【Pylons实践案例】:构建高效Web应用的5个关键步骤
发布时间: 2024-10-14 19:19:33 阅读量: 16 订阅数: 26 

# 1. Pylons框架概述
## Pylons框架简介
Pylons是一个高效、灵活的Python Web框架,旨在简化Web应用的开发过程。它遵循MVC(模型-视图-控制器)架构模式,使得开发者能够以清晰和有组织的方式构建Web应用。Pylons以其轻量级和非侵入式的特性而闻名,为开发者提供了强大的自由度来设计和实现功能。
## Pylons的核心特点
Pylons的核心特点包括其强大的URL路由系统、灵活的配置选项、以及对多种模板引擎的支持。它内置了多种工具和功能,如Web表单处理、安全性控制、数据库ORM映射等,使得开发者能够快速构建出高性能的Web应用。此外,Pylons还支持插件系统,允许开发者根据需要扩展框架的功能。
## 安装和运行Pylons
要开始使用Pylons,首先需要安装Python环境。接着,可以使用pip安装Pylons框架。安装完成后,可以创建一个简单的Pylons项目,并通过内置的开发服务器来启动和测试应用。下面是一个基本的安装和运行Pylons应用的示例:
```bash
# 安装Python
sudo apt-get install python3
# 使用pip安装Pylons
pip install Pylons
# 创建一个新的Pylons项目
pylons-init my_project
# 进入项目目录
cd my_project
# 运行开发服务器
paster serve development.ini
```
以上步骤将引导你完成Pylons框架的初步安装和一个新项目的创建,以及如何启动并测试它。这是迈向构建强大Web应用的第一步。
# 2. 环境搭建与项目初始化
### 2.1 Pylons环境配置
#### 2.1.1 安装Python和Pylons
在本章节中,我们将介绍如何安装Python环境以及Pylons框架。Pylons是一个基于Python的Web开发框架,以其简洁的设计和强大的功能而闻名。首先,确保你的系统中已经安装了Python,可以通过在终端中输入`python --version`或者`python3 --version`来检查Python的版本。
安装Python之后,我们需要安装Pylons框架。在Python的包管理工具pip的帮助下,安装Pylons框架非常简单。打开终端并执行以下命令:
```bash
pip install pylons
```
请注意,这里使用的是pip而不是pip3,因为有些系统区分了pip和pip3,以支持Python 2和Python 3的并行安装。如果你的系统中同时安装了Python 2和Python 3,你可能需要使用`pip3`命令来安装Pylons。
安装完成后,可以通过以下命令验证Pylons是否正确安装:
```bash
python -m pylons --version
```
如果安装成功,它将显示Pylons的版本号。
#### 2.1.2 创建项目环境和虚拟环境
在本章节中,我们将创建一个新的Pylons项目环境和虚拟环境。虚拟环境是一个独立的Python环境,它允许我们为不同的项目安装不同版本的库,而不会影响到系统的全局Python环境。
为了创建一个新的虚拟环境,我们使用Python自带的`venv`模块。在你的工作目录中,执行以下命令来创建一个新的虚拟环境目录:
```bash
python -m venv myprojectenv
```
这里的`myprojectenv`是虚拟环境的目录名称,你可以根据自己的项目来命名。创建虚拟环境后,我们需要激活它。在Linux或MacOS上,使用以下命令:
```bash
source myprojectenv/bin/activate
```
在Windows上,使用以下命令:
```cmd
myprojectenv\Scripts\activate.bat
```
激活虚拟环境后,你会看到命令行提示符的开头多了一个括号,里面包含了虚拟环境的名称,这表示你现在已经处于虚拟环境中了。
在虚拟环境中,你可以安装项目所需的库,包括Pylons框架。如果你还没有安装Pylons,现在可以安装它:
```bash
pip install pylons
```
### 2.2 Pylons项目结构
#### 2.2.1 目录结构解析
在本章节中,我们将解析Pylons项目的目录结构。一个标准的Pylons项目目录结构包含了一系列的文件和目录,每个都有其特定的作用。以下是Pylons项目的基本目录结构:
```
myproject/
├── .venv/
├── controllers/
├── public/
│ ├── images/
│ ├── javascripts/
│ └── stylesheets/
├── templates/
├── tests/
├── lib/
├── logs/
├── setup.py
└── README
```
- **.venv/** - 这个目录包含了虚拟环境的所有文件,通常是隐藏的。
- **controllers/** - 这个目录包含所有的控制器代码。
- **public/** - 这个目录用于存放静态文件,如图片、JavaScript和样式表。
- **templates/** - 这个目录包含所有的模板文件,通常使用Mako模板引擎。
- **tests/** - 这个目录用于存放测试代码。
- **lib/** - 这个目录用于存放项目依赖的库文件。
- **logs/** - 这个目录用于存放日志文件。
- **setup.py** - 这是一个Python项目的基本构建脚本。
- **README** - 这是一个包含项目说明的文本文件。
#### 2.2.2 配置文件概览
在本章节中,我们将概览Pylons项目的配置文件。Pylons项目的配置文件主要集中在项目根目录下,这些配置文件定义了项目的行为和环境设置。
最核心的配置文件是`config.ini`,它位于`myproject/config/`目录下。这个文件通常包含数据库连接、服务器配置、路由映射等信息。下面是一个简单的配置文件示例:
```ini
[app:main]
# 设置应用程序名称
name = myproject
# 设置应用模块
module = myproject
# 设置应用的静态文件目录
static_files = True
static_path = public:public
# 设置模板引擎
pylons.somevar = some value
```
除了`config.ini`,还有一些其他的配置文件,如数据库配置文件(通常是`database.ini`),它们提供了数据库连接的详细信息。此外,还有一些环境特定的配置文件,如开发环境的`development.ini`和生产环境的`production.ini`。
### 2.3 Pylons项目初始化
#### 2.3.1 创建初始项目
在本章节中,我们将介绍如何创建一个新的Pylons项目。在虚拟环境中,可以使用Pylons提供的命令行工具`paster`来创建一个初始项目。执行以下命令:
```bash
paster create -t pylons myproject
```
这里的`myproject`是你的项目名称,`-t pylons`指定模板类型为Pylons。这个命令会创建一个新的目录结构,并在其中生成一些初始文件和配置。
创建项目后,需要安装项目依赖的库。进入项目目录,运行以下命令:
```bash
cd myproject
python setup.py develop
```
这将把你的项目注册到Python环境中,使得项目依赖的库可以在项目中直接使用。
#### 2.3.2 启动和测试项目
在本章节中,我们将介绍如何启动和测试新创建的Pylons项目。首先,确保项目已经安装了所有依赖并且配置正确。然后,启动项目:
```bash
cd myproject
paster serve development.ini
```
这里,`development.ini`是开发环境的配置文件。如果一切设置正确,Pylons服务器将启动,并在默认端口(通常是8080)上监听。
在浏览器中访问`***`,你应该能看到Pylons欢迎页面,这意味着你的Pylons项目已经成功运行。
为了测试项目,我们可以创建一个简单的控制器和视图。在`controllers`目录下创建一个名为`root.py`的文件,并添加以下代码:
```python
from pylons import request, response, make_response
from pylons.controller import Controller
from pylons.i18n import _, ungettext, ngettext
from pylons.wsgiapp import WSGIApplication
class RootController(Controller):
def index(self):
return 'Hello, Pylons!'
```
然后,创建一个模板文件`index.mako`在`templates`目录下,并添加以下代码:
```html
<!DOCTYPE html>
<html>
<head>
<title>Welcome to Pylons</title>
</head>
<body>
<h1>${message}</h1>
</body>
</html>
```
在`config.ini`中添加一个路由映射:
```ini
[routes]
root = /
```
重新启动Pylons服务器,然后访问`***`,你应该能看到消息“Hello, Pylons!”。
### 总结
在本章节中,我们介绍了Pylons环境的搭建、项目结构的解析以及项目的初始化。通过这一系列步骤,你应该能够成功搭建一个Pylons项目环境,并运行你的第一个Pylons应用程序。这些步骤为你进一步学习Pylons框架的核心组件打下了坚实的基础。
# 3. 构建Web应用的核心组件
## 3.1 模型(Model)设计
### 3.1.1 数据库模型建立
在构建Web应用的核心组件中,模型(Model)设计是基础。它负责定义应用中的数据结构,并与数据库进行交互。在Pylons框架中,我们通常使用SQLAlchemy作为对象关系映射(ORM)工具,它提供了一个高级的抽象层,让我们可以像操作Python对象一样操作数据库记录。
首先,我们需要定义我们的数据模型。例如,如果我们正在构建一个博客应用,我们可能需要一个`Post`模型来表示博客文章。
```python
# models.py
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Post(Base):
__tablename__ = 'posts'
id = Column(Integer, primary_key=True)
title = Column(String)
body = Column(String)
author_id = Column(Integer, ForeignKey('authors.id'))
author = relationship('Author', backref='posts')
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
name = Column(String)
```
在这个例子中,我们定义了两个模型:`Post`和`Author`。每个模型都有一系列的字段,这些字段映射到数据库表的列。
### 3.1.2 ORM映射与数据库交互
一旦我们定义了模型,我们需要将它们映射到数据库中的表。Pylons框架使用SQLAlchemy ORM来完成这个任务。以下是如何创建数据库会话和映射到数据库的示例代码:
```python
# model_setup.py
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from models import Base, Post, Author
engine = create_engine('sqlite:///mydatabase.db')
Session = sessionmaker(bind=engine)
session = Session()
Base.metadata.create_all(engine)
```
在上述代码中,我们首先创建了一个`create_engine`实例,它配置了数据库引擎,指定了数据库的类型和位置。然后,我们创建了一个会话类`Session`,用于与数据库进行交互。最后,我们调用`Base.metadata.create_all(engine)`来创建所有表。
接下来,我们可以使用session对象来添加、查询和更新数据库记录:
```python
# 示例代码,用于操作数据库
author = Author(name='John Doe')
session.add(author)
***mit()
post = Post(title='My First Post', body='This is my first post!', author=author)
session.add(post)
***mit()
```
在这个例子中,我们首先创建了一个`Author`对象并提交到数据库。然后,我们创建了一个`Post`对象,将其与`Author`关联,并提交到数据库。
通过本章节的介绍,我们了解了在Pylons框架中如何建立数据库模型和使用ORM进行数据库交互。下一节我们将深入探讨视图(View)开发,这是Web应用中负责渲染和呈现数据的部分。
## 3.2 视图(View)开发
### 3.2.1 模板引擎使用
在Pylons框架中,视图的主要职责是从模型中获取数据并将其呈现给用户。为了实现这一点,我们通常会使用模板引擎。Pylons支持多种模板引擎,如Mako和Jinja2,这里我们以Mako为例。
首先,我们需要在Pylons应用的配置文件中配置模板引擎。这通常在`ini`文件中完成:
```ini
# app.ini
[app:main]
use = egg:MyApp
pylons'app_globals' = pylons.get_app_globals()
pylons'template_engine' = mako
```
在上述配置中,我们指定了使用Mako作为模板引擎。接下来,我们可以在控制器中返回模板文件:
```python
# controllers/home.py
from pylons import controller
from pylons import request, response
from pylons import session
from pylons.controllers import WSGIController
from pylons.templating import render_mako
class HomeController(WSGIController):
def index(self):
return render_mako('home/index.mako', {'name': 'World'})
```
在这个例子中,`render_mako`函数用于渲染`home/index.mako`模板,并传递一个包含变量的字典。
### 3.2.2 动态页面渲染技术
动态页面渲染是Web开发中的核心概念。在Pylons框架中,我们可以使用模板引擎来动态生成HTML页面。这里我们将详细介绍如何使用Mako模板引擎来渲染动态内容。
首先,我们创建一个Mako模板文件`home/index.mako`:
```html
<!-- templates/home/index.mako -->
<!DOCTYPE html>
<html>
<head>
<title>Hello World</title>
</head>
<body>
<h1>Hello ${name}!</h1>
</body>
</html>
```
在Mako模板中,我们可以使用`${variable}`语法来插入Python变量。模板文件被保存在`templates`目录中,这是Pylons框架约定的模板存放位置。
当我们在控制器中调用`render_mako`函数时,Pylons会解析模板文件,并将传入的变量替换到模板中相应的位置。以下是渲染过程的简化示意图:
```mermaid
graph LR
A[控制器] -->|传入变量| B[渲染函数]
B --> C[模板文件]
C -->|替换变量| D[生成的HTML]
```
通过本章节的介绍,我们了解了在Pylons框架中如何使用模板引擎进行动态页面渲染。下一节我们将探讨控制器(Controller)逻辑的编写,这是处理用户请求的核心部分。
## 3.3 控制器(Controller)逻辑
### 3.3.1 请求处理流程
在Pylons框架中,控制器负责处理用户请求,并调用模型获取数据,然后选择视图来渲染响应。在这一小节中,我们将深入了解请求处理流程。
首先,当一个HTTP请求到达Pylons应用时,Pylons的路由系统会根据URL模式将请求路由到相应的控制器和动作。以下是一个简单的路由配置示例:
```python
# config/routing.py
from pylons import config
from routes import Request
def make_map():
map = Request.map()
map.connect('home', '/', controller='home', action='index')
return map
```
在这个例子中,我们使用`routes`库来定义一个路由映射,它将根URL`'/'`映射到`home`控制器的`index`动作。
接下来,当请求被路由到控制器时,Pylons会创建控制器的实例,并调用相应的方法。以下是`HomeController`控制器的示例:
```python
# controllers/home.py
from pylons import controller
from pylons import request, response
from pylons.controllers import WSGIController
class HomeController(WSGIController):
def index(self):
return 'Hello World!'
```
在这个例子中,当请求到达根URL时,`index`方法会被调用,并返回一个字符串`'Hello World!'`。
### 3.3.2 控制器逻辑编写
控制器的逻辑编写涉及到接收请求参数、调用模型和选择视图来生成响应。以下是如何在控制器中处理这些步骤的详细示例:
```python
# controllers/home.py
from pylons import controller
from pylons import request, response
from pylons.controllers import WSGIController
from pylons.templating import render_mako
from myapp.model import Post
class HomeController(WSGIController):
def index(self):
posts = request.db.query(Post).all()
return render_mako('home/index.mako', {'posts': posts})
```
在这个例子中,我们首先从数据库中查询所有的`Post`对象,然后将查询结果传递给视图模板。
通过本章节的介绍,我们了解了在Pylons框架中如何设计模型、开发视图和编写控制器逻辑。这些核心组件共同构成了一个Web应用的基础。接下来,我们将深入探讨如何实现Web应用的高级功能,例如表单处理、用户认证和RESTful API开发。
# 4. Web应用的高级功能实现
## 4.1 表单处理和验证
### 4.1.1 表单创建与提交处理
在Web应用中,表单是与用户交互的基本元素之一。它们用于收集用户输入的数据,然后在服务器端进行处理。Pylons框架提供了灵活的方式来创建和处理表单。以下是创建和处理表单的基本步骤:
1. **创建表单**:首先,我们需要在控制器中创建一个表单对象。Pylons使用` deform `库来创建表单,它允许我们以面向对象的方式定义表单字段和验证。
```python
from deform import Form, ValidationFailure
from deform.widget import TextInputWidget
from pylons.controllers.util import render
from myapp.model import MyModel
def my_view():
schema = {
'name': TextInputWidget(),
'email': TextInputWidget(),
}
form = Form(schema, buttons=('Submit',))
# 表单渲染逻辑
return render('/my_template.mako', form=form)
```
2. **表单渲染**:在Mako模板中,我们可以渲染表单,并提供一个提交按钮。
```html
<%page args="form"/>
<form method="post" action="/submit">
${form.render()}
<input type="submit" value="Submit"/>
</form>
```
3. **处理表单提交**:在控制器中,我们需要定义一个处理表单提交的方法。当用户提交表单时,服务器将处理输入数据。
```python
def submit_view():
request = c.request
if request.method == 'POST':
controls = request.POST.items()
try:
# 解析表单数据
values = form.validate(controls)
# 处理验证通过的数据
# ...
flash("Form submitted successfully")
return redirect('/success')
except ValidationFailure as e:
# 处理表单验证错误
flash("There were errors in the form")
return render('/my_template.mako', form=e.render())
return redirect('/my_view')
```
在上述代码中,我们首先定义了一个表单模式,然后在模板中渲染它,并在控制器中处理表单提交。如果表单验证失败,我们捕获` ValidationFailure `异常,并将错误信息返回给用户。如果验证成功,我们可以处理数据并执行相应的逻辑。
### 4.1.2 数据验证与错误处理
数据验证是确保Web应用安全性和健壮性的重要环节。在Pylons中,我们可以使用` deform `库提供的验证器来对表单数据进行验证。以下是一些常见的验证器及其用法:
1. **必填字段**:使用` NotEmpty `验证器确保字段不为空。
```python
from deform import ValidationFailure, Validator
from deform.validator import NotEmpty
class MySchema(colander.Schema):
name = colander.SchemaNode(colander.String(), validator=NotEmpty())
email = colander.SchemaNode(colander.String(), validator=NotEmpty())
```
2. **电子邮件验证**:使用` Email `验证器确保字段格式正确。
```python
from deform.validator import Email
class MySchema(colander.Schema):
email = colander.SchemaNode(colander.String(), validator=Email())
```
3. **自定义验证器**:创建自定义验证器来检查特定条件。
```python
from colander import ValidationFailure
class MyValidator(Validator):
def __init__(self, min_length):
self.min_length = min_length
def __call__(self, node, value):
if len(value) < self.min_length:
raise ValidationFailure(node, 'Value must be at least {} characters'.format(self.min_length))
class MySchema(colander.Schema):
password = colander.SchemaNode(colander.String(), validator=MyValidator(6))
```
在处理表单提交时,如果发生验证错误,我们将捕获` ValidationFailure `异常,并将错误信息返回给用户。这样,用户可以看到哪些字段出现了问题,并进行相应的更正。
## 4.2 用户认证和授权
### 4.2.1 用户登录与会话管理
用户认证是Web应用中的一个核心功能,它允许用户登录并保持身份验证状态。Pylons提供了内置的用户认证支持,我们可以使用` pylons.auth `模块来实现用户登录和会话管理。
#### 用户登录
1. **登录表单**:创建一个登录表单,用户可以输入用户名和密码。
```python
from pylons.controllers.util import render
from pylons.i18n import _, lazy_gettext as _
from pylons import request, response
def login_view():
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('password')
# 验证用户名和密码
# ...
# 登录成功
session = request.environ['beaker.session']
session['user_id'] = user_id
response.status = 303
response.headers['Location'] = '/home'
return render('/login.mako')
```
2. **配置认证方法**:在` config.ini `文件中配置认证方法。
```ini
[app:main]
# 认证方法
pylons认证 = password
```
#### 会话管理
1. **保持用户状态**:在用户登录后,我们可以使用会话来保持用户状态。
```python
session = request.environ['beaker.session']
session['user_id'] = user_id
```
2. **用户登出**:提供用户登出功能。
```python
def logout_view():
session = request.environ['beaker.session']
session.invalidate()
response.status = 303
response.headers['Location'] = '/login'
```
### 4.2.2 权限控制和安全策略
在用户登录后,我们需要实现权限控制来保护应用的敏感部分。Pylons提供了灵活的权限控制机制,允许我们定义不同的权限级别,并根据用户的登录状态来限制访问。
#### 权限定义
1. **定义权限**:定义不同的权限级别。
```python
class Permissions:
USER = 'user'
ADMIN = 'admin'
```
2. **角色与权限关联**:将权限分配给不同的用户角色。
```python
class Roles:
USER = 'user'
ADMIN = 'admin'
```
#### 权限检查
1. **检查权限**:在控制器中检查用户权限。
```python
def home_view():
# 获取用户ID
user_id = request.environ['beaker.session']['user_id']
# 获取用户角色
user_role = get_user_role(user_id)
# 检查用户是否有访问权限
if not has_permission(user_id, Permissions.HOME):
flash("You do not have access to this page")
return redirect('/login')
# 渲染页面
return render('/home.mako')
```
在上述代码中,我们首先获取用户的ID和角色,然后检查用户是否有访问特定页面的权限。如果没有权限,我们将用户重定向到登录页面。
## 4.3 RESTful API开发
### 4.3.1 REST原则和设计
REST(Representational State Transfer)是一种软件架构风格,它定义了一组约束条件和原则。在Pylons中,我们可以使用` restfulweb `库来创建RESTful API。RESTful API是一种基于HTTP协议,使用不同的HTTP方法(如GET、POST、PUT、DELETE)来处理资源的Web服务。
#### REST原则
1. **无状态**:客户端的请求和服务器的响应应该是无状态的。
2. **客户端-服务器分离**:客户端和服务器应该独立开发。
3. **可缓存**:响应应该是可缓存的。
4. **统一接口**:使用统一的接口与资源进行交互。
#### 设计RESTful API
1. **资源命名**:资源应该使用名词,并且是可数的。
```plaintext
GET /users - 获取用户列表
POST /users - 创建新用户
GET /users/{id} - 获取指定ID的用户
PUT /users/{id} - 更新指定ID的用户
DELETE /users/{id} - 删除指定ID的用户
```
2. **HTTP方法使用**:根据资源操作选择合适的HTTP方法。
```plaintext
GET /users - 使用GET方法获取数据
POST /users - 使用POST方法创建数据
```
### 4.3.2 API视图和路由配置
在Pylons中,我们可以定义API视图,并将它们与路由进行映射。以下是如何定义一个简单的RESTful API视图,并配置路由的示例。
#### 定义API视图
1. **创建资源控制器**:创建一个资源控制器类。
```python
from pylons.controllers.util import render
from pylons import request, response
from myapp.model import User
from myapp.lib.base import Controller
class UsersController(Controller):
def get(self, id=None):
if id:
# 获取指定ID的用户
user = User.get_by_id(id)
return render('/user.mako', user=user)
else:
# 获取用户列表
users = User.all()
return render('/users.mako', users=users)
def post(self):
# 创建新用户
data = request.json
user = User(**data)
user.save()
return response.status = 201
def put(self, id):
# 更新指定ID的用户
data = request.json
user = User.get_by_id(id)
if user:
user.update(data)
return response.status = 200
else:
return response.status = 404
def delete(self, id):
# 删除指定ID的用户
user = User.get_by_id(id)
if user:
user.delete()
return response.status = 204
else:
return response.status = 404
```
#### 配置路由
1. **配置路由**:在` config/routing.py `文件中配置API路由。
```python
from pylons.urls import controller_scan
map.resource('users', 'users_controller', controller_scan('myapp.controllers.api'))
```
在上述代码中,我们首先在` controller_scan `方法中扫描了API控制器,然后使用` map.resource `方法配置了资源路由。
通过本章节的介绍,我们了解了如何在Pylons框架中实现表单处理和验证、用户认证和授权以及RESTful API开发。这些高级功能对于构建现代Web应用至关重要。在本章节中,我们详细探讨了每个功能的实现步骤和最佳实践,包括使用` deform `库创建和处理表单、使用` pylons.auth `模块管理用户认证和会话以及设计和配置RESTful API。通过这些知识,开发者可以更有效地构建功能丰富、安全可靠的Web应用。
# 5. Web应用的优化与部署
在本章中,我们将探讨如何优化和部署基于Pylons框架的Web应用,确保其性能卓越且易于维护。我们将从性能优化开始,然后讨论测试与维护,最后介绍部署与持续集成的相关实践。
## 5.1 性能优化
性能优化是确保Web应用快速响应的关键步骤。我们将从代码层面的优化开始,然后讨论服务器和中间件的优化策略。
### 5.1.1 代码层面优化
代码层面的优化涉及到减少不必要的计算、优化算法和数据结构、以及减少数据库查询次数等方面。
例如,我们可以使用Pylons内置的缓存机制来存储经常请求的页面或数据:
```python
from pylons import cache
@get('/frequently_asked_questions')
def indexFAQ():
# 使用缓存来存储FAQ页面
faq_page = cache.get('faq_page')
if faq_page is None:
faq_page = render('/faq.mako')
cache.set('faq_page', faq_page, duration=3600) # 缓存1小时
return faq_page
```
在这个例子中,我们使用了Pylons的`cache`模块来缓存FAQ页面,这样可以减少对数据库的查询次数,提高页面加载速度。
### 5.1.2 服务器和中间件优化
服务器和中间件的优化包括配置Web服务器(如Nginx或Apache)来处理静态文件、使用负载均衡器分散流量,以及使用专业的中间件来加速应用。
例如,我们可以配置Nginx来处理静态文件,减少Pylons服务器的压力:
```nginx
server {
listen 80;
server_***;
location / {
proxy_pass ***
}
location /static/ {
root /path/to/app/static;
expires 30d;
}
}
```
在这个Nginx配置中,我们将静态文件的请求直接通过Nginx处理,而不经过Pylons服务器。
## 5.2 测试与维护
测试是确保Web应用质量的关键环节,包括单元测试、集成测试、应用维护和监控。
### 5.2.* 单元测试和集成测试
单元测试和集成测试可以使用Python的`unittest`模块或`pytest`来完成。这些测试可以帮助我们确保代码的各个部分都能正常工作。
例如,我们可以在Pylons应用中创建一个简单的单元测试:
```python
import unittest
from myapp.model import User
class UserModelTest(unittest.TestCase):
def test_user_creation(self):
new_user = User(username='testuser', password='testpass')
self.assertEqual(new_user.username, 'testuser')
self.assertTrue(new_user.password != 'testpass') # 假设密码是加密的
if __name__ == '__main__':
unittest.main()
```
在这个单元测试中,我们创建了一个`UserModelTest`类来测试用户模型的创建。
### 5.2.2 应用维护和监控
应用维护和监控是确保Web应用长期稳定运行的重要工作。我们可以使用如`New Relic`或`Sentry`等工具来监控应用的性能和错误。
例如,我们可以使用`Sentry`来捕获应用中的异常并通知开发者:
```python
import sentry_sdk
def initialize_sentry():
sentry_sdk.init(
dsn="***<key>@sentry.io/<project>",
traces_sample_rate=1.0
)
initialize_sentry()
```
在这个例子中,我们使用`Sentry`的Python SDK初始化了错误跟踪功能。
## 5.3 部署与持续集成
部署和持续集成是将Web应用从开发环境迁移到生产环境的过程,并确保持续集成和部署的自动化。
### 5.3.1 应用部署流程
应用部署通常涉及将代码推送到服务器、安装依赖、配置服务器等步骤。我们可以使用如`Ansible`或`Fabric`等工具来自动化这些过程。
例如,我们可以使用`Fabric`来自动化部署流程:
```python
from fabric.api import env, run, local
env.hosts = ['***']
env.user = 'username'
def deploy():
local('git pull') # 从版本控制系统拉取最新代码
run('pip install -r requirements.txt') # 安装依赖
run('python setup.py install') # 安装应用
deploy()
```
在这个`Fabric`脚本中,我们定义了一个`deploy`函数来自动化部署流程。
### 5.3.2 持续集成工具和实践
持续集成(CI)工具可以帮助我们在代码提交时自动运行测试和部署流程。常用的CI工具有`Jenkins`、`Travis CI`和`GitLab CI`。
例如,我们可以使用`Travis CI`来自动运行测试:
```yaml
language: python
python:
- "3.8"
script:
- python -m unittest discover
```
在这个`Travis CI`的配置文件中,我们指定了Python版本,并定义了运行测试的脚本。
通过以上步骤,我们可以确保Pylons Web应用的性能优化、测试与维护,以及部署与持续集成的有效实施。这些实践将帮助我们构建健壮、高效的应用程序,并确保长期的可维护性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 Python 库文件 pylons.middleware 为主题,深入解析了其在 Web 应用性能优化、安全加固、测试策略、日志管理、扩展开发、认证授权、事务管理、会话管理、错误处理、路由机制和模板渲染等方面的应用。通过 10 分钟快速掌握的秘籍、深入剖析的工作原理、揭秘的高效工作流程、提升性能的策略、保护 Web 应用免受攻击的步骤、确保代码质量与稳定性的技巧、提升运维效率的记录和分析请求数据的方法、提升应用个性化体验的自定义中间件开发、保护敏感数据的策略、确保数据一致性的关键步骤、处理用户状态的技巧、优雅管理异常提升用户满意度的技巧、深入理解 URL 解析构建高效路由的知识和提高页面生成速度的技巧,全面提升 Python Web 开发效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【数据分片技术】:实现在线音乐系统数据库的负载均衡
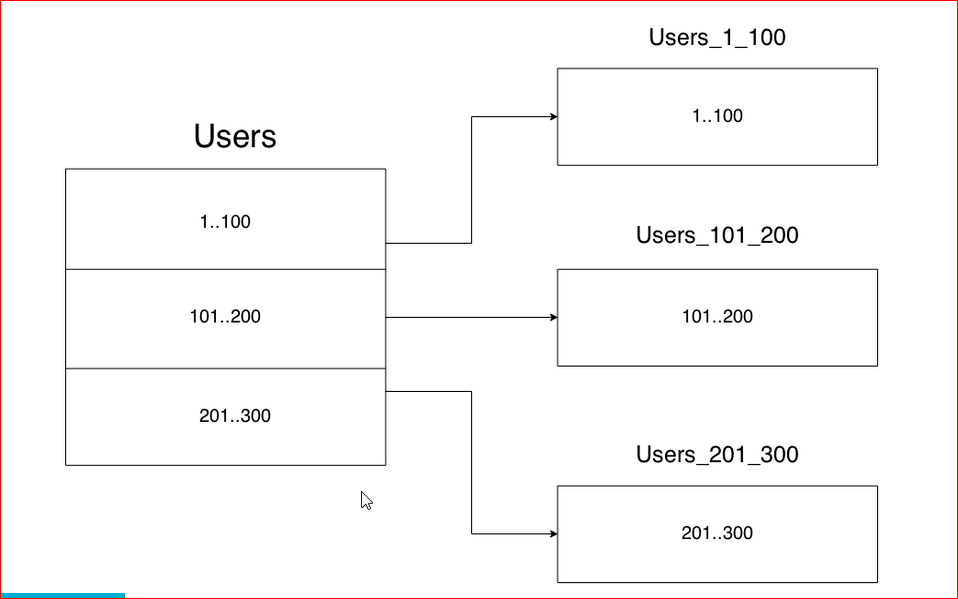
# 1. 数据分片技术概述
## 1.1 数据分片技术的作用
数据分片技术在现代IT架构中扮演着至关重要的角色。它将大型数据库或数据集切分为更小、更易于管理和访问的部分,这些部分被称为“分片”。分片可以优化性能,提高系统的可扩展性和稳定性,同时也是实现负载均衡和高可用性的关键手段。
## 1.2 数据分片的多样性与适用场景
数据分片的策略多种多样,常见的包括垂直分片和水平分片。垂直分片将数据
微信小程序登录后端日志分析与监控:Python管理指南
# 1. 微信小程序后端日志管理基础
## 1.1 日志管理的重要性
日志记录是软件开发和系统维护不可或缺的部分,它能帮助开发者了解软件运行状态,快速定位问题,优化性能,同时对于安全问题的追踪也至关重要。微信小程序后端的日志管理,虽然在功能和规模上可能不如大型企业应用复杂,但它在保障小程序稳定运行和用户体验方面发挥着基石作用。
## 1.2 微
Java中JsonPath与Jackson的混合使用技巧:无缝数据转换与处理

# 1. JSON数据处理概述
JSON(JavaScript Object Notation)数据格式因其轻量级、易于阅读和编写、跨平台特性等优点,成为了现代网络通信中数据交换的首选格式。作为开发者,理解和掌握JSON数
【大数据处理利器】:MySQL分区表使用技巧与实践
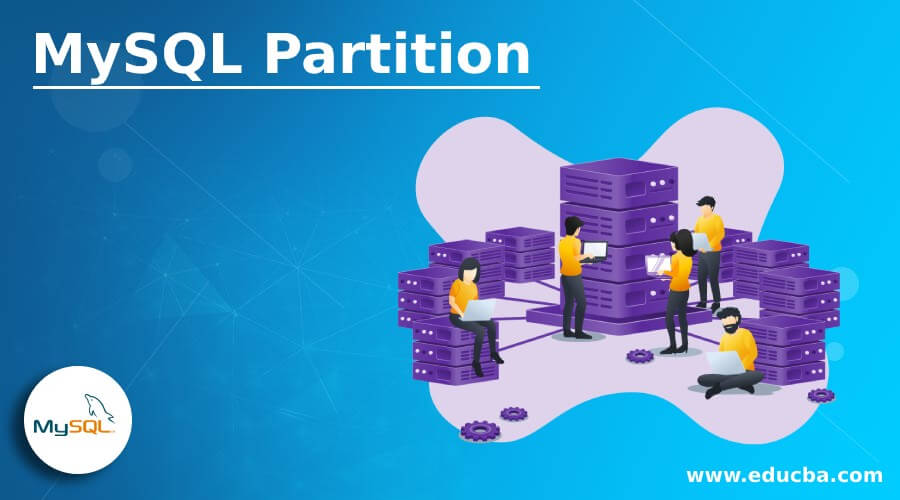
# 1. MySQL分区表概述与优势
## 1.1 MySQL分区表简介
MySQL分区表是一种优化存储和管理大型数据集的技术,它允许将表的不同行存储在不同的物理分区中。这不仅可以提高查询性能,还能更有效地管理数据和提升数据库维护的便捷性。
## 1.2 分区表的主要优势
分区表的优势主要体现在以下几个方面:
- **查询性能提升**:通过分区,可以减少查询时需要扫描的数据量
【数据集不平衡处理法】:解决YOLO抽烟数据集类别不均衡问题的有效方法

# 1. 数据集不平衡现象及其影响
在机器学习中,数据集的平衡性是影响模型性能的关键因素之一。不平衡数据集指的是在分类问题中,不同类别的样本数量差异显著,这会导致分类器对多数类的偏好,从而忽视少数类。
## 数据集不平衡的影响
不平衡现象会使得模型在评估指标上产生偏差,如准确率可能很高,但实际上模型并未有效识别少数类样本。这种偏差对许多应
绿色计算与节能技术:计算机组成原理中的能耗管理
# 1. 绿色计算与节能技术概述
随着全球气候变化和能源危机的日益严峻,绿色计算作为一种旨在减少计算设备和系统对环境影响的技术,已经成为IT行业的研究热点。绿色计算关注的是优化计算系统的能源使用效率,降低碳足迹,同时也涉及减少资源消耗和有害物质的排放。它不仅仅关注硬件的能耗管理,也包括软件优化、系统设计等多个方面。本章将对绿色计算与节能技术的基本概念、目标及重要性进行概述
【数据库连接池管理】:高级指针技巧,优化数据库操作

# 1. 数据库连接池的概念与优势
数据库连接池是管理数据库连接复用的资源池,通过维护一定数量的数据库连接,以减少数据库连接的创建和销毁带来的性能开销。连接池的引入,不仅提高了数据库访问的效率,还降低了系统的资源消耗,尤其在高并发场景下,连接池的存在使得数据库能够更加稳定和高效地处理大量请求。对于IT行业专业人士来说,理解连接池的工作机制和优势,能够帮助他们设计出更加健壮的应用架构。
# 2. 数据库连
面向对象编程与函数式编程:探索编程范式的融合之道

# 1. 面向对象编程与函数式编程概念解析
## 1.1 面向对象编程(OOP)基础
面向对象编程是一种编程范式,它使用对象(对象是类的实例)来设计软件应用。
【用户体验设计】:创建易于理解的Java API文档指南
# 1. Java API文档的重要性与作用
## 1.1 API文档的定义及其在开发中的角色
Java API文档是软件开发生命周期中的核心部分,它详细记录了类库、接口、方法、属性等元素的用途、行为和使用方式。文档作为开发者之间的“沟通桥梁”,确保了代码的可维护性和可重用性。
## 1.2 文档对于提高代码质量的重要性
良好的文档
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )