数据库性能调优秘籍
发布时间: 2024-12-26 16:54:10 阅读量: 5 订阅数: 4 

ORACLE数据库性能调优.docx
# 摘要
本文系统地探讨了数据库性能调优的多个方面,涵盖了性能评估、系统配置、访问优化、索引调优技巧、查询优化与执行计划分析以及高级调优策略。通过深入分析不同的调优技术和案例实践,文章旨在为数据库管理员提供一套完整的性能优化工具和方法。同时,本文也介绍了自动化工具和流程在性能调优中的作用,以及如何通过工具实现调优活动的标准化和持续改进。通过这些讨论,文章意在提升数据库性能,保证数据处理的高效率和稳定性。
# 关键字
数据库性能调优;性能评估;索引优化;查询分析;并发控制;自动化工具
参考资源链接:[解决MySQL 'Got timeout reading communication packets' 错误](https://wenku.csdn.net/doc/6412b737be7fbd1778d4982b?spm=1055.2635.3001.10343)
# 1. 数据库性能调优基础概念
在当今数据密集型的应用场景中,数据库性能调优是确保系统响应速度和数据处理能力的关键步骤。数据库性能调优涉及多个层面,包括但不限于索引优化、查询优化、系统配置调整、缓存策略等。为了深入理解性能调优,首先需要掌握一些基础概念,它们是建立更高级调优策略的基石。
## 1.1 数据库性能调优的必要性
在任何数据库驱动的应用中,性能都直接影响用户体验和系统稳定性。当应用表现出响应缓慢或资源消耗过高的问题时,进行性能调优变得尤为必要。调优不仅能够减少系统瓶颈,还能优化资源使用,提升整体的业务处理速度。
## 1.2 性能调优的基本原则
进行性能调优应遵循几个基本原则,包括"避免过度优化"、"先评估再调优"和"持续监控与调整"。这些原则帮助我们保持清晰的目标,并确保调优工作能够带来实际且持续的性能提升。
## 1.3 性能调优的目标
数据库性能调优的最终目的是提高事务吞吐量、减少查询响应时间以及提升系统资源的使用效率。这三者相辅相成,共同定义了数据库系统的性能指标。理解这些目标有助于在实际工作中制定明确的优化方向。
以上内容为数据库性能调优的基础概念章节,为理解后续章节中的具体调优策略和工具应用打下理论基础。下一章将介绍在执行调优前应进行的准备工作,以确保调优工作的有效性和安全性。
# 2. 数据库调优前的准备工作
### 2.1 数据库性能评估
#### 2.1.1 性能评估的重要性
数据库性能评估是一个关键的步骤,在任何调优活动开始之前,它可以帮助我们识别系统中的瓶颈。通过性能评估,数据库管理员可以获取当前系统运行状态的全面视图,了解数据库在不同工作负载下的表现。这样,可以确保调优工作有针对性,不会导致在错误的方向上浪费资源和时间。
#### 2.1.2 常用性能评估工具介绍
- **Oracle Enterprise Manager (OEM)**: 这是一个集中管理工具,为Oracle数据库提供了包括性能评估在内的全面解决方案。
- **SQL Server Management Studio (SSMS)**: 适用于Microsoft SQL Server,它提供了性能监视器用于跟踪数据库性能指标。
- **Percona Toolkit**: 这是一组针对MySQL的高级命令行工具,包括查询分析和性能监控。
### 2.2 数据库系统配置
#### 2.2.1 硬件资源分配
硬件资源的分配直接影响到数据库性能。数据库服务器的CPU、内存和磁盘I/O需要根据业务需求进行合理配置。例如,高并发读写操作的数据库需要更多的CPU资源和更快的磁盘I/O。对硬件进行正确评估和配置可以显著提升数据库性能。
#### 2.2.2 数据库初始化参数设置
数据库的初始化参数定义了数据库的行为方式。这些参数包括内存分配、连接设置、日志记录等。优化这些参数,比如调整SGA(系统全局区)和PGA(程序全局区)的大小,可以大幅提升性能。
### 2.3 数据库访问优化
#### 2.3.1 索引策略
索引是数据库访问优化的关键。正确创建索引可以大幅提升查询速度,但不恰当的索引可能会导致性能下降。索引策略包括选择合适的列进行索引,以及如何组合多个索引以优化查询。
#### 2.3.2 SQL语句优化
SQL语句优化是数据库优化中最直接的部分。通过优化SQL语句,可以减少不必要的数据加载和处理,从而提升性能。这包括使用合适的连接类型、避免在WHERE子句中使用函数、使用EXISTS代替IN等技巧。
```sql
-- 示例:不优化的SQL查询
SELECT * FROM employees WHERE YEAR(hire_date) = 2010;
-- 优化后的SQL查询
SELECT * FROM employees WHERE hire_date BETWEEN '2010-01-01' AND '2010-12-31';
```
上述示例中,优化后的查询避免了在WHERE子句中使用函数,这样数据库可以利用日期字段上的索引,提升查询效率。
# 3. 数据库索引调优技巧
### 3.1 索引的基本原理
索引是数据库中用于提高查询效率的关键组件之一,它类似于书籍的目录,能够快速定位数据行的位置而不必扫描整个表。索引大大减少了数据库搜索时间,提高了访问速度。
#### 3.1.1 B-Tree索引
B-Tree(也称为平衡树)索引是数据库中最常见的索引类型。B-Tree索引结构能够维护数据的排序顺序,并支持对数据进行快速查找、顺序访问、插入和删除操作。
```sql
CREATE INDEX idx_column_name ON table_name (column_name);
```
在上述SQL语句中,`CREATE INDEX`命令用于创建一个索引。通常,建立在某一列上,提高该列查询的速度。`idx_column_name`是索引的名称,`table_name`是表的名称,而`column_name`是需要建立索引的列名。
#### 3.1.2 其他索引类型(如哈希、全文)
除了B-Tree索引之外,数据库还支持其他类型的索引,如哈希索引和全文索引。哈希索引对于等值查询非常快,而全文索引适用于对文本数据进行搜索。
### 3.2 索引的选择和管理
#### 3.2.1 何时创建索引
索引的选择应基于查询模式和数据的使用情况。以下是一些创建索引的准则:
- 当列中包含大量唯一值时,创建索引是合理的,因为它能显著提升查询性能。
- 对于频繁用于连接操作的列,创建索引可以加快连接速度。
- 在WHERE子句、ORDER BY子句、GROUP BY子句中频繁出现的列,也应该考虑建立索引。
#### 3.2.2 索引的维护和重组
索引随着时间推移可能会变得碎片化,这会降低查询性能。索引维护包括清理碎片和重组索引。定期执行以下命令对索引进行维护:
```sql
ALTER INDEX idx_column_name REBUILD;
```
### 3.3 索引调优实践案例
#### 3.3.1 索引优化前后对比
考虑一个电子商务平台的商品搜索功能,该功能需要对商品名称进行频繁查询。初始阶段,商品名称上未建立索引,查询效率低下。优化后,在商品名称上建立B-Tree索引,查询响应时间缩短了数倍。
#### 3.3.2 索引调优经验分享
在索引调优过程中,确保只在必要时建立索引,过多的索引会增加写入操作的负担,可能会降低总体性能。同时,定期监控索引的使用情况,移除不常用的索引,保持索引的高效使用。
### 表格展示
| 索引类型 | 用途 | 适用场景 |
|------------|----------------------|-------------------------------------|
| B-Tree索引 | 提高查找速度,保持数据顺序 | 等值查询,范围查询 |
| 哈希索引 | 快速等值查询 | 低冲突率的列,如性别、状态码等 |
| 全文索引 | 文本内容搜索 | 商品描述、文章内容等长文本字段的搜索 |
### 代码块和逻辑分析
```sql
CREATE INDEX idx_product_name ON products (product_name);
```
执行上述代码块会在`products`表的`product_name`列上创建一个B-Tree索引。此索引对于包含大量不同产品名称的表来说是非常有用的,能够加快包含`WHERE`子句的查询操作,例如:
```sql
SELECT * FROM products WHERE product_name = '某产品名称';
```
### Mermaid 流程图
通过Mermaid流程图,我们可以可视化索引优化的决策过程:
```mermaid
graph TD
A[开始] --> B{评估查询需求}
B -->|频繁查询| C[建立索引]
B -->|写操作频繁| D[考虑索引影响]
C --> E[监控索引性能]
D -->|影响过大| F[优化索引或放弃]
E -->|性能提升| G[索引调优成功]
E -->|性能不足| H[分析原因并调整]
H --> G
```
根据此流程图,我们首先评估查询需求,若查询频繁,则建立索引;若写操作占主要,则需考虑索引的潜在性能影响。建立索引后,我们要不断监控其性能,如果优化成功,便能提高数据库的整体性能。
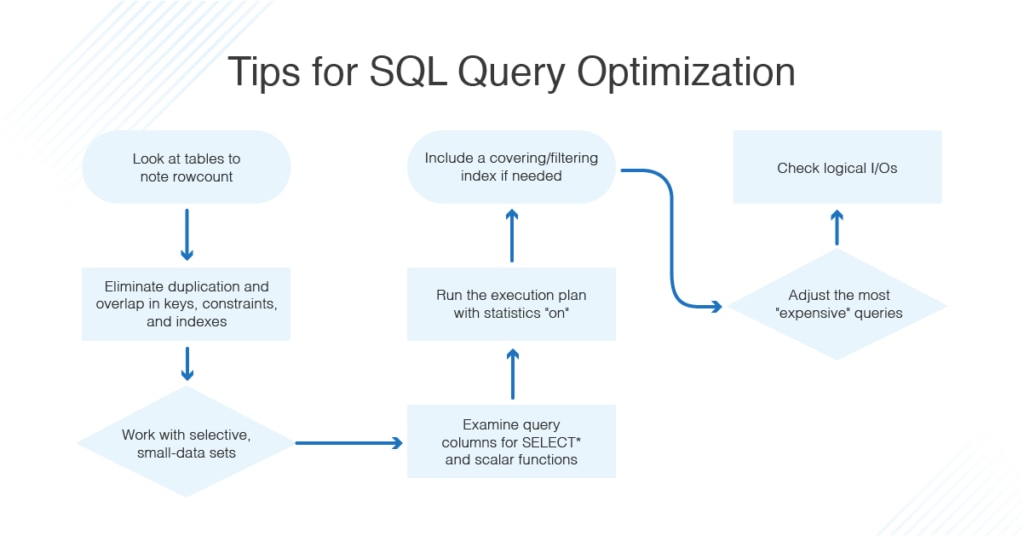
# 4. 查询优化与执行计划分析
查询优化是数据库性能调优中至关重要的一环。它是通过调整SQL语句和数据库执行策略来改善查询效率的过程。本章节将深入探讨SQL语句调优的基础知识,执行计划的分析以及如何通过实际案例进行学习和优化。
## 4.1 SQL语句调优基础
### 4.1.1 SQL语句的分类和作用
SQL(Structured Query Language)是数据库管理和操作的标准语言。根据其功能,SQL语句可以大致分为以下几类:
- **数据定义语言(DDL)**: 包括CREATE、ALTER、DROP等,用于定义或修改数据库结构。
- **数据操纵语言(DML)**: 包括INSERT、UPDATE、DELETE等,用于操作数据库中数据的增删改。
- **数据查询语言(DQL)**: 以SELECT为代表的语句,用于从数据库中检索信息。
- **数据控制语言(DCL)**: 包括GRANT、REVOKE等,用于控制数据库访问权限。
每一种SQL语句在数据库操作中都起着不可替代的作用,正确使用这些语句是查询优化的前提。
### 4.1.2 SQL编写规范和最佳实践
在编写SQL语句时,有一些规范和最佳实践可以帮助我们优化查询:
1. **使用具体的表和列名**: 避免使用SELECT *,尽量明确指出需要查询的列,减少数据传输量。
2. **合理使用索引**: 利用列的前缀、范围查询、JOIN条件等合理创建和使用索引,提高查询效率。
3. **避免复杂的子查询**: 尽量使用JOIN语句代替复杂的子查询。
4. **适当地使用事务**: 长事务会锁定资源,影响并发性能,合理划分事务可以减少锁竞争。
5. **减少不必要的排序和分组**: 使用ORDER BY和GROUP BY时,要考虑是否真的需要这些操作,因为它们往往需要额外的计算资源。
## 4.2 执行计划的解析与优化
### 4.2.1 执行计划的概念与获取
执行计划是数据库管理系统执行SQL语句的内部流程的详细描述。它包括了访问路径、操作类型、所用的索引、连接方法等信息。通过分析执行计划,我们可以了解数据库是如何处理SQL语句的,并据此进行调优。
获取执行计划的方法因数据库系统而异,以MySQL为例,可以通过在SQL语句前加上`EXPLAIN`关键字来获取执行计划。
```sql
EXPLAIN SELECT * FROM users WHERE age > 25;
```
### 4.2.2 执行计划分析与调整策略
执行计划的分析通常包括以下几个方面:
- **cost估算**: 每一步的估算成本,用于选择最佳的执行路径。
- **type列**: 表示访问数据的方式,比如ALL, index, range等,越高效的访问类型越好。
- **possible_keys列**: 可能被用于查询的索引。
- **key列**: 实际使用的索引。
- **key_len列**: 实际使用的索引长度。
- **rows列**: 预计需要检查的行数。
- **Extra列**: 包含额外信息,如"Using index"表示使用了索引覆盖。
根据分析结果,我们可以采取以下调整策略:
- **增加索引**: 如果possible_keys列为NULL,通常意味着需要添加适当的索引来优化查询。
- **重新构造查询**: 如果Extra列包含"Using filesort"或"Using temporary"等,可能需要重写查询语句。
- **优化数据类型**: 如果key_len列较小,可能表明索引字段定义的数据类型可以优化。
- **限制结果集**: 如果rows列的数字很大,可以考虑增加WHERE条件来减少结果集的大小。
## 4.3 实际案例分析
### 4.3.1 案例背景与问题诊断
某社交网站发现在高峰时段,用户的查询响应时间变慢。通过分析,发现主要问题是由于一个用户状态查询的SQL语句执行计划不佳。
```sql
SELECT * FROM users WHERE status = 'active';
```
通过`EXPLAIN`分析发现,该语句没有使用任何索引,导致了全表扫描,其执行计划如下:
```plaintext
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
| 1 | SIMPLE | users | NULL | ALL | NULL | NULL | NULL | NULL | 500000 | 10.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------+
```
### 4.3.2 解决方案和效果评估
为了解决上述问题,团队决定在`status`字段上创建索引:
```sql
CREATE INDEX idx_status ON users (status);
```
创建索引后再次执行`EXPLAIN`:
```plaintext
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+-------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+-------+----------+-------+
| 1 | SIMPLE | users | NULL | index | idx_status | idx_status | 6 | NULL | 500000| 10.00 | NULL |
+----+-------------+-------+------------+-------+---------------+--------------+---------+------+-------+----------+-------+
```
可以看出,执行计划已经有了变化,虽然仍然是全表扫描,但是现在利用了`idx_status`这个索引。虽然该方案可以优化查询,但是我们意识到,如果能进一步限制返回的数据量,则效果更好。
最终,通过在WHERE条件中添加更多的过滤条件来限制返回的数据量,可以进一步提升查询性能:
```sql
SELECT * FROM users WHERE status = 'active' AND age > 18 AND gender = 'M';
```
优化后的执行计划和实际效果表明,查询时间大大减少,用户体验得到显著提升。这样的案例分析和优化过程是我们在数据库性能调优中常见的操作,也是提升系统性能的关键步骤。
通过本章节的介绍,我们深入了解了SQL语句的分类和作用,执行计划的重要性以及如何分析和优化。在后续的章节中,我们将继续探讨更高级的数据库性能调优策略,以帮助IT专业人员进一步提升其数据库系统的性能。
# 5. 高级数据库性能调优策略
## 5.1 并发控制和事务管理
在多用户环境下的数据库系统中,并发控制和事务管理是保持数据一致性和提高系统性能的关键。
### 5.1.1 锁机制和死锁分析
数据库锁是保证数据完整性的机制之一,它能够防止多个事务同时修改同一数据项。锁的粒度可以是表级、行级或者更细的粒度。锁过多会造成系统性能下降,而锁过少可能导致数据不一致。
#### 死锁
死锁是多个进程因竞争资源而造成的一种僵局。在数据库中,死锁常发生在两个或多个事务相互等待对方持有的锁。检测死锁需要系统能够识别和分析锁的使用情况。解决死锁的策略包括设置锁超时、事务回滚和死锁预防协议等。
### 5.1.2 事务隔离级别和影响
事务隔离级别定义了一个事务在操作数据时与其他事务的隔离程度。SQL标准定义了四个隔离级别:读未提交、读已提交、可重复读和串行化。不同的隔离级别会对性能产生影响:
- 读未提交:性能最好,但可能导致脏读。
- 读已提交:解决了脏读,但可能导致不可重复读。
- 可重复读:解决了不可重复读,但可能导致幻读。
- 串行化:最高隔离级别,可解决幻读,但并发性能最差。
## 5.2 数据库分区与分片
随着数据量的增长,传统的单一数据库结构可能成为系统性能的瓶颈。分区和分片是将数据分布到多个数据库或表中的技术,可以提高性能和管理能力。
### 5.2.1 分区的概念和优势
分区将表划分为更小、更易管理的部分,每个分区可以单独存储和访问。分区的优势包括:
- 提高了查询效率:针对特定分区的数据访问更快。
- 提高了维护效率:便于进行数据的备份和恢复操作。
- 增强了可用性:单个分区出现故障时,不影响其他分区。
### 5.2.2 分片策略与实施步骤
分片是将数据分布到不同的服务器上,以增加系统的扩展性和负载能力。分片策略包括范围分片、哈希分片和列表分片等。实施分片时需要考虑数据的分布和查询模式,以及如何保持数据的均匀分布。
## 5.3 数据库缓存优化
缓存机制能够显著提高数据库性能,通过将频繁访问的数据存储在内存中来减少磁盘I/O操作。
### 5.3.1 缓存机制的工作原理
缓存通过快速访问内存来提高性能,数据库缓存通常是数据库管理系统内部的一部分。当一个数据被访问时,它首先在缓存中查找,如果找到,则直接使用缓存的数据,否则进行磁盘I/O。
### 5.3.2 缓存配置和优化方法
缓存优化主要关注以下方面:
- 缓存大小:缓存太大可能导致内存资源紧张,太小则可能无法充分发挥缓存的作用。
- 缓存策略:包括LRU(最近最少使用)、FIFO(先进先出)等。
- 数据预取:根据访问模式预取可能需要的数据。
- 缓存命中率监控:分析缓存命中率,及时调整缓存策略。
例如,以下是一个数据库缓存配置的示例代码,使用SQL语言进行配置优化:
```sql
-- 假设使用的是Oracle数据库
ALTER SYSTEM SET shared_pool_size = 512M;
-- 查询当前的缓存命中率
SELECT parameter, value FROM v$sysstat WHERE name LIKE 'db%cache%hit%';
```
这些高级策略的深入分析与应用,将帮助数据库管理员在面对大数据挑战时,更加从容地应对性能问题。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了MySQL连接超时问题,提供了一系列全面的解决方案。专栏标题“MySQL提示got timeout reading communication packets的解决方法”清晰地指出了问题的核心。文章内容涵盖了MySQL连接超时的真正原因、数据库性能调优技巧、网络延迟应对策略、MySQL错误日志解读、数据库连接池优化指南、操作系统级性能调优方法、软件更新建议和代码优化指南。通过深入分析和实用的建议,本专栏旨在帮助读者彻底解决MySQL连接超时问题,优化数据库性能,提升应用程序的稳定性和效率。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
晶体三极管噪声系数:影响因素深度剖析及优化(专家级解决方案)
# 摘要
晶体三极管噪声系数是影响电子设备性能的关键参数。本文系统阐述了噪声系数的理论基础,包括其定义、重要性、测量方法和标准,并从材料工艺、设计结构、工作条件三个角度详细分析了影响噪声系数的因素。针对这些影响因素,本文提出了在设计阶段、制造工艺和实际应用中的优化策略,并结合案例研究,提供了噪声系数优化的实践指导和评估方法。研究成果有助于在晶体三极管的生产
MATLAB®仿真源代码深度解析:电子扫描阵列建模技巧全揭露
_0_itok=vqPKU6MD.jpg)
# 摘要
本文综合探讨了MATLAB®在电子扫描阵列仿真中的应用,从基础理论到实践技巧,再到高级技术与优化方法。首先介绍MATLAB®仿真的基本概念和电子扫描阵列的基础理论,包括阵列天线的工作原理和仿真模型的关键建立步骤。然后,深入讲解了MATLAB®
RK3308多媒体应用硬件设计:提升性能的3大要点

# 摘要
本论文详细介绍了RK3308多媒体应用硬件的各个方面,包括硬件概述、性能优化、内存与存储管理、多媒体编解码性能提升、电源管理与热设计,以及设计实例与技术趋势。通过对RK3308处理器架构和硬件加速技术的分析,本文阐述了其在多媒体应用中的性能关键指标和优化策略。本文还探讨了内存和存储的管理策略,以及编解码器的选择、多线程优化、音频处理方案,并分析了低功耗设计和热管理技术的应用。最后,通过实
Matlab矩阵操作速成:速查手册中的函数应用技巧

# 摘要
本文系统地介绍了Matlab中矩阵操作的基础知识与进阶技巧,并探讨了其在实际应用中的最佳实践。第一章对矩阵进行了基础概述,第二章深入讨论了矩阵的创建、索引、操作方法,第三章则聚焦于矩阵的分析、线性代数操作及高级索引技术。第四章详细解释了Matlab内置的矩阵操作函数,以及如何通过这些函数优化性能。在第五章中,通过解决工程数学问题、数据分析和统计应用,展示了矩阵操作的实际应用。最后一章提供了矩阵操作的编码规范
DVE中的数据安全与备份:掌握最佳实践和案例分析
# 摘要
随着信息技术的飞速发展,数据安全与备份成为了企业保护关键信息资产的核心问题。本文首先概述了数据安全的基本理论和备份策略的重要性,然后深入探讨了数据加密与访问控制
自动化图层融合技巧:ArcGIS与SuperMap脚本合并技术
# 摘要
自动化图层融合技术是地理信息系统中重要的技术手段,它能够高效地处理和整合多源空间数据。本文对自动化图层融合技术进行了全面概述,并深入探讨了ArcGIS和SuperMap两种主流地理信息系统在自动化脚本合并基础、图层管理和自动化实践方面的具体应用。通过对比分析,本文揭示了ArcGIS和SuperMap在自动化处理中的相似之处和各自特色,提出了一系列脚本合并的理论基础、策略流程及高级应用
AMESim案例分析:汽车行业仿真实战的20个深度解析
# 摘要
AMESim软件作为一种高级仿真工具,在汽车行业中的应用日益广泛,涵盖了从动力传动系统建模到车辆动力学模拟,再到燃油经济性与排放评估等各个方面。本文详细介绍了AMESim的基础理论、操作界面和工作流程,并深入探讨了在构建和分析仿真模型过程中采用的策略与技巧。通过对不同应用案例的分析,例如混合动力系统和先进驾驶辅助系统的集成,本文展示了
【云基础设施快速通道】:3小时速成AWS服务核心组件

# 摘要
本文全面介绍了云基础设施的基础知识,并以亚马逊网络服务(AWS)为例,详细解读了其核心服务组件的理论基础和实操演练。内容涵盖AWS服务模型的构成(如EC2、S3、VPC)、核心组件间的交互、运行机制、安全性和合规性实践。进一步,文章深入探讨了AWS核心服务的高
CRC16校验码:实践中的理论精髓,数据完整性与性能优化的双重保障
# 摘要
本文全面探讨了CRC16校验码的理论基础、实际应用、实践实现以及性能优化策略。首先介绍了CRC16的数学原理、常见变种以及在数据完整性保障中的作用。接着,详细阐述了CRC16算法在不同编程语言中的实现方法、在文件校验和嵌入式系统中的应用实例。文章第四章专注于性能优化,探讨了算法优化技巧、在大数据环境下的挑战与对策,以及CRC16的性能
【异常处理】:Python在雷电模拟器脚本中的实战应用技巧

# 摘要
本文探讨了Python在雷电模拟器脚本中异常处理的应用,从基础理论到高级技巧进行了全面分析。第一章介绍了Python异常处理的基础知识,为后续章节的深入理解打下基础。第二章重点讨论了异常处理机制在雷电模拟器脚本中的实际应用,包括异常类结构、常见异常类型、捕获与处理技巧以及对脚本性能的影响。第三章进一步阐述了多线程环境下的异常处理策略和资源管理问题,还提供了优化异常处理性能的实践经验。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )