分布式架构演变:从单应用到分布式处理
109 浏览量
更新于2024-08-28
收藏 542KB PDF 举报
分布式架构演变
分布式架构是随着计算机系统规模变得越来越大,集中部署在一个或若干个大型机上的体系架构不能满足当今计算机系统所发展出来的一种架构形式。随着微型计算机的出现,廉价的PC机成为了各大企业IT架构的首选,分布式的处理方式越来越受到业界的青睐。
分布式架构的发展历史可以追溯到单应用架构阶段,当网站的初期也可以认为是互联网发展的早起,我们经常会在单机上跑我们所有的程序和软件。把所有软件和应用都部署在一台机器上,这样就完成一个简单系统的搭建,这个时候的讲究的是效率。
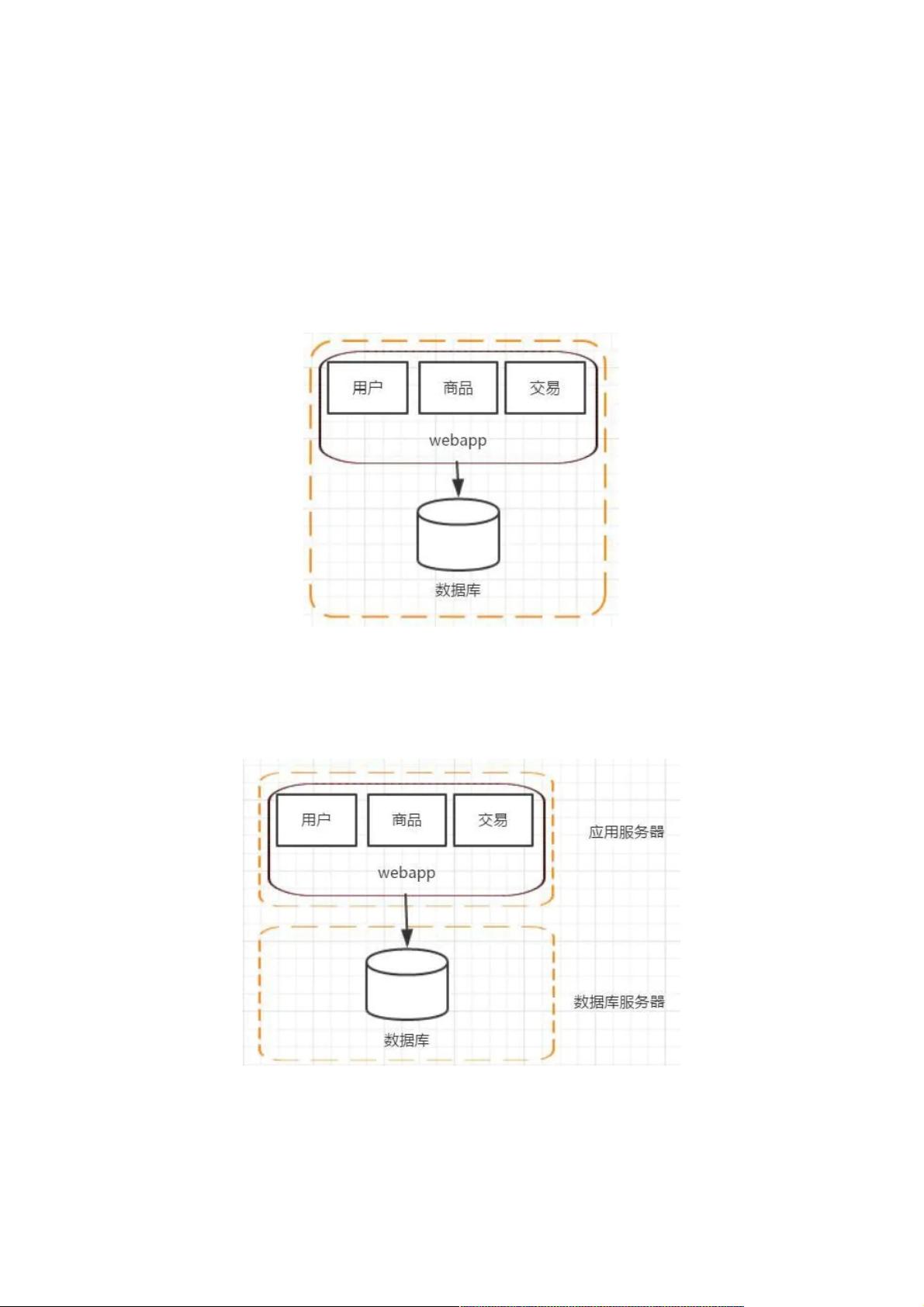
随着网站的上线,访问量逐步上升,服务器的负载慢慢提高,在服务器还没有超载的时候,我们应该做好规划,提升网站的负载能力。假如代码层面的优化已经没办法继续提高,在不提高单台机器的性能,增加机器是一个比较好的方式,投入产出比非常高。这个阶段增加机器的主要目的是将web服务器和数据库服务器拆分,这样不仅提高了单机的负载能力,也提高了容灾能力。
在应用服务器和数据库服务器分离阶段,我们可以增加应用服务器,通过应用服务器集群将用户请求分流到各个服务器中,从而继续提升负载能力。此时多台应用服务器之间没有直接的交互,他们都是依赖数据库各自对外提供服务。
架构发展到应用服务器集群阶段,各种问题也会慢慢呈现,比如用户请求由谁来转发到具体的应用服务器,这时候可能会出现下面的架构模型。为解决这些问题,我们可以使用负载均衡器、反向代理服务器等技术来实现服务器集群的负载均衡。
随着数据库压力变大时,那么怎么去提高数据库层面的负载呢?有了前面的思路以后,自然会想到增加服务器。但是假如我们单纯的把数据库一分为二,然后对于后续数据库的请求,分别负载到两台数据库服务器上,那么一定会造成数据库不统一的问题。所以我们一般先考虑读写分离的方式。
读写分离是指将数据库读取和写入操作分离到不同的服务器上,以提高数据库的性能和可扩展性。读写分离可以减少数据库的压力,提高系统的整体性能和可用性。
在读写分离阶段,我们可以使用搜索引擎来缓解读库的压力。数据库做读库的话,常常对模糊查找效率不是特别好,像电商类的网站,搜索是非常核心的功能,即便是做了读写分离,这个问题也不能有效解决。那么这个时候可以引入搜索引擎,例如Elasticsearch、Solr等,以提高搜索效率和性能。
分布式架构的演变是一个不断演进和完善的过程,从单应用架构到应用服务器和数据库服务器分离,再到应用服务器集群、读写分离等阶段,每个阶段都有其特点和解决方案。只有通过不断地学习和实践,才能更好地理解和掌握分布式架构的技术和原理。
实战案例实战案例——分布式架构演变分布式架构演变
前言
随着计算机系统规模变得越来越大,将所有的业务单元集中部署在一个或若干个大型机上的体系架构,已经越来越不能满足当
今计算机系统。同时,随着微型计算机的出现,越来越多廉价的PC机成为了各大企业IT架构的首选,分布式的处理方式越来
越受到业界的青睐。本文将介绍分布式架构的发展历史和分布式架构的一些相关概念。
下面以一个简单的电商系统为例,当数据量、访问量提升,观察这个系统可能会发生的结构变化。假如我们系统具备以下功
能:用户模块(用户注册和管理),商品模块(商品展示和管理),交易模块(创建交易及支付结算)。
一、单应用架构
网站的初期也可以认为是互联网发展的早起,我们经常会在单机上跑我们所有的程序和软件。把所有软件和应用都部署在一台
机器上,这样就完成一个简单系统的搭建,这个时候的讲究的是效率。
二、应用服务器和数据库服务器分离
随着网站的上线,访问量逐步上升,服务器的负载慢慢提高,在服务器还没有超载的时候,我们应该做好规划,提升网站的负
载能力。假如代码层面的优化已经没办法继续提高,在不提高单台机器的性能,增加机器是一个比较好的方式,投入产出比非
常高。这个阶段增加机器的主要目的是将web 服务器和数据库服务器拆分,这样不仅提高了单机的负载能力,也提高了容灾
能力。
三、应用服务器集群
随着访问量的继续增加,单台应用服务器已经无法满足需求。在假设数据库服务器还没有遇到性能问题的时候,我们可以增加
应用服务器,通过应用服务器集群将用户请求分流到各个服务器中,从而继续提升负载能力。此时多台应用服务器之间没有直
接的交互,他们都是依赖数据库各自对外提供服务。
下载后可阅读完整内容,剩余4页未读,立即下载
2023-09-25 上传
2023-10-27 上传
2023-12-16 上传
2023-07-02 上传
2023-08-24 上传
2023-10-12 上传
2023-08-01 上传
2023-05-24 上传
2023-03-26 上传

weixin_38503496
- 粉丝: 7
- 资源: 983
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++多态实现机制详解:虚函数与早期绑定
- Java多线程与异常处理详解
- 校园导游系统:无向图实现最短路径探索
- SQL2005彻底删除指南:避免重装失败
- GTD时间管理法:提升效率与组织生活的关键
- Python进制转换全攻略:从10进制到16进制
- 商丘物流业区位优势探究:发展战略与机遇
- C语言实训:简单计算器程序设计
- Oracle SQL命令大全:用户管理、权限操作与查询
- Struts2配置详解与示例
- C#编程规范与最佳实践
- C语言面试常见问题解析
- 超声波测距技术详解:电路与程序设计
- 反激开关电源设计:UC3844与TL431优化稳压
- Cisco路由器配置全攻略
- SQLServer 2005 CTE递归教程:创建员工层级结构
