树莓派OpenCV摄像头图像处理:从小白到专家的进阶指南
发布时间: 2024-08-06 11:16:05 阅读量: 54 订阅数: 24 

树莓派 opencv c++ 实时读取图像和处理

# 1. 树莓派OpenCV入门
OpenCV(Open Source Computer Vision Library)是一个开源计算机视觉库,广泛用于图像处理、计算机视觉和机器学习等领域。本指南将介绍如何在树莓派上安装和使用OpenCV,为初学者提供一个入门指南。
### 1.1 安装OpenCV
在树莓派上安装OpenCV有两种主要方法:
- **使用apt-get命令:**
```
sudo apt-get update
sudo apt-get install libopencv-dev
```
- **使用pip命令:**
```
sudo pip install opencv-python
```
### 1.2 导入OpenCV
安装完成后,可以在Python脚本中导入OpenCV:
```python
import cv2
```
# 2. OpenCV图像处理基础
### 2.1 图像读取、显示和保存
#### 图像读取
OpenCV提供了`cv2.imread()`函数读取图像文件,该函数接受两个参数:
- `filename`: 图像文件的路径
- `flags`: 读取标志,用于指定图像的读取方式,常见标志有:
- `cv2.IMREAD_COLOR`: 读取彩色图像
- `cv2.IMREAD_GRAYSCALE`: 读取灰度图像
- `cv2.IMREAD_UNCHANGED`: 读取图像而不进行任何转换
#### 代码示例
```python
import cv2
# 读取彩色图像
image = cv2.imread('image.jpg', cv2.IMREAD_COLOR)
# 读取灰度图像
gray_image = cv2.imread('image.jpg', cv2.IMREAD_GRAYSCALE)
```
#### 图像显示
OpenCV提供了`cv2.imshow()`函数显示图像,该函数接受两个参数:
- `window_name`: 图像窗口的名称
- `image`: 要显示的图像
#### 代码示例
```python
cv2.imshow('Image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
#### 图像保存
OpenCV提供了`cv2.imwrite()`函数保存图像文件,该函数接受两个参数:
- `filename`: 图像文件的路径
- `image`: 要保存的图像
#### 代码示例
```python
cv2.imwrite('new_image.jpg', image)
```
### 2.2 图像格式和转换
#### 图像格式
OpenCV支持多种图像格式,包括:
- JPEG
- PNG
- BMP
- TIFF
#### 图像转换
OpenCV提供了`cv2.cvtColor()`函数转换图像格式,该函数接受两个参数:
- `image`: 要转换的图像
- `code`: 转换代码,指定要转换到的格式
#### 代码示例
```python
# 将彩色图像转换为灰度图像
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 将灰度图像转换为彩色图像
color_image = cv2.cvtColor(gray_image, cv2.COLOR_GRAY2BGR)
```
### 2.3 图像增强和预处理
#### 图像增强
图像增强技术用于改善图像的视觉质量,包括:
- 对比度增强
- 亮度调整
- 锐化
#### 代码示例
```python
# 调整图像对比度
contrasted_image = cv2.convertScaleAbs(image, alpha=1.5, beta=0)
# 调整图像亮度
brightened_image = cv2.add(image, np.array([50]))
# 锐化图像
sharpened_image = cv2.filter2D(image, -1, np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]]))
```
#### 图像预处理
图像预处理技术用于将图像转换为适合特定任务的格式,包括:
- 调整大小
- 裁剪
- 旋转
#### 代码示例
```python
# 调整图像大小
resized_image = cv2.resize(image, (500, 500))
# 裁剪图像
cropped_image = image[100:200, 100:200]
# 旋转图像
rotated_image = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
```
# 3.1 图像分割和轮廓检测
**图像分割**
图像分割是将图像分解为多个独立的区域或对象的进程,每个区域或对象具有相似的特征。在 OpenCV 中,图像分割可以通过多种方法实现,包括:
* **阈值化:**将图像中的像素值二值化,将高于或低于特定阈值的像素分别标记为前景或背景。
* **区域生长:**从种子点开始,逐步将具有相似特征的像素分组到一个区域。
* **边缘检测:**检测图像中像素值的突然变化,从而识别物体边界。
**轮廓检测**
轮廓检测是识别图像中物体边缘的过程。OpenCV 提供了多种轮廓检测算法,包括:
* **Canny 边缘检测:**使用多级边缘检测算法,通过抑制噪声和细化边缘来检测边缘。
* **Sobel 边缘检测:**使用卷积核来检测图像中像素值的一阶导数,从而识别边缘。
* **Laplacian 边缘检测:**使用卷积核来检测图像中像素值二阶导数,从而识别边缘。
**应用**
图像分割和轮廓检测在各种应用中都有广泛的应用,例如:
* **物体检测:**通过分割图像并检测轮廓,可以识别和定位图像中的物体。
* **图像分析:**通过分割图像并分析轮廓,可以提取图像中物体的形状、大小和纹理等特征。
* **医学成像:**通过分割医学图像并检测轮廓,可以识别和诊断疾病。
**代码示例**
以下代码示例演示了如何使用 OpenCV 进行图像分割和轮廓检测:
```python
import cv2
import numpy as np
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 阈值化图像
thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)[1]
# 查找轮廓
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 绘制轮廓
cv2.drawContours(image, contours, -1, (0, 255, 0), 2)
# 显示图像
cv2.imshow('Image', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**逻辑分析**
* `cv2.cvtColor()` 将图像转换为灰度图像。
* `cv2.threshold()` 使用阈值 127 将图像二值化。
* `cv2.findContours()` 查找图像中的轮廓。
* `cv2.drawContours()` 在图像上绘制轮廓。
**参数说明**
* `cv2.threshold()`:
* `thresh`:输出二值化图像。
* `127`:阈值。
* `255`:前景像素值。
* `cv2.THRESH_BINARY`:阈值化类型。
* `cv2.findContours()`:
* `contours`:输出轮廓列表。
* `hierarchy`:输出轮廓层次结构。
* `cv2.RETR_EXTERNAL`:检索外部轮廓。
* `cv2.CHAIN_APPROX_SIMPLE`:使用简单近似方法。
* `cv2.drawContours()`:
* `image`:输入图像。
* `contours`:轮廓列表。
* `-1`:绘制所有轮廓。
* `(0, 255, 0)`:轮廓颜色(绿色)。
* `2`:轮廓粗细。
# 4.1 图像增强算法
图像增强算法旨在改善图像的视觉效果,使其更适合特定应用。OpenCV 提供了多种图像增强算法,包括:
### 直方图均衡化
直方图均衡化是一种图像增强技术,通过调整图像的像素值分布来改善图像的对比度和亮度。它通过将图像的直方图拉伸到整个灰度范围来实现,从而使图像中所有灰度值都具有相同的频率。
```python
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 进行直方图均衡化
equ = cv2.equalizeHist(image)
# 显示原始图像和均衡化后的图像
cv2.imshow('Original Image', image)
cv2.imshow('Equalized Image', equ)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**参数说明:**
* `image`: 输入图像。
**逻辑分析:**
* `cv2.equalizeHist()` 函数将图像的直方图拉伸到整个灰度范围,从而改善图像的对比度和亮度。
### 对比度拉伸
对比度拉伸是一种图像增强技术,通过调整图像的最小和最大像素值来增强图像的对比度。它通过将图像的像素值映射到新的灰度范围来实现,从而扩大图像中像素值之间的差异。
```python
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 进行对比度拉伸
contrast = cv2.convertScaleAbs(image, alpha=1.5, beta=0)
# 显示原始图像和对比度拉伸后的图像
cv2.imshow('Original Image', image)
cv2.imshow('Contrast Stretched Image', contrast)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**参数说明:**
* `image`: 输入图像。
* `alpha`: 对比度增强因子。
* `beta`: 亮度调整因子。
**逻辑分析:**
* `cv2.convertScaleAbs()` 函数将图像的像素值映射到新的灰度范围,从而扩大图像中像素值之间的差异。
* `alpha` 参数控制对比度增强,值越大,对比度增强越明显。
* `beta` 参数控制亮度调整,值越大,图像越亮。
### 模糊滤波
模糊滤波是一种图像增强技术,通过对图像进行卷积操作来平滑图像,消除图像中的噪声和细节。OpenCV 提供了多种模糊滤波器,包括:
* 均值滤波:计算图像中指定邻域内所有像素的平均值,并将其作为中心像素的新值。
* 高斯滤波:使用高斯核对图像进行卷积,产生平滑的模糊效果。
* 中值滤波:计算图像中指定邻域内所有像素的中值,并将其作为中心像素的新值。
```python
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 进行均值滤波
blur = cv2.blur(image, (5, 5))
# 显示原始图像和均值滤波后的图像
cv2.imshow('Original Image', image)
cv2.imshow('Blurred Image', blur)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**参数说明:**
* `image`: 输入图像。
* `(5, 5)`: 卷积核的大小。
**逻辑分析:**
* `cv2.blur()` 函数对图像进行均值滤波,计算图像中指定邻域内所有像素的平均值,并将其作为中心像素的新值。
* 卷积核的大小控制模糊程度,卷积核越大,模糊效果越明显。
# 5.1 人脸检测和识别
### 人脸检测
人脸检测是计算机视觉中一项基本任务,它涉及识别图像中的人脸。OpenCV 提供了多种人脸检测算法,包括 Haar 级联分类器和深度学习模型。
#### Haar 级联分类器
Haar 级联分类器是一种基于特征的检测算法,它使用一系列 Haar 特征来识别图像中的人脸。Haar 特征是矩形区域,其像素值之和与相邻区域的像素值之和进行比较。
```python
import cv2
# 加载 Haar 级联分类器
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 读取图像
image = cv2.imread('image.jpg')
# 转换图像为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_cascade.detectMultiScale(gray, 1.1, 4)
# 绘制矩形框
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 显示图像
cv2.imshow('Faces', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
#### 深度学习模型
深度学习模型,例如 MobileNetSSD,可以实现更准确的人脸检测。这些模型使用卷积神经网络(CNN)从图像中提取特征,并使用这些特征来预测图像中是否存在人脸。
```python
import cv2
import numpy as np
# 加载深度学习模型
net = cv2.dnn.readNetFromCaffe('deploy.prototxt.txt', 'mobilenet_iter_73000.caffemodel')
# 读取图像
image = cv2.imread('image.jpg')
# 转换图像为 blob
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 0.007843, (300, 300), 127.5)
# 设置输入
net.setInput(blob)
# 预测人脸
detections = net.forward()
# 绘制矩形框
for i in np.arange(0, detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > 0.5:
x1 = int(detections[0, 0, i, 3] * image.shape[1])
y1 = int(detections[0, 0, i, 4] * image.shape[0])
x2 = int(detections[0, 0, i, 5] * image.shape[1])
y2 = int(detections[0, 0, i, 6] * image.shape[0])
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 显示图像
cv2.imshow('Faces', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
### 人脸识别
人脸识别是识别图像中特定个体的过程。OpenCV 提供了多种人脸识别算法,包括 EigenFaces、FisherFaces 和 Local Binary Patterns Histograms (LBPH)。
```python
import cv2
import numpy as np
# 加载人脸识别模型
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('face_model.yml')
# 读取图像
image = cv2.imread('image.jpg')
# 转换图像为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_cascade.detectMultiScale(gray, 1.1, 4)
# 识别人脸
for (x, y, w, h) in faces:
id, confidence = recognizer.predict(gray[y:y+h, x:x+w])
if confidence < 100:
name = 'Person ' + str(id)
else:
name = 'Unknown'
cv2.putText(image, name, (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 显示图像
cv2.imshow('Faces', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了树莓派 OpenCV 摄像头在各种领域的广泛应用,包括图像处理、人脸识别、图像分割、物体跟踪、深度学习、项目实战、医疗应用、教育应用和商业应用。通过提供实用技巧、进阶指南、权威解读和成功案例,本专栏旨在帮助读者充分利用树莓派 OpenCV 摄像头,打造智能视觉系统,并探索计算机视觉的无限可能。从小白到专家,从理论到实践,本专栏为读者提供了全面的指导,助力其在智能视觉领域取得成功。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Zkteco智慧多地点管理ZKTime5.0:集中控制与远程监控完全指南

# 摘要
本文对Zkteco智慧多地点管理系统ZKTime5.0进行了全面的介绍和分析。首先概述了ZKTime5.0的基本功能及其在智慧管理中的应用。接着,深入探讨了集中控制系统的理论基础,包括定义、功能、组成架构以及核心技术与优势。文章详细讨论了ZKTime5.0的远程监控功能,着重于其工作原理、用户交互设计及安全隐私保护。实践部署章节提供了部署前准备、系统安装配置
Java代码安全审查规则解析:深入local_policy.jar与US_export_policy.jar的安全策略

# 摘要
本文系统探讨了Java代码安全审查的全面方法与实践。首先介绍了Java安全策略文件的组成及其在不同版本间的差异,对权限声明进行了深入解析。接着,文章详细阐述了进行安全审查的工具和方法,分析了安全漏洞的审查实例,并讨论了审查报告的撰写和管理。文章深入理解Java代码安
数字逻辑深度解析:第五版课后习题的精华解读与应用

# 摘要
数字逻辑作为电子工程和计算机科学的基础,其研究涵盖了从基本概念到复杂电路设计的各个方面。本文首先回顾了数字逻辑的基础知识,然后深入探讨了逻辑门、逻辑表达式及其简化、验证方法。接着,文章详细分析了组合逻辑电路和时序逻辑电路的设计、分析、测试方法及其在电子系统中的应用。最后,文章指出了数字逻辑电路测试与故障诊断的重要性,并探讨了其在现代电子系统设计中的创新应用
【CEQW2监控与报警机制】:构建无懈可击的系统监控体系

# 摘要
监控与报警机制是确保信息系统的稳定运行与安全防护的关键技术。本文系统性地介绍了CEQW2监控与报警机制的理论基础、核心技术和应用实践。首先概述了监控与报警机制的基本概念和框架,接着详细探讨了系统监控的理论基础、常用技术与工具、数据收集与传输方法。随后,文章深入分析了报警机制的理论基础、操作实现和高级应用,探讨了自动化响应流程和系统性能优化。此外,本文还讨论了构建全面监控体系的架构设计、集成测试及维
电子组件应力筛选:IEC 61709推荐的有效方法

# 摘要
电子组件在生产过程中易受各种应力的影响,导致性能不稳定和早期失效。应力筛选作为一种有效的质量控制手段,能够在电子组件进入市场前发现潜在的缺陷。IEC 61709标准为应力筛选提供了理论框架和操作指南,促进了该技术在电子工业中的规范化应用。本文详细解读了IEC 61709标准,并探讨了应力筛选的理论基础和统计学方法。通过分析电子组件的寿命分
ARM处理器工作模式:剖析7种运行模式及其最佳应用场景

# 摘要
ARM处理器因其高性能和低功耗的特性,在移动和嵌入式设备领域得到广泛应用。本文首先介绍了ARM处理器的基本概念和工作模式基础,然后深入探讨了ARM的七种运行模式,包括状态切换、系统与用户模式、特权模式与异常模式的细节,并分析了它们的应用场景和最佳实践。随后,文章通过对中断处理、快速中断模式和异常处理模式的实践应用分析,阐述了在实时系统中的关键作用和设计考量。在高级应用部分,本文讨论了安全模式、信任Z
UX设计黄金法则:打造直觉式移动界面的三大核心策略

# 摘要
随着智能移动设备的普及,直觉式移动界面设计成为提升用户体验的关键。本文首先概述移动界面设计,随后深入探讨直觉式设计的理论基础,包括用户体验设计简史、核心设计原则及心理学应用。接着,本文提出打造直觉式移动界面的实践策略,涉及布局、导航、交互元素以及内容呈现的直觉化设计。通过案例分析,文中进一步探讨了直觉式交互设计的成功与失败案例,为设
海康二次开发进阶篇:高级功能实现与性能优化

# 摘要
随着安防监控技术的发展,海康设备二次开发在智能视频分析、AI应用集成及云功能等方面展现出越来越重要的作用。本文首先介绍了海康设备二次开发的基础知识,详细解析了海康SDK的架构、常用接口及集成示例。随后,本文深入探讨了高级功能的实现,包括实时视频分析技术、AI智能应用集成和云功能的
STM32F030C8T6终极指南:最小系统的构建、调试与高级应用
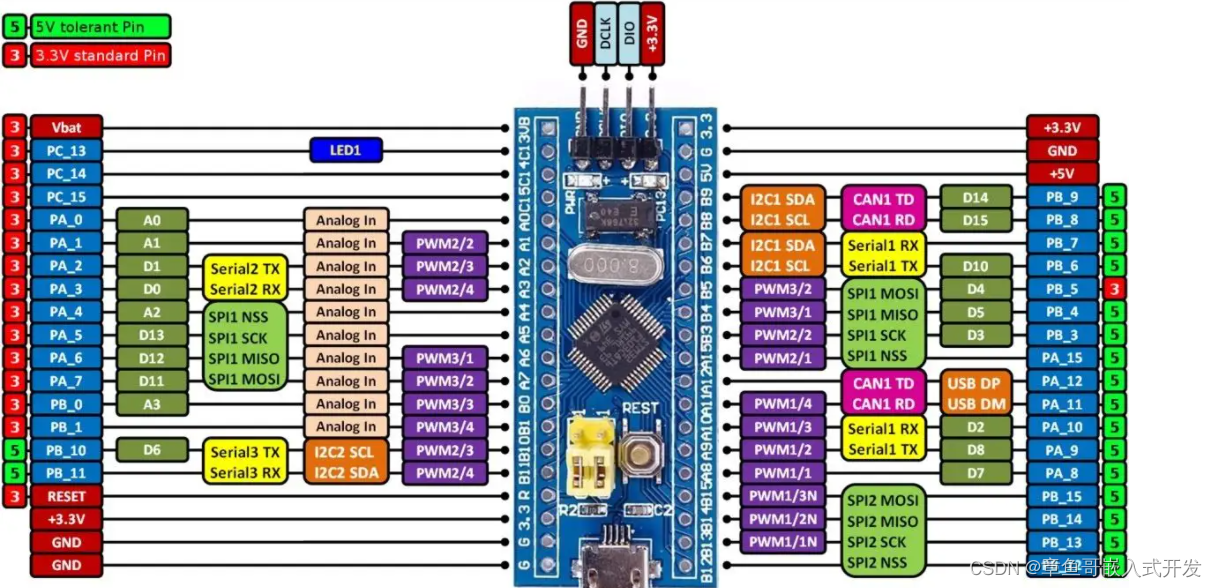
# 摘要
本论文全面介绍了STM32F030C8T6微控制器的关键特性和应用,从最小系统的构建到系统优化与未来展望。首先,文章概述了微控制器的基本概念,并详细讨论了构建最小系统所需的硬件组件选择、电源电路设计、调试接口配置,以及固件准备。随后,论文深入探讨了编程和调试的基础,包括开发环境的搭建、编程语言的选择和调试技巧。文章还深入分析了微控制器的高级特性,如外设接口应用、中断系统优化、能效
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )