机器学习:指数族分布与共轭先验
需积分: 0 15 浏览量
更新于2024-08-05
收藏 9.61MB PDF 举报
"这篇内容是关于机器学习中的指数族分布,它是概率论和统计学中的一个重要概念,尤其在机器学习算法推导中占有关键地位。指数族分布包括高斯分布、泊松分布等常见分布,它们具有特定的数学形式,便于进行统计推断和计算。充分统计量在此类分布中起着核心作用,可以用来简洁地概括数据的主要特征。"
在机器学习中,指数族分布是一类具有广泛应用的概率分布,其特点是可以通过一个共同的函数形式来表示,这个函数就是所谓的配分函数。配分函数是归一化的,确保了概率分布的总和为1。例如,高斯分布(正态分布)就是一个典型的指数族分布,其参数通常包括均值和方差。
描述中提到,充分统计量是指数族分布的一个关键概念,它可以将复杂的样本数据压缩为少数几个统计量,而不丢失任何关于原始数据的重要信息。例如,在高斯分布中,均值和方差就是充分统计量,它们可以完全确定一个高斯分布。通过这两个统计量,我们可以得到高斯分布的具体表达式。
共轭先验在贝叶斯统计中是非常重要的,它简化了计算过程。当一个先验分布与似然函数属于同一指数族时,它们的后验分布会保持相同的数学形式,这被称为共轭性。比如,如果似然是高斯分布,选择高斯先验就会得到高斯后验,这就是高斯分布的自共轭特性。共轭先验的优势在于可以得到后验分布的闭合形式,避免了数值积分的复杂性,有助于直观理解似然函数如何影响先验分布的更新。
无信息先验是一种弱假设的先验分布,它尽可能地对后验分布影响最小,使得模型更依赖于观测数据,而不是先验知识。这种先验通常基于最大熵原理,意味着在没有其他信息的情况下,选择最大化熵的分布。
此外,指数族分布还涉及到线性组合和广义线性模型。在这些模型中,指数族分布常被用作响应变量的概率分布,而线性组合(如线性函数或激活函数的反函数)则用来连接模型的预测值和这些指数族分布的参数。
最后,变分推断是处理复杂概率模型的一种方法,尤其是在指数族分布下,它能有效地近似后验分布,对于大规模数据集的学习尤其有用,因为它可以减少计算复杂度,不需要存储每个样本的信息。
指数族分布是机器学习算法中不可或缺的一部分,它们在贝叶斯推断、统计建模和优化计算等方面发挥着重要作用。理解并熟练运用指数族分布及其特性,对于提升机器学习模型的性能和效率至关重要。
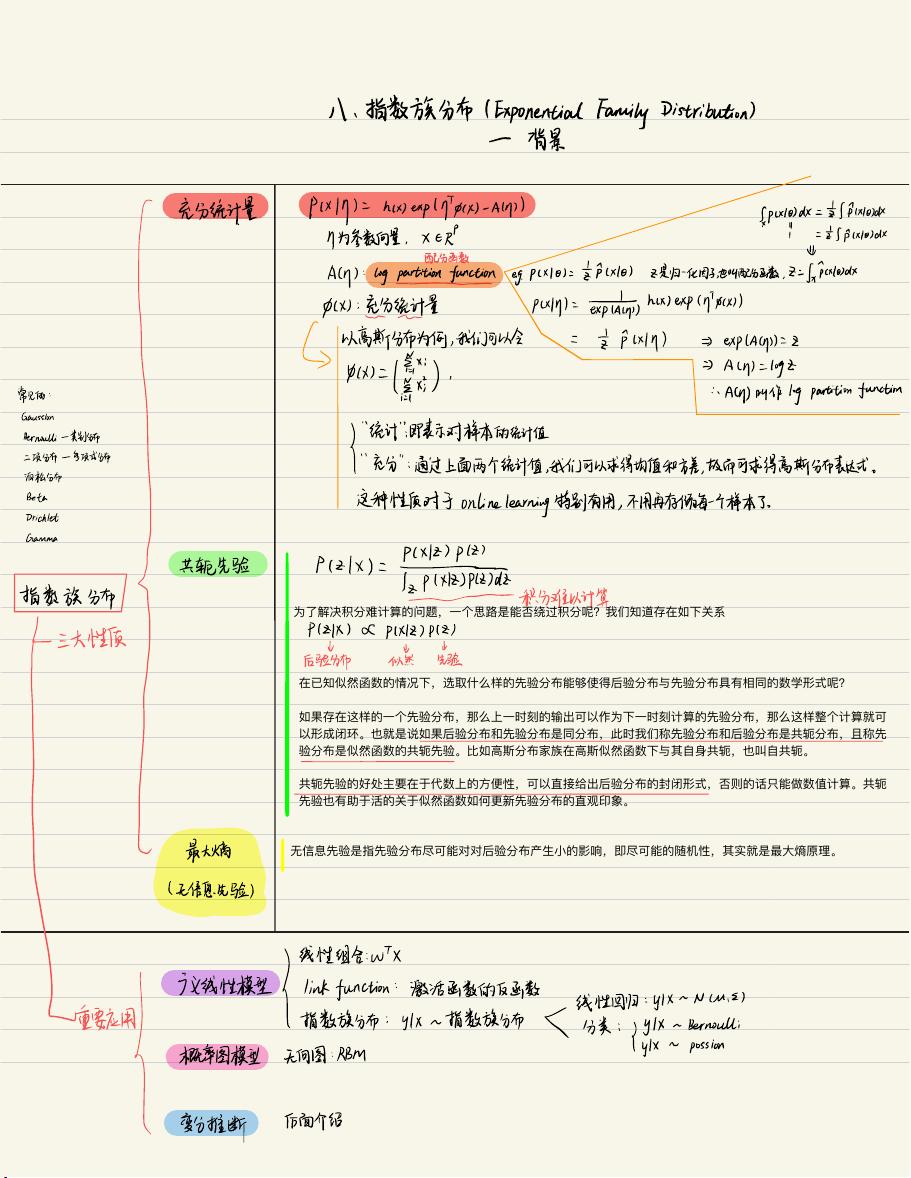
为了解决积分难计算的问题,⼀个思路是能否绕过积分呢?我们知道存在如下关系
在已知似然函数的情况下,选取什么样的先验分布能够使得后验分布与先验分布具有相同的数学形式呢?
如果存在这样的⼀个先验分布,那么上⼀时刻的输出可以作为下⼀时刻计算的先验分布,那么这样整个计算就可
以形成闭环。也就是说如果后验分布和先验分布是同分布,此时我们称先验分布和后验分布是共轭分布,且称先
验分布是似然函数的共轭先验。⽐如⾼斯分布家族在⾼斯似然函数下与其⾃身共轭,也叫⾃共轭。
共轭先验的好处主要在于代数上的⽅便性,可以直接给出后验分布的封闭形式,否则的话只能做数值计算。共轭
先验也有助于活的关于似然函数如何更新先验分布的直观印象。
⽆信息先验是指先验分布尽可能对对后验分布产⽣⼩的影响,即尽可能的随机性,其实就是最⼤熵原理。
⼋、
指数
族
分布
IExponentialF amigDistributi.nl
-
背景
充分
统计
量
以
1
7
)
⼆
hhpl
忤
化
)
-
A
1
7
"
他
⽐
1
0
)
𣏴
形成
1
0
⽐
⼀
川
为
参数
向量
,
XERP
1
-
1
⽉
⽐
1
0
)
⽐配
分
函数
业
A
(
7
)
:
hgparttnf-g.PL
ㄨ
1
0
1
⼆胡
⽐
1
0
)
⼜
是
归
化
因⼦
,
也
叫
配
分
函数
,
2
我
应
⼼
⽐
灿
:
炁
分
焦
计量
pcxlgke xp .ly
⼼
城
们
㶭
↳
以
⾼
斯
分布
为
何
,
我们
可
上
⼆
⽖
⼆⽉
⽐
1715
唙
州
》
=
2
1
0
以上
(
Ěì
A
以
⼆
192
常⻅的
:
点
砂
'
i
M
)
叫作
lgpartitonfunctim
䲜
湖
怖
|
统
试
即
表示
对
样本
的
统计
值
1
⼀项
分布
⼀
多项式
分布
I
"
充分
"
:
通过
上⾯
两个
统计
值
,
我们
可以
求得
均值
和
⽅差
,
故⽽
可
求
得
⾼
斯
分布
表达式
。
泊松分布
Beta
这种
性质
对于
onhneleamig
特别
有⽤
,
不⽤
再
存储
每个
样本
了
。
𡆇
ālii
:
鬣
𧅤
煍
"
I.
䆐
𠠬
-_-
线性
组合
nix
⼴义
线性
模型
中
liwkfunctioni
激活
函数
的
反
函数
重
鞻
概率
图
模型
䨻
䰞
"
以
指数
族
分布
下
㼂
管
器
戀
!
变
分
推断
后⾯
介绍
下载后可阅读完整内容,剩余5页未读,立即下载
2023-11-17 上传
2022-06-14 上传
2024-07-18 上传
2022-06-14 上传
2015-07-02 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

我要WhatYouNeed
- 粉丝: 48
- 资源: 287
 我的内容管理
展开
我的内容管理
展开







最新资源
- object-pattern:JavaScript 的对象模式结构
- Nunes-Corp.github.io:Nunes Corp.网站
- TestVisualStudioBg:联合国工程
- weichiangko.github.io
- em-hrs-ingestor:CVP批量导入项目的摄取组件
- liuhp.github.io:个人主页
- Hyrule-Compendium-node-client:Hyrule Compendium API的官方Node.js客户端
- 等级聚合:汇总有序列表。-matlab开发
- MYSQL 定界符分析通过硬编码的方式实现多语句分割并且支持定界符
- Proyecto-Reactjs
- LLVMCMakeBackend:愚人节笑话,CMake的llvm后端
- A5Orchestrator-1.0.2-py3-none-any.whl.zip
- Knotter:凯尔特结的互动设计师-开源
- Eva是一个分布式数据库系统,它实现了一个时间感知,累积和原子一致的实体-属性-值数据模型
- resume-website:AngularJS内容管理系统
- 配煤专家系框图.zip
