容器编排:从Docker到Kubernetes
发布时间: 2024-01-22 07:54:32 阅读量: 40 订阅数: 27 

kubernetes-learning:《从Docker到Kubernetes进阶课程》在线文档
# 1. 介绍
容器编排是一种将容器化应用程序部署和管理的方法。在过去几年中,容器技术迅速发展并得到了广泛应用。Docker作为当前最流行的容器化解决方案,通过其简单易用的特性和高效的性能,已经成为了业界的标准。
### 1.1 Docker的背景和基本概念
Docker最早是由dotCloud公司开发的,旨在提供一个轻量级、快速构建和部署应用程序的解决方案。Docker利用操作系统级别的虚拟化技术,将应用程序及其依赖项打包到一个称为Docker镜像的容器中,然后可以在任何支持Docker的操作系统上运行这个容器。Docker的基本概念包括:
- 镜像(Image):镜像是一个轻量级、可执行的软件包,其中包含了运行应用程序所需的所有文件系统、库和依赖项。Docker镜像可以从Docker Hub或者自己构建得到。
- 容器(Container):容器是Docker镜像的运行实例,可以看作是一个隔离的进程运行环境。通过创建和管理容器,我们可以实现应用程序的快速部署和可靠运行。
- 仓库(Registry):仓库是存储和分享Docker镜像的地方。Docker Hub是一个公共的Docker镜像仓库,我们可以在其中找到许多常用的镜像。此外,我们还可以搭建私有的仓库来存储和分享自己的镜像。
### 1.2 为什么需要容器编排工具
随着容器数量的增加和规模的扩大,手动管理容器变得越来越复杂和困难。在传统的部署方式中,我们需要手动运行和管理每个容器,无法实现高效的自动化和资源的优化利用。因此,我们需要一种容器编排工具,可以帮助我们自动化地管理容器的创建、启动、停止、伸缩和升级等操作。
容器编排工具可以帮助我们实现以下目标:
- 提高部署效率:容器编排工具可以自动化地部署和管理容器,大大提高了部署效率,降低了操作复杂性。
- 资源优化利用:容器编排工具可以通过对容器进行动态调度和分配,实现资源的优化利用,提高整个集群的性能和容错能力。
- 扩展性和可伸缩性:容器编排工具可以根据负载情况动态伸缩容器,以应对流量的变化,保证应用程序的高可用性和可伸缩性。
- 故障恢复和容错性:容器编排工具可以自动监控和管理容器的状态,及时发现故障并进行恢复,提高了应用程序的容错性。
总之,容器编排工具可以帮助我们更好地管理和运行容器化应用程序,提高开发和运维效率,同时还可以提供更灵活、高效和可靠的应用交付方式。在众多的容器编排工具中,Kubernetes因其成熟的生态系统、广泛的用户基础和强大的功能而备受关注。接下来的章节中,我们将重点介绍Kubernetes的基础知识和使用方法。
# 2. Docker入门
Docker是一个开源的容器化平台,可以帮助开发人员和运维人员更轻松地构建、打包、部署和管理应用程序。它提供了一种轻量级的虚拟化技术,可以将应用程序和其依赖的资源打包在一个独立的容器中运行。本章将介绍如何安装和配置Docker,以及使用Docker镜像和容器进行基本操作。
### 2.1 Docker的安装和配置
Docker支持多个操作系统平台,包括Linux、Windows和macOS。以下是在Linux系统上安装Docker的步骤:
1. 首先,确保你的Linux系统满足Docker的安装要求,包括64位的操作系统、内核版本3.10以上等。
2. 打开终端,并执行以下命令来安装Docker的依赖组件:
```shell
sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates curl software-properties-common
```
3. 添加Docker的官方GPG密钥:
```shell
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
```
4. 添加Docker的软件仓库:
```shell
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
```
5. 再次执行更新命令,并安装Docker:
```shell
sudo apt-get update
sudo apt-get install docker-ce
```
6. 安装完成后,可以通过运行以下命令来验证Docker的安装结果:
```shell
docker version
```
在Windows和macOS上安装Docker的步骤与上述略有不同,具体可以参考Docker官方文档。
### 2.2 Docker镜像和容器的基本操作
在Docker中,镜像(Image)是构建容器的基础。一个镜像包含了一个完整的操作系统环境以及要运行的应用程序。以下是一些常用的Docker镜像操作命令:
- 搜索镜像:
```shell
docker search <image_name>
```
- 拉取镜像:
```shell
docker pull <image_name>:<tag>
```
- 列出所有本地镜像:
```shell
docker images
```
- 删除本地镜像:
```shell
docker rmi <image_name>
```
容器(Container)是从镜像创建的实例,可以被启动、停止、删除等。以下是一些常用的Docker容器操作命令:
- 创建并启动容器:
```shell
docker run -d --name <container_name> <image_name>:<tag>
```
- 列出所有正在运行的容器:
```shell
docker ps
```
- 停止容器:
```shell
docker stop <container_id>
```
- 删除容器:
```shell
docker rm <container_id>
```
另外,还可以使用Dockerfile来定义镜像的构建过程和配置,以便实现应用程序的自动化部署和版本控制。具体细节可以参考Docker的官方文档。
### 2.3 容器化应用的优势和挑战
使用容器化技术可以带来许多优势,例如:
- 灵活性:容器可以在任何支持Docker的平台上运行,无需考虑底层操作系统和硬件的差异。
- 可移植性:容器将应用程序及其所有依赖打包在一起,并提供了一种标准的部署和交付机制,可以轻

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以K8S、Linux-kubectl管理Kubernetes容器平台为核心,通过深入探索Kubernetes的各个方面,提供实战经验和技巧。文章从Kubernetes的简介及在容器化应用中的作用开始,解析其架构与核心组件,重点介绍了使用kubectl进行集群管理的方法。随后,将从容器编排的视角,从Docker过渡到Kubernetes,讲解使用kubeadm搭建Kubernetes集群的步骤,以及探索Kubernetes网络模型的原理。接下来,将重点讨论使用Pod进行应用扩展与负载均衡、多个容器化应用的部署与管理、容器存储的原理以及数据持久化的方法。同时,介绍了Kubernetes中的Service与Ingress的使用、ConfigMap和Secret的配置管理、Pod的生命周期与健康检查、自动伸缩与负载调度、应用安全与RBAC控制、应用日志与监控等内容。最后,重点讲解了故障排查与故障恢复的方法。通过本专栏的学习,读者将全面掌握Kubernetes的管理与应用技巧,提升容器化应用的部署与管理能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【张量分解:技术革命与实践秘籍】:从入门到精通,掌握机器学习与深度学习的核心算法

# 摘要
张量分解作为数据分析和机器学习领域的一项核心技术,因其在特征提取、预测分类及数据融合等方面的优势而受到广泛关注。本文首先介绍了张量分解的基本概念与理论基础,阐述了其数学原理和优化目标,然后深入探讨了张量分解在机器学习和深度学习中的应用,包括在神经网络、循环神经网络和深度强化学习中的实践案例。进一步,文章探讨了张量分解的高级技术,如张量网络与量
【零基础到专家】:LS-DYNA材料模型定制化完全指南

# 摘要
本论文对LS-DYNA软件中的材料模型进行了全面的探讨,从基础理论到定制化方法,再到实践应用案例分析,以及最后的验证、校准和未来发展趋势。首先介绍了材料模型的理论基础和数学表述,然后阐述了如何根据应用场景选择合适的材料模型,并提供了定制化方法和实例。在实践应用章节中,分析了材料模型在车辆碰撞、高速冲击等工程问题中的应用,并探讨了如何利用材料模型进行材料选择和产品设计。最后,本论文强调了材料模型验证和校准的重要
IPMI标准V2.0实践攻略:如何快速搭建和优化个人IPMI环境
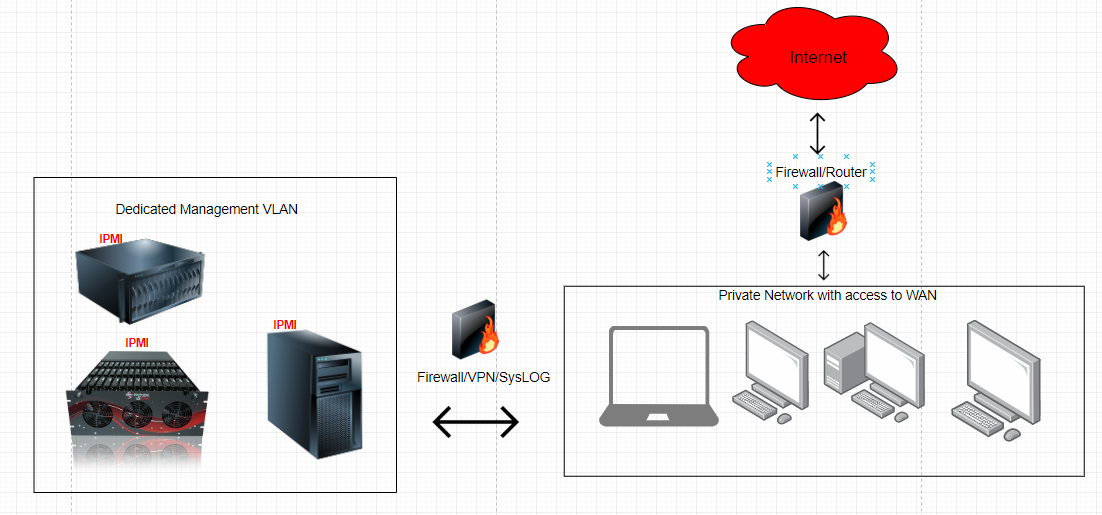
# 摘要
本文系统地介绍了IPMI标准V2.0的基础知识、个人环境搭建、功能实现、优化策略以及高级应用。首先概述了IPMI标准V2.0的核心组件及其理论基础,然后详细阐述了搭建个人IPMI环境的步骤,包括硬件要求、软件工具准备、网络配置与安全设置。在实践环节,本文通过详尽的步骤指导如何进行环境搭建,并对硬件监控、远程控制等关键功能进行了验证和测试,同时提供了解决常见问题的方案。此外,本文
SV630P伺服系统在自动化应用中的秘密武器:一步精通调试、故障排除与集成优化

# 摘要
本文全面介绍了SV630P伺服系统的工作原理、调试技巧、故障排除以及集成优化策略。首先概述了伺服系统的组成和基本原理,接着详细探讨了调试前的准备、调试过程和故障诊断方法,强调了参数设置、实时监控和故障分析的重要性。文中还提供了针对常见故障的识别、分析和排除步骤,并分享了真实案例的分析。此外,文章重点讨论了在工业自动化和高精度定位应用中
从二进制到汇编语言:指令集架构的魅力
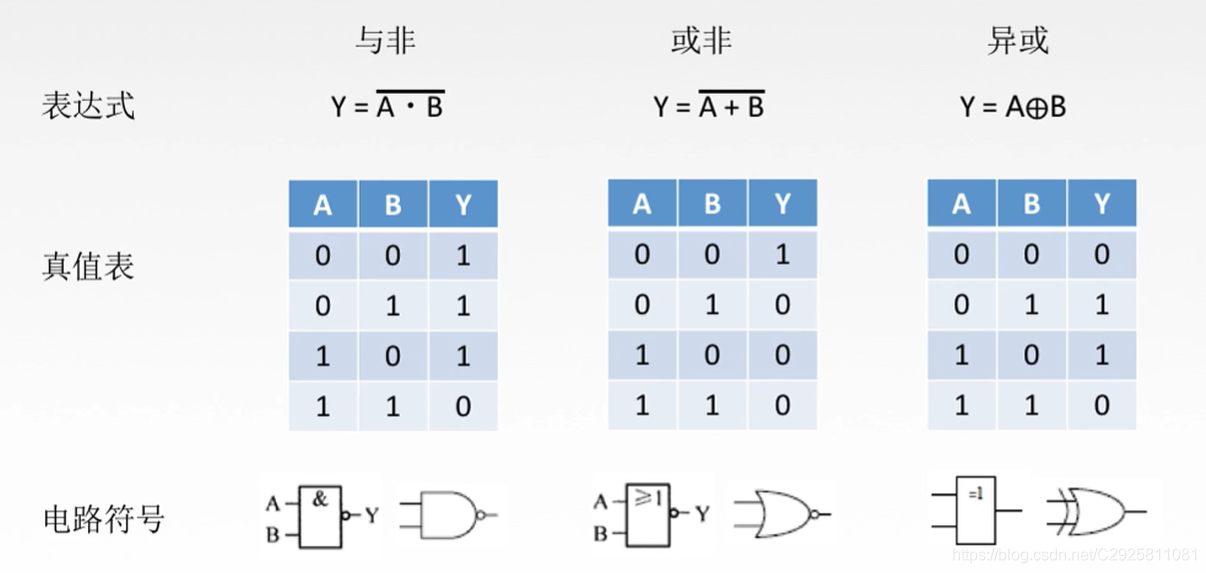
# 摘要
本文全面探讨了计算机体系结构中的二进制基础、指令集架构、汇编语言基础以及高级编程技巧。首先,介绍了指令集架构的重要性、类型和组成部分,并且对RISC和CISC架
深入解读HOLLiAS MACS-K硬件手册:专家指南解锁系统性能优化
# 摘要
本文首先对HOLLiAS MACS-K硬件系统进行了全面的概览,然后深入解析了其系统架构,重点关注了硬件设计、系统扩展性、安全性能考量。接下来,探讨了性能优化的理论基础,并详细介绍了实践中的性能调优技巧。通过案例分析,展示了系统性能优化的实际应用和效果,以及在优化过程中遇到的挑战和解决方案。最后,展望了HOLLiAS MACS-K未来的发展趋势
数字音频接口对决:I2S vs TDM技术分析与选型指南
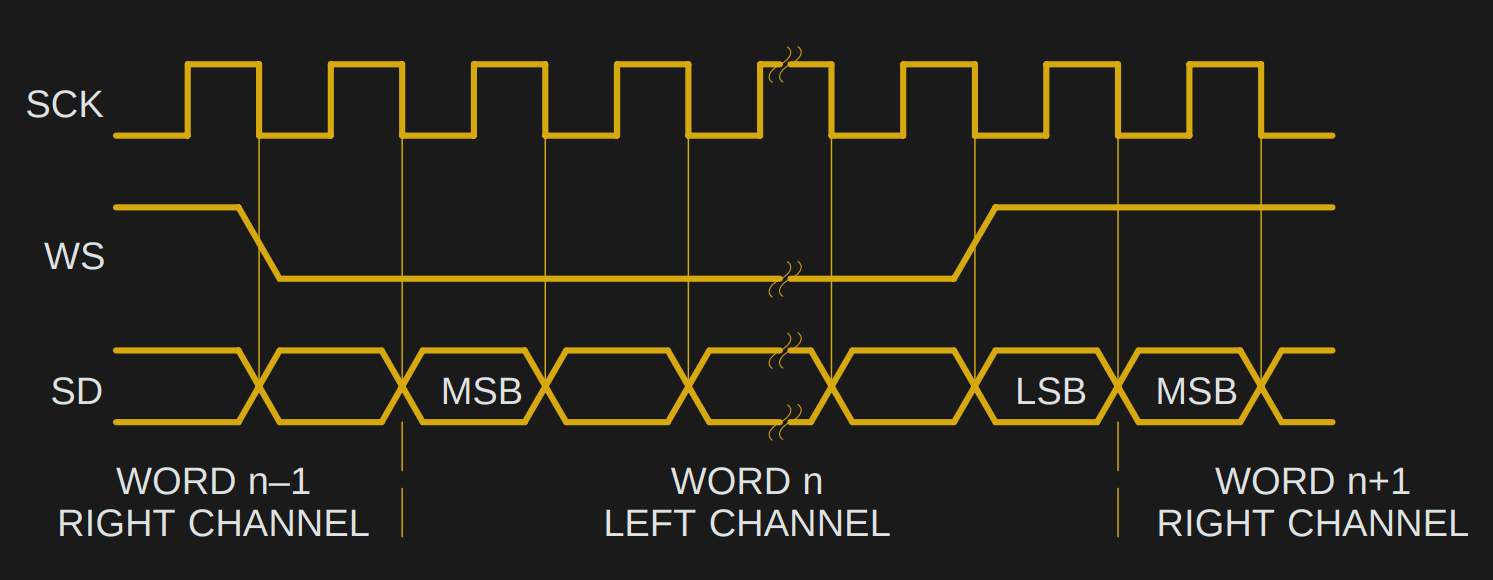
# 摘要
数字音频接口作为连接音频设备的核心技术,对于确保音频数据高质量、高效率传输至关重要。本文从基础概念出发,对I2S和TDM这两种广泛应用于数字音频系统的技术进行了深入解析,并对其工作原理、数据格式、同步机制和应用场景进行了详细探讨。通过对I2S与TDM的对比分析,本文还评估了它们在信号质量、系统复杂度、成本和应用兼容性方面的表现。文章最后提出了数字音频接口的选型指南,并展望了未来技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )