WPS文字处理:利用邮件合并和批量打印技巧
发布时间: 2024-01-24 05:41:16 阅读量: 127 订阅数: 48 

邮件合并制作
# 1. 理解WPS文字处理的邮件合并功能
## 1.1 什么是WPS文字处理的邮件合并功能
邮件合并是WPS文字处理中一项非常实用的功能,它能够帮助用户将一个邮件内容与多个收件人信息合并,生成多份个性化的邮件文档,极大地提高了邮件发送效率。
## 1.2 如何打开和使用邮件合并功能
用户可以通过WPS文字处理菜单栏中的“邮件合并”功能来打开并使用邮件合并功能,按照操作界面提示完成设置步骤即可轻松实现邮件合并。
## 1.3 邮件合并的应用场景和优势
邮件合并广泛应用于批量发送邀请函、通知、问候信等场景,其优势在于可根据收件人信息个性化定制邮件内容,提高邮件的个性化和针对性,增加沟通的效果。
以上就是关于WPS文字处理邮件合并功能的介绍,接下来我们将深入了解如何在WPS文字处理中进行邮件合并。
# 2. 创建邮件合并文档
在使用WPS文字处理进行邮件合并之前,需要先创建一个邮件合并文档。下面将介绍如何创建邮件合并文档的步骤。
### 2.1 设定邮件合并的主文档
首先,需要准备好邮件合并的主文档。主文档是一个包含了邮件内容的模板文件,其中可以通过插入特定的字段来标记个性化的内容。在准备好主文档后,可以按照以下步骤来设定邮件合并的主文档:
1. 打开WPS文字处理,并创建一个新的空白文档。
2. 在文档中填写好邮件的正文内容,可以通过插入字段来标记个性化的内容,如收件人姓名、地址等。插入字段的方法是,在文档中选择要插入字段的位置,然后点击工具栏中的"邮件合并"选项,再选择"插入字段"。
3. 在插入字段的对话框中,可以选择要插入的字段类型,例如姓名、地址、公司等。根据需要选择相应的字段类型,然后点击"确定"按钮。
### 2.2 插入收件人数据源
在设定好主文档后,还需要插入收件人的数据源,以便进行邮件合并。数据源可以是一个Excel表格、CSV文件、或者WPS数据表。插入数据源的方法如下:
1. 在WPS文字处理中,点击工具栏中的"邮件合并"选项,再选择"插入数据源"。
2. 在插入数据源的对话框中,选择要插入的数据源文件,然后点击"确定"按钮。
### 2.3 设定邮件合并规则
在插入数据源后,还需要设定合并规则,以确定如何将数据源中的信息应用到主文档中。合并规则可以根据需要进行设定,例如选择要合并的数据记录、过滤条件等。设定合并规则的方法如下:
1. 在WPS文字处理中,点击工具栏中的"邮件合并"选项,再选择"设定合并规则"。
2. 在设定合并规则的对话框中,可以选择要合并的数据记录、过滤条件等。根据需要进行相应的设定,然后点击"确定"按钮。
经过以上步骤,就成功创建了邮件合并文档。接下来,可以进行个性化邮件的定制和批量打印操作。
# 3. 定制个性化邮件
在前面的章节中,我们学习了如何创建邮件合并文档和插入收件人数据源。现在,我们将进一步学习如何定制个性化邮件,使每封邮件都能够根据收件人的信息进行个性化处理。
#### 3.1 插入个性化内容和字段
在邮件合并过程中,我们可以插入个性化内容和字段,使每封邮件都能够包含特定的信息。比如,我们可以在邮件中插入收件人的姓名、职位、公司名称等。
在WPS文字处理中,插入个性化字段非常简单。首先,在合并文档中定位到需要插入字段的位置,然后点击菜单栏中的"邮件合并"选项卡,在"个性化字段"组中选择相应的字段进行插入。
以下是一个示例代码片段,用于在邮件中插入收件人姓名和公司名称:
```java
import java.util.HashMap;
import java.util.Map;
public class EmailMerge {
public static void main(String[] args) {
// 假设有一个收件人的姓名和公司名称数据
Map<String, String> recipientData = new HashMap<>();
recipientData.put("name", "张三");
recipientData.put("company", "ABC公司");
String emailContent = "尊敬的{姓名}先生/女士,您好!欢迎加入{公司名称},祝您工作顺利!";
// 替换字段
emailContent = emailContent.replace("{姓名}", recipientData.get("name"));
emailContent = emailContent.replace("{公司名称}", recipientData.get("comp
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏是针对WPS应用技能的一级考试而设计的,涵盖了WPS文字处理、表格处理和演示功能的各种使用技巧与实际应用。首先对文字处理功能进行介绍,包括排版格式化、样式和主题的运用,以及标签、目录、引用的生成技巧。其次详解表格处理功能,涉及数据排序、筛选、复杂公式运用、数据透视表等高级操作。最后对演示功能进行初步使用介绍,并包含了制作高效幻灯片、插入视频音频、利用矢量图形和SmartArt制作精美图表等内容。此外,专栏中也提供了多个实际应用实例和高级技巧,如数据透视表高级应用、逻辑关系和交互操作制作复杂演示、利用数据验证和条件格式化展现数据特征等。通过学习本专栏,读者可以全面掌握WPS办公软件的各项功能,提升自身应用技能,并为计算机一级考试做好准备。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Windows系统性能升级】:一步到位的WinSXS清理操作手册
# 摘要
本文针对Windows系统性能升级提供了全面的分析与指导。首先概述了WinSXS技术的定义、作用及在系统中的重要性。其次,深入探讨了WinSXS的结构、组件及其对系统性能的影响,特别是在系统更新过程中WinSXS膨胀的挑战。在此基础上,本文详细介绍了WinSXS清理前的准备、实际清理过程中的方法、步骤及
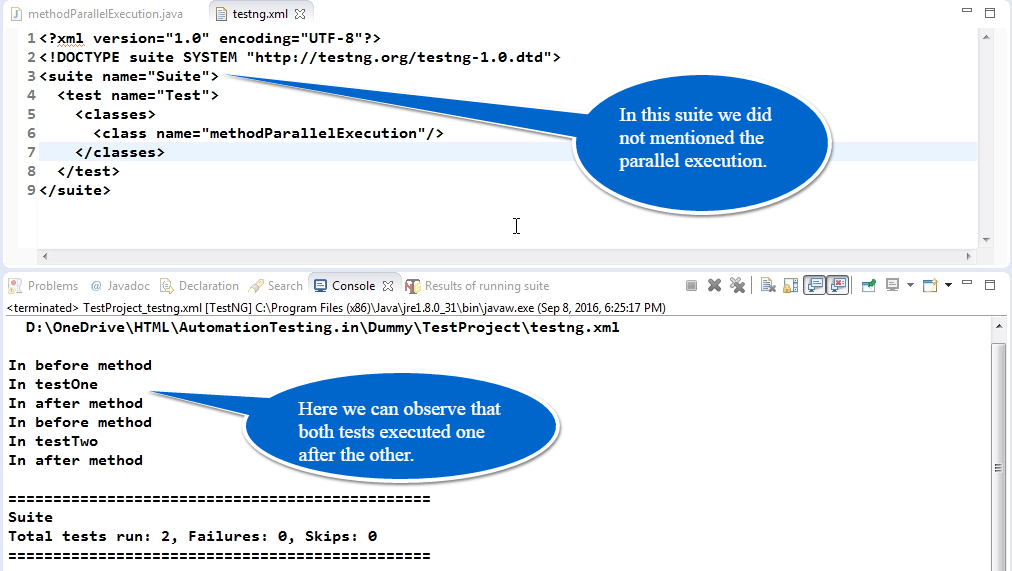
Lego性能优化策略:提升接口测试速度与稳定性
# 摘要
随着软件系统复杂性的增加,Lego性能优化变得越来越重要。本文旨在探讨性能优化的必要性和基础概念,通过接口测试流程和性能瓶颈分析,识别和解决性能问题。文中提出多种提升接口测试速度和稳定性的策略,包括代码优化、测试环境调整、并发测试策略、测试数据管理、错误处理机制以及持续集成和部署(CI/CD)的实践。此外,本文介绍了性能优化工具和框架的选择与应用,并
UL1310中文版:掌握电源设计流程,实现从概念到成品

# 摘要
本文系统地探讨了电源设计的全过程,涵盖了基础知识、理论计算方法、设计流程、实践技巧、案例分析以及测试与优化等多个方面。文章首先介绍了电源设计的重要性、步骤和关键参数,然后深入讲解了直流变换原理、元件选型以及热设计等理论基础和计算方法。随后,文章详细阐述了电源设计的每一个阶段,包括需求分析、方案选择、详细设计、仿真
Redmine升级失败怎么办?10分钟内安全回滚的完整策略
# 摘要
本文针对Redmine升级失败的问题进行了深入分析,并详细介绍了安全回滚的准备工作、流程和最佳实践。首先,我们探讨了升级失败的潜在原因,并强调了回滚前准备工作的必要性,包括检查备份状态和设定环境。接着,文章详解了回滚流程,包括策略选择、数据库操作和系统配置调整。在回滚完成后,文章指导进行系统检查和优化,并分析失败原因以便预防未来的升级问题。最后,本文提出了基于案例的学习和未来升级策
频谱分析:常见问题解决大全

# 摘要
频谱分析作为一种核心技术,对现代电子通信、信号处理等领域至关重要。本文系统地介绍了频谱分析的基础知识、理论、实践操作以及常见问题和优化策略。首先,文章阐述了频谱分析的基本概念、数学模型以及频谱分析仪的使用和校准问题。接着,重点讨论了频谱分析的关键技术,包括傅里叶变换、窗函数选择和抽样定理。文章第三章提供了一系列频谱分析实践操作指南,包括噪声和谐波信号分析、无线信号频谱分析方法及实验室实践。第四章探讨了频谱分析中的常见问题和解决
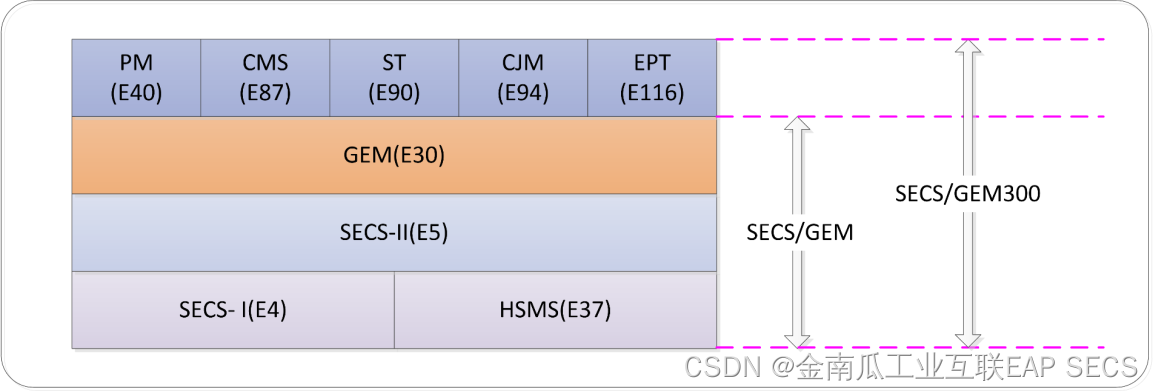
SECS-II在半导体制造中的核心角色:现代工艺的通讯支柱
# 摘要
SECS-II标准作为半导体行业中设备通信的关键协议,对提升制造过程自动化和设备间通信效率起着至关重要的作用。本文首先概述了SECS-II标准及其历史背景,随后深入探讨了其通讯协议的理论基础,包括架构、组成、消息格式以及与GEM标准的关系。文章进一步分析了SECS-II在实践应用中的案例,涵盖设备通信实现、半导体生产应用以及软件开发与部署。同时,本文还讨论了SECS-II在现代半导体制造
深入探讨最小拍控制算法

# 摘要
最小拍控制算法是一种用于实现快速响应和高精度控制的算法,它在控制理论和系统建模中起着核心作用。本文首先概述了最小拍控制算法的基本概念、特点及应用场景,并深入探讨了控制理论的基础,包括系统稳定性的分析以及不同建模方法。接着,本文对最小拍控制算法的理论推导进行了详细阐述,包括其数学描述、稳定性分析以及计算方法。在实践应用方面,本文分析了最小拍控制在离散系统中的实现、
【Java内存优化大揭秘】:Eclipse内存分析工具MAT深度解读

# 摘要
本文深入探讨了Java内存模型及其优化技术,特别是通过Eclipse内存分析工具MAT的应用。文章首先概述了Java内存模型的基础知识,随后详细介绍MAT工具的核心功能、优势、安装和配置步骤。通过实战章节,本文展示了如何使用MAT进行堆转储文件分析、内存泄漏的检测和诊断以及解决方法。深度应用技巧章节深入讲解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )