Hadoop HDFS NameNode重启优化策略与流程分析
PDF格式 | 679KB |
更新于2024-08-29
| 189 浏览量 | 举报
"HDFSNameNode重启优化 - 优化NameNode重启流程以提高Hadoop集群的可用性和可靠性,基于Hadoop-2.x和HAwithQJM架构。"
在Hadoop分布式文件系统(HDFS)中,NameNode是核心组件,负责管理文件系统的元数据,包括文件的命名空间(Namespace)和数据块映射(BlocksMap)。由于NameNode在内存中存储元数据,因此在某些情况下,例如参数调整或系统升级,需要对其进行重启。然而,NameNode的重启可能导致集群的可用性和可靠性下降,因为在此期间元数据可能会丢失。
NameNode重启的优化主要围绕以下几个方面:
1. **元数据持久化**:为了防止NameNode异常时元数据丢失,NameNode会定期进行CheckPoint,将Namespace的元数据写入FSImage文件中,同时,所有的修改操作会被记录在EditLog中。这样即使NameNode崩溃,也可以通过FSImage和EditLog恢复元数据。
2. **HAwithQJM架构**:在高可用性(HA)模式下,使用Quorum Journal Manager(QJM)的架构,NameNode有主备两个节点(Active NameNode和Standby NameNode)。在重启过程中,NameNode始终以SBN角色进行,依次执行加载FSImage、回放EditLog、可能的CheckPoint以及收集DataNode信息的步骤。
3. **EditLog回放**:在NameNode启动时,它会先加载最新的FSImage,然后回放自上次CheckPoint以来的所有EditLog条目,这些条目反映了对Namespace的修改。回放过程是确保NameNode状态与实际文件系统状态同步的关键步骤。
4. **CheckPoint策略**:并非每次NameNode重启都需要执行CheckPoint,这取决于系统配置和当前的元数据状态。在某些情况下,系统可能会选择合并FSImage和EditLog,形成一个新的FSImage,以减少EditLog的大小并避免过多的磁盘I/O。
5. **DataNode交互**:在NameNode重启后,它需要重新收集所有DataNode的注册信息和数据块报告,以重建BlocksMap。这一过程可能耗时较长,特别是当集群规模较大时,优化此阶段可以显著缩短NameNode的启动时间。
6. **参数调优**:Hadoop的配置参数对NameNode的重启性能有很大影响。例如,`fs.checkpoint.period`定义了CheckPoint的频率,而`fs.checkpoint.size`决定了何时触发基于大小的CheckPoint。合理调整这些参数可以平衡元数据安全性和系统性能。
7. **监控与故障检测**:实施有效的监控机制,能够及时发现NameNode的异常并采取行动,例如自动切换到备用NameNode。同时,对于NameNode的重启过程,也需要有良好的日志记录和故障排查工具。
8. **系统升级策略**:在进行系统升级或应用补丁时,应尽可能减少对NameNode的影响。例如,可以利用滚动升级(Rolling Upgrade)来逐步更新各个DataNode,而不是一次性重启NameNode。
通过以上策略和方法,可以显著优化NameNode的重启过程,提高Hadoop集群的稳定性和可用性,确保数据的安全和业务的连续性。在实践中,应根据具体集群规模、工作负载和业务需求来定制优化方案。
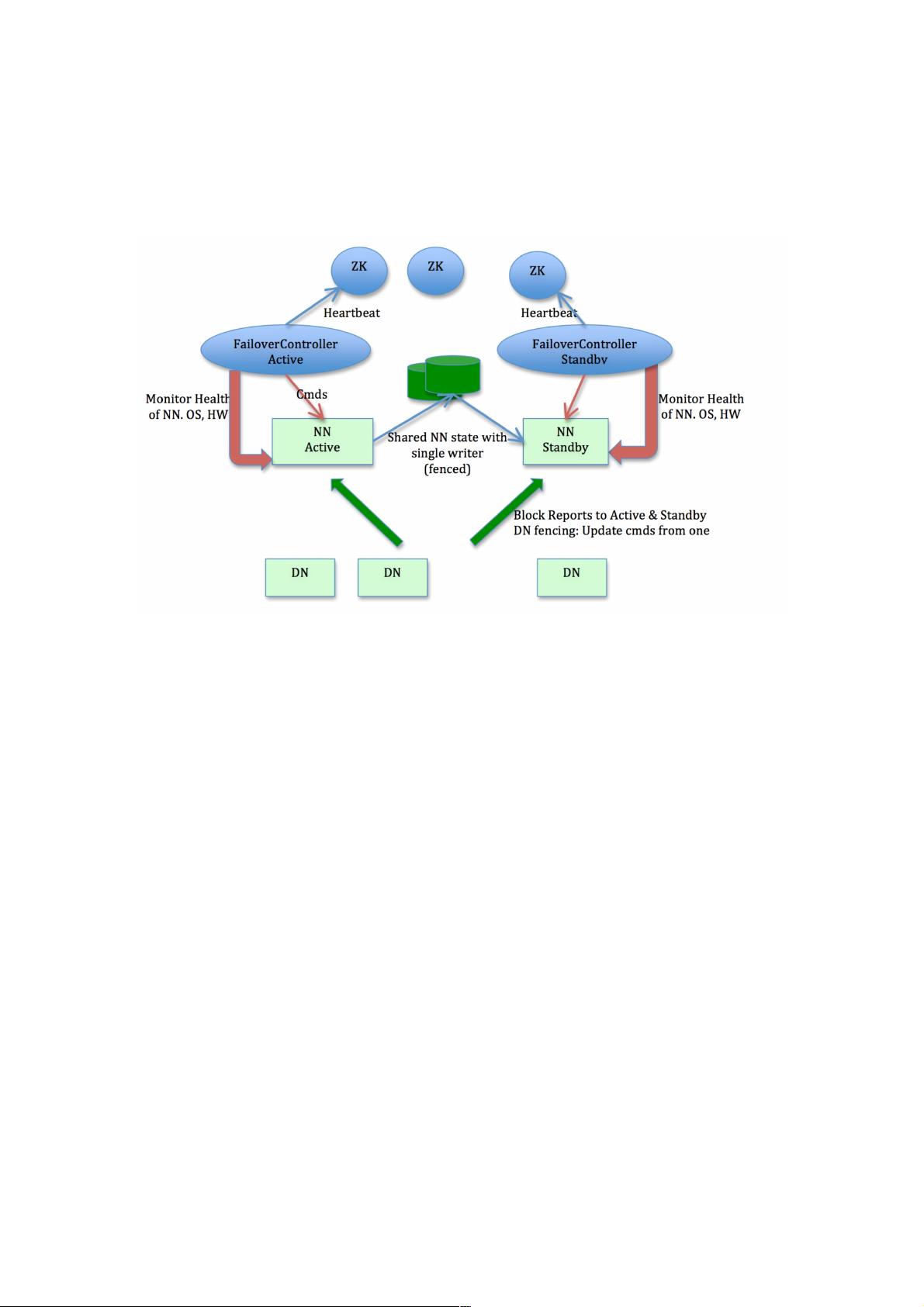
HDFSNameNode重启优化重启优化
一、背景
在Hadoop集群整个生命周期里,由于调整参数、Patch、升级等多种场景需要频繁操作NameNode重启,不论采用何种架
构,重启期间集群整体存在可用性和可靠性的风险,所以优化NameNode重启非常关键。
本文基于Hadoop-2.x和HA with QJM社区架构和系统设计(如图1所示),通过梳理NameNode重启流程,并在此基础上,阐
述对NameNode重启优化实践。
图1 HDFS HA with QJM架构图示
二、NameNode重启流程
在HDFS的整个运行期里,所有元数据均在NameNode的内存集中管理,但是由于内存易失特性,一旦出现进程退出、宕机等
异常情况,所有元数据都会丢失,给整个系统的数据安全会造成不可恢复的灾难。为了更好的容错能力,NameNode会周期
进行CheckPoint,将其中的一部分元数据(文件系统的目录树Namespace)刷到持久化设备上,即二进制文件FSImage,这
样的话即使NameNode出现异常也能从持久化设备上恢复元数据,保证了数据的安全可靠。
但是仅周期进行CheckPoint仍然无法保证所有数据的可靠,如前次CheckPoint之后写入的数据依然存在丢失的问题,所以将
两次CheckPoint之间对Namespace写操作实时写入EditLog文件,通过这种方式可以保证HDFS元数据的绝对安全可靠。
事实上,除Namespace外,NameNode还管理非常重要的元数据BlocksMap,描述数据块Block与DataNode节点之间的对应
关系。NameNode并没有对这部分元数据同样操作持久化,原因是每个DataNode已经持有属于自己管理的Block集合,将所有
DataNode的Block集合汇总后即可构造出完整BlocksMap。
HA with QJM架构下,NameNode的整个重启过程中始终以SBN(StandbyNameNode)角色完成。与前述流程对应,启动过
程分以下几个阶段:
加载FSImage;
回放EditLog;
执行CheckPoint(非必须步骤,结合实际情况和参数确定,后续详述);
收集所有DataNode的注册和数据块汇报。
默认情况下,NameNode会保存两个FSImage文件,与此对应,也会保存对应两次CheckPoint之后的所有EditLog文件。一般
来说,NameNode重启后,通过对FSImage文件名称判断,选择加载最新的FSImage文件及回放该CheckPoint之后生成的所
有EditLog,完成后根据加载的EditLog中操作条目数及距上次CheckPoint时间间隔(后续详述)确定是否需要执行
CheckPoint,之后进入等待所有DataNode注册和元数据汇报阶段,当这部分数据收集完成后,NameNode的重启流程结束。
从线上NameNode历次重启时间数据看,各阶段耗时占比基本接近如图2所示。
下载后可阅读完整内容,剩余6页未读,立即下载
相关推荐




2 浏览量

6 浏览量


weixin_38670707
- 粉丝: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- C++ STL编程指南:设计组件解析
- 网站数据加密技术解析:DES、三重DES与RSA算法
- 单片机实验:LED闪烁灯实现与延时程序设计
- ABAP开发中常见问题及表结构查询方法
- RESTful HTTP应用实践与关键原则解析
- Java初学者指南:抽象类与接口解析
- CA3140A高增益运算放大器:集成MOSFET与双极晶体管的高性能解决方案
- 提升效率:Eclipse快捷键大全
- ActionScript 3.0 动画基础教程:从入门到精通
- AVR单片机实现的数字式SF6气体密度继电器设计
- ViSAGE:社会群体演化模拟与分析虚拟实验室
- Spring整合Struts与Hibernate:业务系统开发实践
- ActionScript 3.0 Cookbook 中文版:权威指南
- 信息技术在教务管理中的应用:Visual Basic6.0环境下的学生管理系统
- DIV+CSS学习难点实战经验梳理
- EJB设计模式解析:门面模式的应用与优势
