Python实现决策树与随机森林:简单原理及信息熵应用
158 浏览量
更新于2024-09-04
1
收藏 182KB PDF 举报
"这篇文章主要介绍了Python中如何实现决策树和随机森林的简单原理,适合对机器学习感兴趣的读者参考。文章作者在学习过程中整理了相关知识,包括决策树的基本概念、优势,以及特征选择的关键——信息熵和互信息,并用一个简单的约会决策案例进行了说明。"
在机器学习领域,决策树是一种广泛应用的监督学习算法,尤其适用于分类问题。它通过学习数据集构建一棵树形结构,每个内部节点代表一个特征,每个分支代表一个特征值,而每个叶子节点则对应一个类别决策。决策树的优势在于模型易于理解和解释,能够直观地展示决策流程,并且预测效率高。
文章提到了决策树构建过程中的一个重要步骤——特征选择。特征选择决定了决策树的分支结构,直接影响模型的性能。在信息论中,信息熵被用来度量一个事件的不确定性,熵越大,表示事件的不确定性越高。而互信息则是衡量两个随机变量之间的相关性,如果一个变量可以显著减少另一个变量的不确定性,则它们之间存在较高互信息。
在构建决策树时,通常会选择能最大化信息增益(即互信息)的特征作为划分标准。信息增益是父节点的熵减去所有子节点条件熵的加权平均,它表示通过选择某个特征所能获得的信息减少。以文章中的约会决策为例,我们比较“长相”、“收入”和“身高”这三个特征的信息增益,选取增益最大的特征作为第一个决策节点。
随机森林是另一种基于决策树的集成学习方法,它通过构建多棵决策树并综合它们的预测结果来提高模型的准确性和鲁棒性。随机森林在决策树的基础上引入了两个主要改进:1) 在构建每棵树时,随机选择一部分特征进行分割,减少特征之间的共线性;2) 每棵树都基于不同的训练子集(Bootstrap抽样)构建,增加了模型的多样性。
在Python中,可以使用scikit-learn库来实现决策树和随机森林。scikit-learn提供了`DecisionTreeClassifier`和`RandomForestClassifier`类,用户只需提供训练数据和参数,库会自动完成模型构建、训练和预测。在实际应用中,需要注意调整决策树的深度、叶子节点最少样本数、特征选择策略等超参数,以优化模型性能。
总结起来,Python中的决策树和随机森林是强大的分类工具,它们利用信息熵和互信息进行特征选择,通过集成学习提升预测能力。了解这些基本原理和实现方法,对于理解和应用这些算法解决实际问题至关重要。
python实现决策树、随机森林的简单原理实现决策树、随机森林的简单原理
主要为大家详细介绍了python实现决策树、随机森林的简单原理,具有一定的参考价值,感兴趣的小伙伴们可
以参考一下
本文申明:此文为学习记录过程,中间多处引用大师讲义和内容。
一、概念一、概念
决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分
类。决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析;2)效率高,决策树只需要一次构建,
反复使用,每一次预测的最大计算次数不超过决策树的深度。
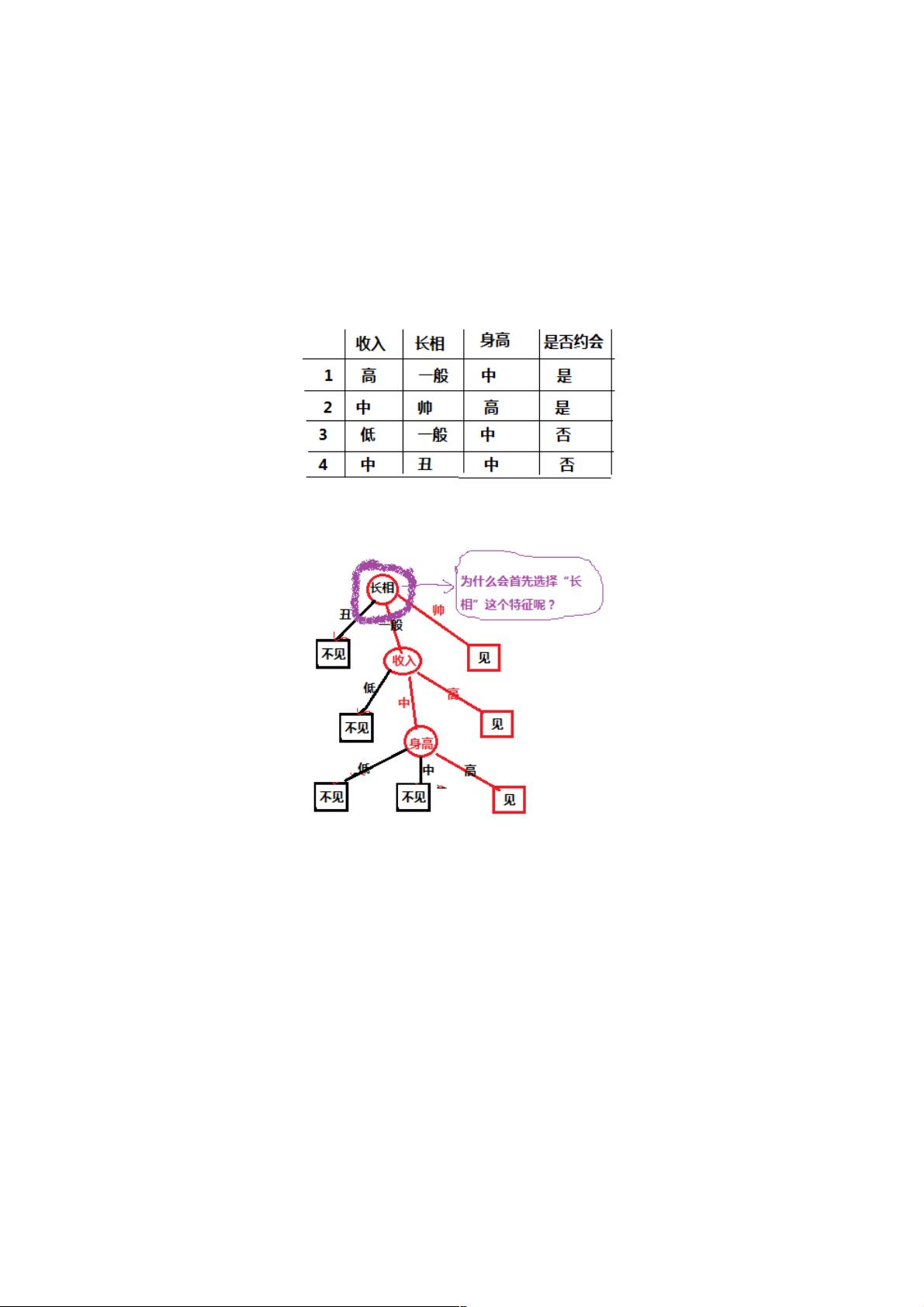
看了一遍概念后,我们先从一个简单的案例开始,如下图我们样本:
对于上面的样本数据,根据不同特征值我们最后是选择是否约会,我们先自定义的一个决策树,决策树如下图所示:
对于上图中的决策树,有个疑问,就是为什么第一个选择是“长相”这个特征,我选择“收入”特征作为第一分类的标准可以嘛?
下面我们就对构建决策树选择特征的问题进行讨论;在考虑之前我们要先了解一下相关的数学知识:
信息熵:熵代表信息的不确定性,信息的不确定性越大,熵越大;比如“明天太阳从东方升起”这一句话代表的信息我们可以
认为为0;因为太阳从东方升起是个特定的规律,我们可以把这个事件的信息熵约等于0;说白了,信息熵和事件发生的概率
成反比:数学上把信息熵定义如下:H(X)=H(P1,P2,…,Pn)=-∑P(xi)logP(xi)
互信息:指的是两个随机变量之间的关联程度,即给定一个随机变量后,另一个随机变量不确定性的削弱程度,因而互信息
取值最小为0,意味着给定一个随机变量对确定一另一个随机变量没有关系,最大取值为随机变量的熵,意味着给定一个随机
变量,能完全消除另一个随机变量的不确定性
现在我们就把信息熵运用到决策树特征选择上,对于选择哪个特征我们按照这个规则进行“哪个特征能使信息的确定性最大我
们就选择哪个特征”;比如上图的案例中;
第一步:假设约会去或不去的的事件为Y,其信息熵为H(Y);
第二步:假设给定特征的条件下,其条件信息熵分别为H(Y|长相),H(Y|收入),H(Y|身高)
第三步:分别计算信息增益(互信息):G(Y,长相) = I(Y,长相) = H(Y)-H(Y|长相) 、G(Y,) = I(Y,长相) = H(Y)-H(Y|长相)等
第四部:选择信息增益最大的特征作为分类特征;因为增益信息大的特征意味着给定这个特征,能很大的消除去约会还是不约
会的不确定性;
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-09-20 上传
2021-09-29 上传
2021-09-30 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38655767
- 粉丝: 3
- 资源: 923
 我的内容管理
展开
我的内容管理
展开







最新资源
- Chrome ESLint扩展:实时运行ESLint于网页脚本
- 基于 Webhook 的 redux 预处理器实现教程
- 探索国际CMS内容管理系统v1.1的新功能与应用
- 在Heroku上快速部署Directus平台的指南
- Folks Who Code官网:打造安全友好的开源环境
- React测试专用:上下文提供者组件实现指南
- RabbitMQ利用eLevelDB后端实现高效消息索引
- JavaScript双向对象引用的极简实现教程
- Bazel 0.18.1版本发布,Windows平台构建工具优化
- electron-notification-desktop:电子应用桌面通知解决方案
- 天津理工操作系统实验报告:进程与存储器管理
- 掌握webpack动态热模块替换的实现技巧
- 恶意软件ep_kaput: Etherpad插件系统破坏者
- Java实现Opus音频解码器jopus库的应用与介绍
- QString库:C语言中的高效动态字符串处理
- 微信小程序图像识别与AI功能实现源码
