强化学习基础:n步时序差分预测与应用
需积分: 0 104 浏览量
更新于2024-08-05
收藏 401KB PDF 举报
"这篇内容介绍了n步时序差分预测在强化学习中的应用,包括n步时序差分方法的概念、n步回报的定义以及在随机游走问题上的实践。文章使用了Python库numpy和matplotlib进行算法实现和结果可视化。"
在强化学习中,n步时序差分(n-step TD)方法是一种介于单步TD学习和蒙特卡洛方法之间的算法。它结合了一步更新的即时性和蒙特卡洛方法对完整轨迹的利用。在单步TD中,状态价值仅基于当前状态到下一个状态的转移进行更新,而n-step TD则考虑了从当前状态到未来n步的状态转移。这种方法允许学习者在每个时间步长内利用更远的未来信息,从而可能提高学习效率和收敛速度。
n步回报是n-step TD的核心概念,它是对传统即时回报的扩展。对于一个特定的n值,n步回报包含了从当前状态开始到第n个状态的累积折扣奖励。公式可以表示为:\( G_t^{(n)} = r_{t+1} + \gamma r_{t+2} + \gamma^2 r_{t+3} + \cdots + \gamma^{n-1} r_{t+n} \),其中\( \gamma \)是折扣因子,\( r_i \)是第i个时间步的即时奖励。通过这种方式,我们可以基于n步回报来更新状态的价值函数。
n-step TD的更新方法与单步TD类似,但使用了n步回报。更新规则通常为:\( V(s_t) \leftarrow V(s_t) + \alpha [G_t^{(n)} - V(s_t)] \),其中\( \alpha \)是学习率,\( V(s_t) \)是当前状态\( s_t \)的价值估计,\( G_t^{(n)} \)是n步回报。这个更新过程在每个时间步上执行,随着经验的积累,状态价值函数逐渐逼近真实值。
在随机游走问题的应用中,作者调整了之前问题的状态空间,从6个状态增加到了19个,其中0和19是终止状态,分别对应-1和1的回报。通过使用n-step TD算法,可以观察到算法在解决这种问题时的效果。在代码实现部分,定义了环境参数,如状态空间、初始状态、终端状态、折扣因子、真实价值函数等,并定义了一个名为`temporal_difference`的函数来执行n-step TD更新。
n-step TD方法是强化学习中一种重要的价值迭代策略,它在处理具有长期依赖性的任务时表现出色。通过调整n值,学习者可以在即时反馈和长期规划之间找到平衡,从而在不同的环境和任务中实现更有效和精确的学习。在实际应用中,选择合适的n值和优化学习参数是提高算法性能的关键。
强化学习基础篇(二十五)n步时序差分预测
1、n步时序差分方法
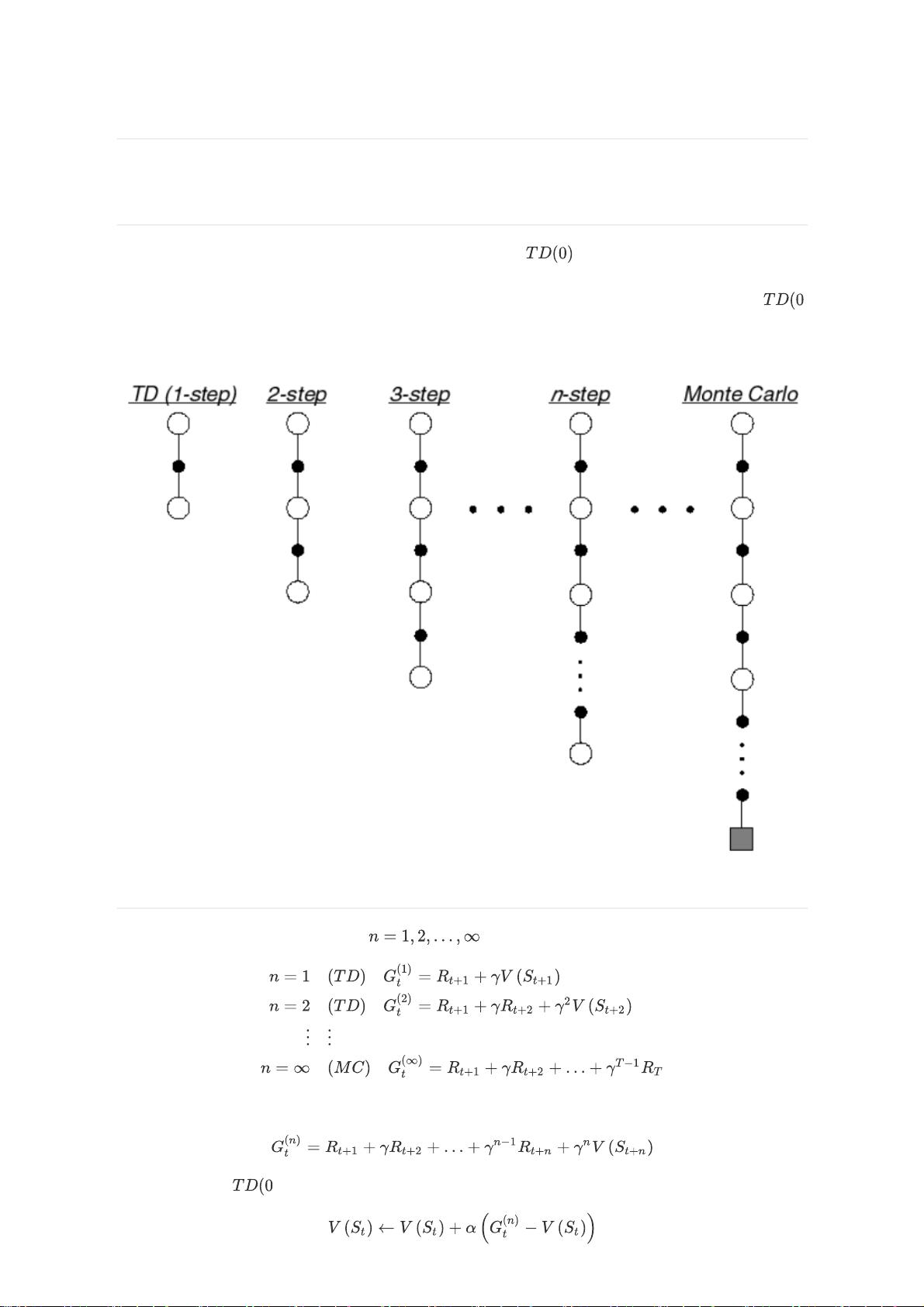
之前在《强化学习基础篇(十七)时间差分预测》所介绍的是 算法,其更新过程仅仅依赖于当前
状态向下走一步的情况,将走一步走后的状态价值用于bootstrap更新。而蒙特卡洛方法是根据当前状态
开始到终止状态的整个收益序列进行状态价值的更新。这节介绍的n步时序差分(n-step TD)是基于
)的一步更新与MC对整个序列进行更新的两个极端之间的算法。从n步时序差分方法的回溯图中,我们可
以看到每个n步方法都考虑了从当前状态向下走n步的情况。
2、n步回报
如果我们考虑如下的n取值下的回报( )
那么我们可以进行泛化定义n步回报为:
根据n步回报修改 的更新方法为:
下载后可阅读完整内容,剩余4页未读,立即下载
2021-01-06 上传
2023-07-13 上传
2024-06-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

宏馨
- 粉丝: 25
- 资源: 293
 我的内容管理
展开
我的内容管理
展开







最新资源
- StarModAPI: StarMade 模组开发的Java API工具包
- PHP疫情上报管理系统开发与数据库实现详解
- 中秋节特献:明月祝福Flash动画素材
- Java GUI界面RPi-kee_Pilot:RPi-kee专用控制工具
- 电脑端APK信息提取工具APK Messenger功能介绍
- 探索矩阵连乘算法在C++中的应用
- Airflow教程:入门到工作流程创建
- MIP在Matlab中实现黑白图像处理的开源解决方案
- 图像切割感知分组框架:Matlab中的PG-framework实现
- 计算机科学中的经典算法与应用场景解析
- MiniZinc 编译器:高效解决离散优化问题
- MATLAB工具用于测量静态接触角的开源代码解析
- Python网络服务器项目合作指南
- 使用Matlab实现基础水族馆鱼类跟踪的代码解析
- vagga:基于Rust的用户空间容器化开发工具
- PPAP: 多语言支持的PHP邮政地址解析器项目
