OLAP引擎详解:原理、对比与大数据实践
需积分: 50 19 浏览量
更新于2024-07-18
收藏 1.84MB PPTX 举报
"本文主要探讨了OLAP引擎的原理,包括其定义、分类以及不同的实现方式,如ROLAP、MOLAP和HOLAP。同时,提到了大数据环境下的OLAP引擎对比,特别介绍了Kylin作为分布式分析引擎的角色。"
OLAP引擎的底层运行原理
OLAP引擎的核心在于其能够快速响应复杂查询的能力。这主要归功于其对数据的预计算和存储优化。在MOLAP中,数据以多维立方体的形式存储,通过预先计算好的聚合数据,提高了查询速度。而在ROLAP中,数据存储在关系数据库中,依赖于数据库管理系统进行查询处理,这可能需要更多的计算资源。HOLAP结合了两者的优势,提供了一种平衡的解决方案。
大数据OLAP引擎对比
在大数据环境中,OLAP引擎如Kylin,旨在解决大规模数据集上的分析问题。Kylin作为Apache的顶级项目,通过构建预计算的立方体,实现了对Hadoop数据的快速SQL查询。与传统的ROLAP和MOLAP相比,Kylin在大数据场景下具有更高的性能和可扩展性。Kylin支持与其他大数据组件如HBase、Hive和Spark集成,提供了更广泛的数据处理能力。
相关大数据组件的简介及原理
Hadoop是大数据处理的基础框架,它通过MapReduce实现分布式计算。Hive是基于Hadoop的数据仓库工具,允许用户使用SQL查询Hadoop集群中的数据。HBase是一个NoSQL数据库,提供实时读写访问,适合大规模列式存储。Spark则是一个快速、通用的计算引擎,尤其适用于内存计算,可以显著提升数据分析的速度。
OLAP的实践简介——Kylin
Kylin的设计目标是让BI工具可以直接在Hadoop上执行SQL查询,无需将数据迁移到专门的分析数据库。它通过构建和存储预计算的立方体,降低了查询延迟。Kylin的工作流程包括定义Cube、构建Cube、查询Cube三个阶段。用户可以通过Kylin的Web界面创建和管理Cube,然后使用标准SQL查询数据,获取快速的分析结果。
总结
OLAP引擎是大数据分析的关键组成部分,它们通过优化数据结构和查询处理,支持复杂的商业智能和决策支持。在大数据环境下,如Kylin这样的分布式OLAP引擎为海量数据提供了高效的分析能力,使得实时和交互式的分析成为可能。了解这些原理和实践,对于构建高效的数据分析系统至关重要。
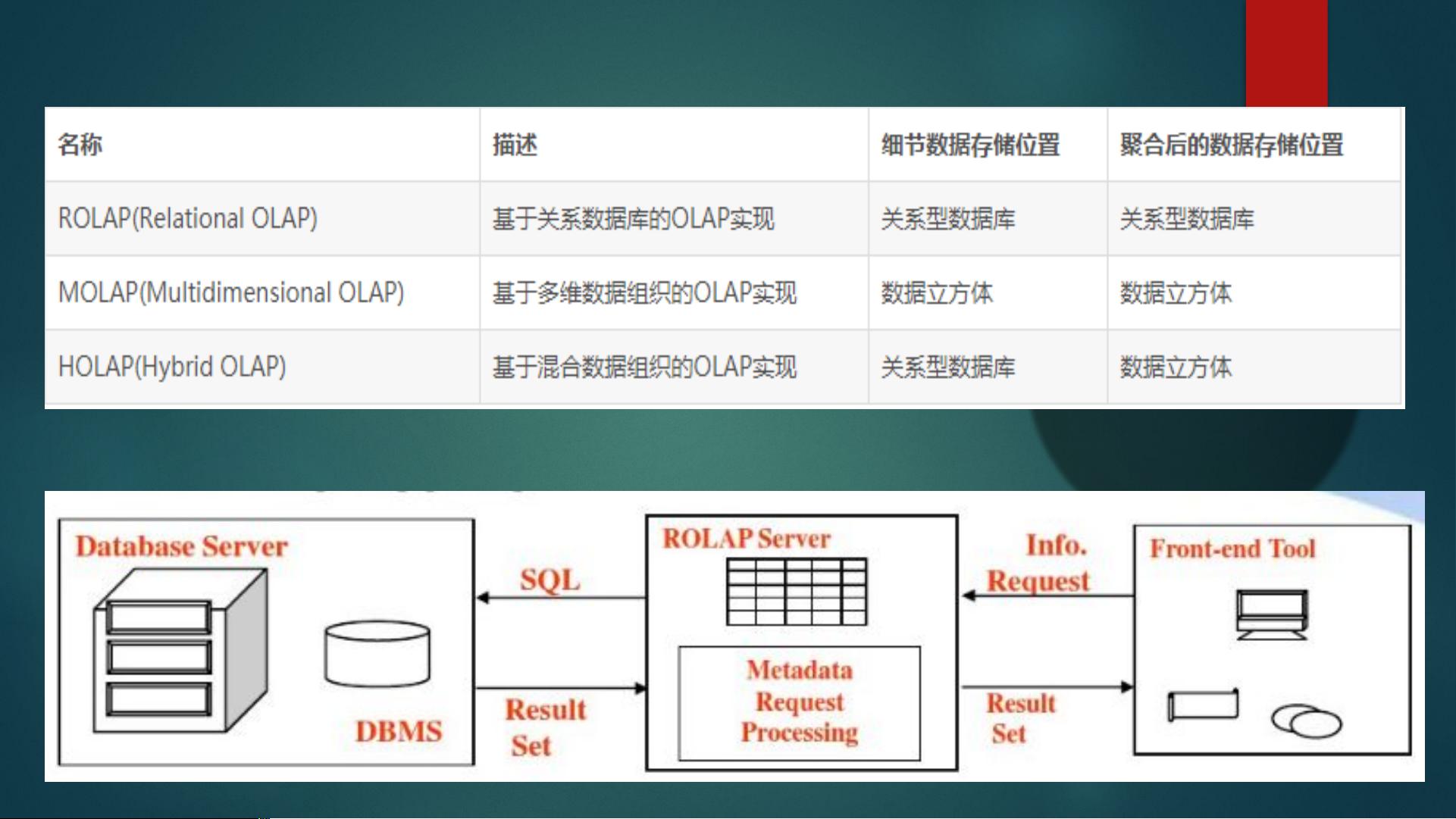
Olap 对比表格
ROLAP 拓扑图
剩余15页未读,继续阅读
2021-02-25 上传
2021-02-24 上传
2024-01-21 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

小二货007
- 粉丝: 22
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- WPF渲染层字符绘制原理探究及源代码解析
- 海康精简版监控软件:iVMS4200Lite版发布
- 自动化脚本在lspci-TV的应用介绍
- Chrome 81版本稳定版及匹配的chromedriver下载
- 深入解析Python推荐引擎与自然语言处理
- MATLAB数学建模算法程序包及案例数据
- Springboot人力资源管理系统:设计与功能
- STM32F4系列微控制器开发全面参考指南
- Python实现人脸识别的机器学习流程
- 基于STM32F103C8T6的HLW8032电量采集与解析方案
- Node.js高效MySQL驱动程序:mysqljs/mysql特性和配置
- 基于Python和大数据技术的电影推荐系统设计与实现
- 为ripro主题添加Live2D看板娘的后端资源教程
- 2022版PowerToys Everything插件升级,稳定运行无报错
- Map简易斗地主游戏实现方法介绍
- SJTU ICS Lab6 实验报告解析
