递归的原理
尾递归是一种特殊的递归形式,其中递归调用是函数体中最后一个操作。尾递归可以被编译器优化,将函数调用时的栈帧重新利用,从而避免栈溢出。
### 4.2.2 尾递归优化的实现与限制
Python 并不原生支持尾递归优化,但是我们可以手动实现尾递归逻辑,来模拟优化效果。
```python
def tail_recursive_factorial(n, accumulator=1):
if n == 0:
return accumulator
else:
return tail_recursive_factorial(n-1, accumulator * n)
# 使用尾递归函数计算阶乘
print(tail_recursive_factorial(5)) # 输出 120
```
#### 代码逻辑解读
- 我们定义了一个名为 `tail_recursive_factorial` 的函数,它接受两个参数:`n` 表示需要计算阶乘的数字,`accumulator` 是累加器,用于存储中间计算结果。
- 函数首先检查基本情况,即 `n` 是否为0。如果是,则直接返回累加器 `accumulator` 的值。
- 如果不是基本情况,函数使用递归调用自身,并更新 `n` 和 `accumulator` 的值。
- 这样,每次递归调用都是尾部调用,因为在调用后没有其他操作。
尽管Python不会优化尾递归,但是使用尾递归形式可以让我们更容易地将递归逻辑转换为迭代逻辑,以避免深度递归导致的栈溢出。
## 4.3 避免栈溢出的策略
### 4.3.1 栈溢出的原因分析
栈溢出是由于递归调用层次太深,导致调用栈空间耗尽。每次函数调用都会占用一定的栈空间来存储局部变量和返回地址等信息。递归深度过大时,这些信息可能会占用过多的栈空间,从而导致栈溢出。
### 4.3.2 使用迭代代替递归避免栈溢出
为了防止栈溢出,我们可以将递归算法改写为迭代算法。
```python
def iterative_factorial(n):
result = 1
for i in range(2, n + 1):
result *= i
return result
# 使用迭代函数计算阶乘
print(iterative_factorial(5)) # 输出 120
```
#### 代码逻辑解读
- 我们定义了一个名为 `iterative_factorial` 的函数,它接受一个参数 `n` 表示需要计算阶乘的数字。
- 函数使用一个循环来计算阶乘,这样就避免了递归调用,从而不会增加调用栈的深度。
- 循环中,我们从2开始逐步将每个数与当前结果相乘,并在循环结束时返回最终的阶乘结果。
通过使用迭代代替递归,我们不仅可以避免栈溢出的问题,还可以使算法更加高效,因为迭代通常比递归有更低的空间复杂度。
以上章节详细讨论了递归算法的优化技巧,包括记忆化递归、尾递归优化以及避免栈溢出的策略。通过实例和代码展示,我们了解到这些优化技巧在提升递归算法性能方面的重要性。在接下来的章节中,我们将进一步探讨递归算法的高级主题以及如何分析与解决递归算法中的实际问题。
# 5. 递归算法的高级主题
## 5.1 分治法
### 5.1.1 分治法的基本思想
分治法是递归算法中的一种重要策略,其基本思想是将一个难以直接解决的大问题划分成若干个小问题,递归地解决这些子问题,然后再将子问题的解合并以得到原问题的解。
分治法的一般步骤包括:
1. **分解**:将原问题分解成一系列子问题。
2. **解决**:递归地解决各个子问题。如果子问题足够小,则直接求解。
3. **合并**:将子问题的解合并成原问题的解。
分治法适用于具有如下形式的问题:
- 原问题的规模缩小到一定的程度就可以容易地解决。
- 原问题可以分解为若干个规模较小的相同问题。
### 5.1.2 分治算法的设计与实现
设计分治算法时,需要考虑如何有效地分解问题,以及如何高效地合并子问题的解。下面以快速排序算法为例,说明分治法的应用。
**快速排序算法**:
快速排序是一种常用的排序算法,它采用分治法的策略来对一个数组进行排序。快速排序的基本步骤如下:
1. **选择基准**:选择数组中的一个元素作为基准(pivot)。
2. **分区操作**:重新排列数组,使得所有比基准小的元素都在基准前面,所有比基准大的元素都在基准后面。这一步称为分区(partitioning)。
3. **递归排序**:递归地对基准前后的子数组进行快速排序。
快速排序算法的伪代码如下:
```plaintext
function quicksort(array, low, high)
if low < high
pivot_index = partition(array, low, high)
quicksort(array, low, pivot_index - 1)
quicksort(array, pivot_index + 1, high)
function partition(array, low, high)
pivot = array[high]
i = low - 1
for j = low to high - 1
if array[j] < pivot
i = i + 1
swap array[i] with array[j]
swap array[i + 1] with array[high]
return i + 1
```
**代码逻辑分析**:
- `quicksort` 函数是快速排序的主要逻辑。它接受一个数组以及数组的下界 `low` 和上界 `high` 作为参数。
- `partition` 函数用于将数组分割成两部分,并返回基准元素的最终位置,这个位置可以用来递归地对数组的两部分进行排序。
### 5.2 动态规划与递归
#### 5.2.1 动态规划与递归的关系
动态规划(Dynamic Programming,DP)是一种算法思想,它将复杂问题分解为更小的子问题,并存储这些子问题的解(通常称为“状态”),以避免重复计算。递归是实现动态规划的一种方式,但动态规划算法通常使用迭代方法,并借助表格(数组)来存储中间结果,从而避免了大量的递归调用和重复计算。
动态规划与递归的关系可以用以下几点来概括:
- 递归提供了一种自然的方式来表达某些动态规划问题。
- 动态规划通常需要优化递归算法,以减少时间和空间复杂度。
- 动态规划算法通常使用自底向上的方法来解决问题,而递归算法通常是自顶向下的。
#### 5.2.2 递归在动态规划中的应用实例
**斐波那契数列**是递归和动态规划经常引用的一个例子。
递归实现斐波那契数列的代码如下:
```python
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
```
**动态规划实现斐波那契数列**:
```python
def fibonacci_dp(n):
if n <= 1:
return n
fib = [0] * (n+1)
fib[1] = 1
for i in range(2, n+1):
fib[i] = fib[i-1] + fib[i-2]
return fib[n]
```
**代码逻辑分析**:
- 在递归实现中,函数 `fibonacci` 递归地调用自身来计算斐波那契数列的值。这种方法虽然简洁,但对于较大的 `n` 值,会产生大量的重复计算。
- 动态规划的实现使用了数组 `fib` 来存储已经计算过的斐波那契数,以避免重复计算。这种方法的效率更高,时间复杂度为 O(n)。
### 5.3 递归在树形结构中的应用
#### 5.3.1 树的遍历算法(前中后序)
在树的遍历算法中,递归被广泛应用于实现前序遍历、中序遍历和后序遍历。
**前序遍历**:
```python
def preorder_traversal(root):
if root is None:
return []
return [root.val] + preorder_traversal(root.left) + preorder_traversal(root.right)
```
**中序遍历**:
```python
def inorder_traversal(root):
if root is None:
return []
return inorder_traversal(root.left) + [root.val] + inorder_traversal(root.right)
```
**后序遍历**:
```python
def postorder_traversal(root):
if root is None:
return []
return postorder_traversal(root.left) + postorder_traversal(root.right) + [root.val]
```
**代码逻辑分析**:
- 这三个函数都采用递归的方式遍历树的节点。
- `preorder_traversal` 函数首先访问根节点,然后递归地访问左子树,最后递归地访问右子树。
- `inorder_traversal` 函数首先递归地访问左子树,然后访问根节点,最后递归地访问右子树。
- `postorder_traversal` 函数首先递归地访问左子树,然后递归地访问右子树,最后访问根节点。
#### 5.3.2 递归算法在二叉树中的应用
递归算法在二叉树中的应用不仅限于遍历,还包括诸如查找、插入、删除等操作。以下是一个在二叉搜索树中查找元素的递归示例。
```python
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
def search_bst(root, val):
if root is None or root.val == val:
return root
if val < root.val:
return search_bst(root.left, val)
else:
return search_bst(root.right, val)
```
**代码逻辑分析**:
- `search_bst` 函数接受一个二叉搜索树的根节点和一个要查找的值 `val` 作为参数。
- 如果根节点为空或其值等于 `val`,则找到了目标值,返回根节点。
- 如果要查找的值小于根节点的值,则递归地在左子树中查找。
- 如果要查找的值大于根节点的值,则递归地在右子树中查找。
树的递归算法往往与树的结构紧密相关,递归的使用能够直观而简洁地实现许多复杂的数据操作。在处理树形结构数据时,熟练掌握递归算法是十分必要的。
# 6. 递归算法实例分析与挑战
## 6.1 典型递归算法问题剖析
### 6.1.1 硬币找零问题
硬币找零问题是递归算法中一个非常经典的示例,它展示了如何通过递归方式解决组合问题。问题要求从一组硬币中找到给定金额的组合方式。
- **问题描述**:给定不同面额的硬币和一个总金额,编写一个函数来计算可以凑成总金额的硬币组合数。
- **解法思路**:这是一个典型的组合问题,可以使用递归函数来进行暴力搜索。我们定义一个递归函数 `coinChange(coins, amount, index, count)`,其中 `coins` 是硬币数组,`amount` 是目标金额,`index` 是当前考虑的硬币索引,`count` 是当前找到的组合数量。
```python
def coinChange(coins, amount, index, count):
# 基本情况:金额减到0,找到了一种组合方式
if amount == 0:
return count + 1
# 递归情况:遍历所有的硬币
if index < len(coins):
return (coinChange(coins, amount - coins[index], index + 1, count) +
coinChange(coins, amount, index + 1, count))
return count
```
### 6.1.2 汉诺塔问题
汉诺塔问题是一个经典的递归问题,它要求通过递归移动所有的盘子从一个塔座移动到另一个塔座。
- **问题描述**:有三根柱子,从左到右分别命名为 A、B、C。开始时所有盘子都放在 A 柱子上,按大小顺序叠放。目标是将所有盘子移动到 C 柱子上,过程中必须遵守以下规则:
1. 每次只能移动一个盘子。
2. 盘子只能从顶端滑出,滑入下一个柱子的顶端。
3. 任何时候,在三个柱子之间,较大的盘子不能叠在较小的盘子上。
- **解法思路**:递归策略是将问题分解为移动 n-1 个盘子到辅助柱子,然后将最大的盘子移动到目标柱子,最后将 n-1 个盘子从辅助柱子移动到目标柱子。
```python
def hanoi(n, source, target, auxiliary):
if n == 1:
print(f"Move disk 1 from {source} to {target}")
else:
hanoi(n-1, source, auxiliary, target)
print(f"Move disk {n} from {source} to {target}")
hanoi(n-1, auxiliary, target, source)
```
## 6.2 递归算法的调试与错误处理
### 6.2.1 递归中的常见错误
在递归算法中,常见错误包括但不限于以下几点:
- **无限递归**:没有正确的基本情况或递归情况错误,导致函数不断调用自身,直到栈溢出。
- **逻辑错误**:递归逻辑错误,如循环条件处理不当,导致结果与预期不符。
- **栈溢出**:递归深度太大,导致栈空间耗尽。
### 6.2.2 调试递归函数的策略
调试递归函数需要特别注意递归的终止条件和递归逻辑。
- **检查基本情况**:确保每个递归函数都有明确的停止条件。
- **逻辑检查**:验证递归的每一步是否都符合预期。
- **测试边界条件**:特别注意边界条件下的递归行为。
- **使用日志或打印语句**:在递归调用前后添加日志输出,跟踪递归调用的过程。
## 6.3 递归算法的面试题与挑战
### 6.3.1 面试题目的递归解法
在技术面试中,递归算法是考察的重点。例如,数组或链表的反转、二叉树的遍历等。
- **反转数组**:
给定一个数组,实现一个递归函数来反转数组中的元素。
```python
def reverse_array(arr, start, end):
if start >= end:
return
arr[start], arr[end] = arr[end], arr[start]
reverse_array(arr, start + 1, end - 1)
```
### 6.3.2 递归算法的思维训练与提高
- **递归思想**:理解递归的本质,学会如何将问题分解为子问题。
- **实践**:通过编码练习,如解决 LeetCode 上的递归题目,来提高递归思维。
- **优化**:思考如何优化递归算法,避免重复计算和栈溢出等问题。
递归算法的练习和理解需要时间,但随着经验的积累,将有助于解决更复杂的问题,并在技术面试中脱颖而出。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Java 中递归的方方面面,从初学者的入门指南到高级优化技术。专栏涵盖了递归的原理、栈机制、尾递归优化、递归与迭代的比较,以及递归在各种实际场景中的应用,包括二叉树遍历、算法竞赛、字符串处理、并行计算、文件系统导航、数据结构和人工智能。通过深入浅出的讲解、丰富的示例和最佳实践,本专栏旨在帮助 Java 开发人员掌握递归这一强大的编程技术,并将其应用于解决复杂问题和优化算法性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SNAP自动化流程设计:提高备份效率的秘诀

# 摘要
SNAP备份技术作为一种数据备份解决方案,在保证数据一致性和完整性方面发挥着关键作用。本文全面概述了SNAP技术的基本概念、自动化流程的设计基础以及实现实践操作。文章不仅探
光学模拟原理:光源设定的物理学基础

# 摘要
本文从光学模拟的角度出发,对光源理论及其在光学系统中的应用进行了全面综述。首先介绍了光学模拟的基础知识和光源的基本物理特性,包括光的波粒二象性和光源模型的分类。随后,深入探讨了光学模拟软件的选用、光源模拟实验的设计、结果的验证与优化,以及在成像系统、照明设计和光学测量中的应用。文章还展望了新型光源技术的创新和发展趋势,特别是量子点光源与LED技术的进步,以及人工智能在光学模拟中的应
全球互操作性难题:实现不同MMSI编码表系统间的兼容性

# 摘要
本文系统性地探讨了MMSI编码表系统的基本概念、互操作性的重要性及其面临的挑战,并深入分析了理论框架下的系统兼容性。通过对现有MMSI编码表兼容性策略的研究,本文提出了实际案例分析及技术工具应用,详细阐述了故障排查与应对策略。最后,文章展望了MMSI系统兼容性的发展前景和行业标准的期待,指出了新兴技术在提升MMSI系统兼容性方面的潜力以及对行业规范制定的建议。
# 关键字
MMSI编
软件项目投标技术标书撰写基础:规范与格式指南

# 摘要
技术标书是软件项目投标中至关重要的文件,它详细阐述了投标者的项目背景、技术解决方案和质量保障措施,是赢得投标的关键。本文对技术标书的结构和内容规范进行了细致的分析,着重阐述了编写要点、写作技巧、案例和证明材料的利用,以及法律合规性要求。通过对标书的格式和排版、项目需求分析、技术方案阐述、风险评估及质量保障措施等方面的深入探讨,本文旨在提供一系列实用的指导和
FC-AE-ASM协议与容灾策略的整合:确保数据安全和业务连续性的专业分析

# 摘要
本文全面介绍了FC-AE-ASM协议的基本概念、特点及其在容灾系统中的应用。首先概述了FC-AE-ASM协议,接着详细探讨了容灾策略的基础理论,包括其定义、重要性、设计原则以及技术选择。第三章深入分析FC-AE-ASM协议在数据同步与故障切换中的关键作用。第四章通过实践案例,展示了如何将FC-AE-ASM协议与容灾策略结合起来,并详细阐述了实施过程与最佳实践。最后,文章展望了FC-AE-ASM与容灾策略的未来发展趋势,讨论了技
【PAW3205DB-TJ3T的维护和升级】:关键步骤助您延长设备寿命
# 摘要
本文全面介绍了PAW3205DB-TJ3T设备的维护与升级策略,旨在提供一套完善的理论知识和实践步骤。通过分析设备组件与工作原理,以及常见故障的类型、成因和诊断方法,提出了有效的维护措施和预防性维护计划。同时,详细阐述了设备的清洁检查、更换耗材、软件更新与校准步骤,确保设备的正常运行和性能维持。此外,本文还探讨了设备升级流程中的准备、实施和验证环节,以及通过最佳实践和健康管理延长设备寿命的策略。案例研究部分通过实际经验分享,对维护和升级过程中的常见问题进行了澄清,并对未来技术趋势进行展望。
# 关键字
设备维护;升级流程;故障诊断;健康管理;最佳实践;技术趋势
参考资源链接:[P
【Simulink模型构建指南】:实战:如何构建精确的系统模型
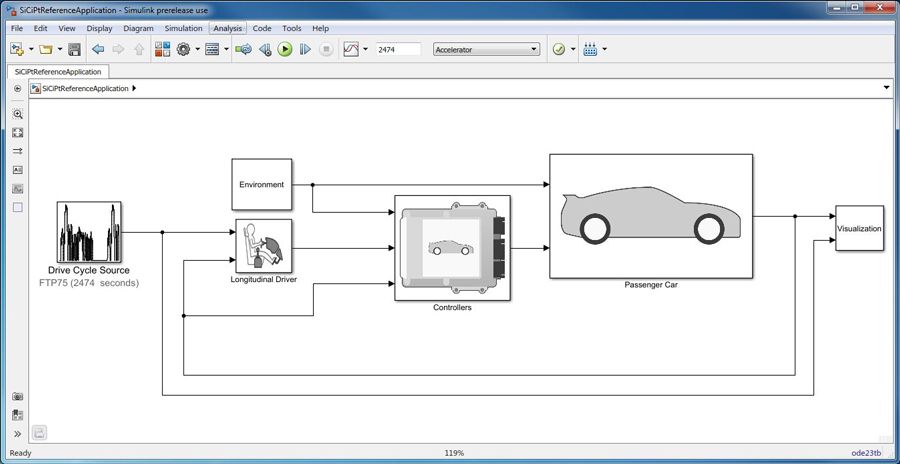
# 摘要
本文全面探讨了Simulink模型的构建、高级技术、测试与验证以及扩展应用。首先介绍了Simulin
【拥抱iOS 11】:适配中的旧设备兼容性策略与实践
# 摘要
随着iOS 11的发布,旧设备的兼容性问题成为开发者面临的重要挑战。本文从理论与实践两个层面分析了旧设备兼容性的基础、技术挑战以及优化实践,并通过案例研究展示了成功适配iOS应用的过程。本文深入探讨了iOS系统架构与兼容性原理,分析了性能限制、硬件差异对兼容性的影响,提供了兼容性测试流程和性能优化技巧,并讨论了针对旧设备的新API应用和性能提升方法。最后,文章对未来iO
【PetaLinux驱动开发基础】:为ZYNQ7045添加新硬件支持的必备技巧

# 摘要
本文旨在为使用ZYNQ7045平台和PetaLinux的开发人员提供一个全面的参考指南,涵盖从环境搭建到硬件驱动开发的全过程。文章首先介绍了ZYNQ7045平台和PetaLinux的基本概念,随后详细讲解了PetaLinux环境的搭建、配置以及系统定制和编译流程。接着,转向硬件驱动开发的基础知识,包括驱动程序的分类、Linux内核模块编
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )