少标签学习:模仿人脑的高效图像分类法
需积分: 50 101 浏览量
更新于2024-07-15
收藏 1.42MB PDF 举报
少标签数据学习(Learning with Few Labeled Data)是一种人工智能领域的研究方法,它关注在数据标记极度有限的情况下,模型如何高效地进行新类别或任务的学习。人类的视觉系统为我们提供了灵感,比如我们能够仅凭少数样本就分辨出有毒蘑菇与可食用蘑菇,这是因为我们的大脑能够利用之前积累的大量经验进行泛化。
研究主要聚焦于三种图像分类模式:
1. 高样本量(High-shot regime):通常指每个类别有100到1000个样本,这是传统机器学习的典型场景,有足够的数据用于训练模型,使其在各类任务中表现良好。
2. 低样本量(Low-shot regime):极端情况下,如每类只有10个样本,这是一个更具挑战性的领域,因为模型需要从少量标注信息中提取足够的特征来区分不同的类别。
3. 极端低样本量(Extremely low-shot regime):即单样本或者极少数样本,这是最艰难的挑战,模型必须依靠非常有限的先验知识和学习能力来应对新的类别。
问题设定的核心是将训练数据分为许多小任务,比如识别汽车、猫、狗和飞机等,这些任务提供了丰富的多样性。当面临新的任务,例如识别草莓时,会涉及到两个关键参数:“ways”(类别数量)和“shots”(每个类别中的标签样本数)。模型需要在训练阶段学习到如何适应这些不同的任务分布,并在面临未知类别时,仅依赖于少量的标签数据进行推断。
少标签数据学习涉及的主要技术包括但不限于:迁移学习(Transfer Learning),其中模型从大规模预训练任务中获取通用特征,然后在新任务上微调;元学习(Meta-Learning),通过模拟多个小任务来提高模型对新任务的快速适应能力;以及基于深度学习的方法,如深度神经网络的元学习策略,如MAML(Model-Agnostic Meta-Learning)和FSL(Few-Shot Learning)。
此外,一个重要的视角是将表示学习(Representation Learning)看作一个热力学过程,这意味着模型不仅追求优化预测性能,还关注通过学习过程优化内部表示,使得在数据稀缺的情况下也能保持良好的泛化能力。这通常涉及到理解如何最大化模型的效率和稳定性,即使在面临缺乏标注数据的条件下。
少标签数据学习是一个极具挑战性但又至关重要的研究方向,它推动了AI在资源受限环境下的智能扩展,如物联网设备、移动应用和实时决策系统的实际应用中发挥更大的作用。随着数据收集和标注成本的上升,研究者们将继续探索如何在有限的数据条件下构建更聪明、更灵活的模型。
5
A flavor of current few-shot algorithms
Meta-learning forms the basis for almost all current algorithms. Here’s
one successful instantiation.
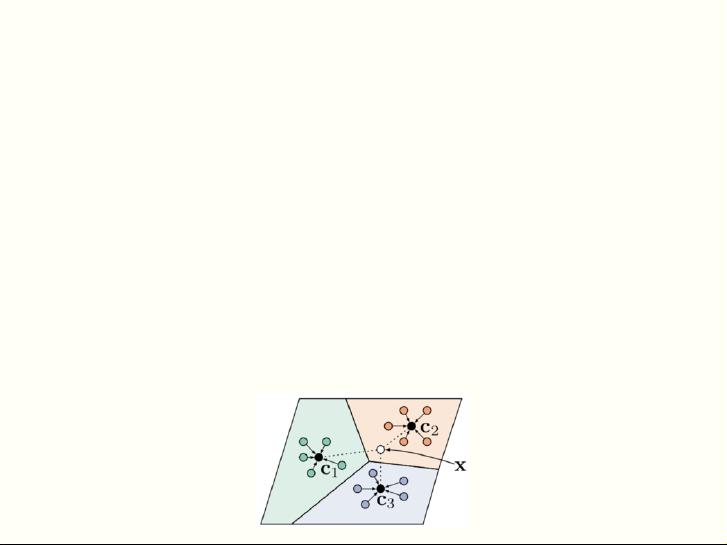
Prototypical Networks [Snell et al., 2017]
– Collect a meta-training set, this consists of a large number of
related tasks
– Train one model on all these tasks to ensure that the clustering of
features of this model correctly classifies the task
– If the test task comes from the same distribution as the meta-training
tasks, we can use the clustering on the new task to classify new classes
剩余53页未读,继续阅读
2018-05-10 上传
2018-06-12 上传
2020-07-18 上传
2019-01-09 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-05-11 上传

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
