Pravega:Flink实时处理的理想搭档,解决大数据痛点
10 浏览量
更新于2024-08-27
收藏 723KB PDF 举报
数据存储层有着极高的要求,它需要能够支持实时读写,同时也能够持久化大量历史数据。传统的消息队列系统如Kafka虽然擅长处理实时数据,但并不适合长期存储,而批处理系统则专注于历史数据分析,但响应速度较慢。在这种背景下,DellEMC研发了Pravega,一个专为流式数据设计的存储系统,旨在解决上述痛点。
Pravega简介
Pravega是DellEMC推出的一种新型的、高性能的、无界数据流存储系统。它的核心目标是提供一种统一的存储解决方案,既能满足实时流处理的需求,又能支持长时间的历史数据查询。Pravega的设计理念是将数据流作为第一类公民,强调数据的连续性,而非离散的消息。这种设计使得Pravega在处理大规模实时数据流时表现出色,同时具备高效的历史数据检索能力。
Pravega的进阶特性
1. **无界数据流**:Pravega支持无限长度的数据流,这意味着它可以存储无限量的历史数据,无需像Kafka那样定期删除旧数据。
2. **细粒度一致性**:Pravega提供了强一致性的读写保证,确保数据的实时性和准确性。
3. **可扩展性**:Pravega通过水平扩展来应对数据量的增长,能够轻松处理PB级别的数据。
4. **低延迟**:设计优化使得Pravega在数据读写上具有极低的延迟,适合实时分析和决策。
5. **弹性**:Pravega的分布式架构允许在不影响服务的情况下添加或移除节点,确保系统的高可用性和容错性。
6. **集成性**:Pravega与Apache Flink等实时处理引擎紧密集成,简化了实时流处理的工作流程。
车联网使用场景
在车联网的应用场景中,Pravega可以发挥其优势。车辆产生的海量传感器数据可以实时写入Pravega,进行实时分析,如交通流量监测、驾驶行为分析等。同时,这些数据可以长期保存,用于后续的历史数据分析,如故障预测、维护规划等。通过与Flink的结合,Pravega可以实现实时流处理和历史数据查询的一体化,避免了Lambda架构中的重复计算和延迟问题。
Flink与Pravega的结合
Apache Flink是一款强大的流处理引擎,它支持状态管理和窗口计算,非常适合实时数据分析。当与Pravega结合时,Flink可以直接从Pravega读取数据流,进行实时计算,同时Pravega可以作为Flink的持久化状态存储,确保状态的一致性和可靠性。这种组合使得实时分析不仅能够快速响应,还能结合历史数据,提供更为准确的结果。
Pravega的出现是对传统大数据处理架构的一种革新,它通过提供一种统一的流式存储解决方案,弥补了Lambda架构的不足,降低了数据冗余,提升了处理效率,并且与Flink等实时处理工具的无缝对接,进一步推动了实时分析领域的进步。对于那些需要处理大量实时数据并进行历史分析的企业,Pravega是一个极具吸引力的选择。
Flink完美搭档:数据存储层上的完美搭档:数据存储层上的Pravega
本文将从大数据架构变迁历史,Pravega 简介,Pravega 进阶特性以及车联网使用场景这四个方面介绍 Pravega,重点介绍
DellEMC 为何要研发 Pravega,Pravega 解决了大数据处理平台的哪些痛点以及与 Flink 结合会碰撞出怎样的火花。
大数据架构变迁
Lambda 架构之痛
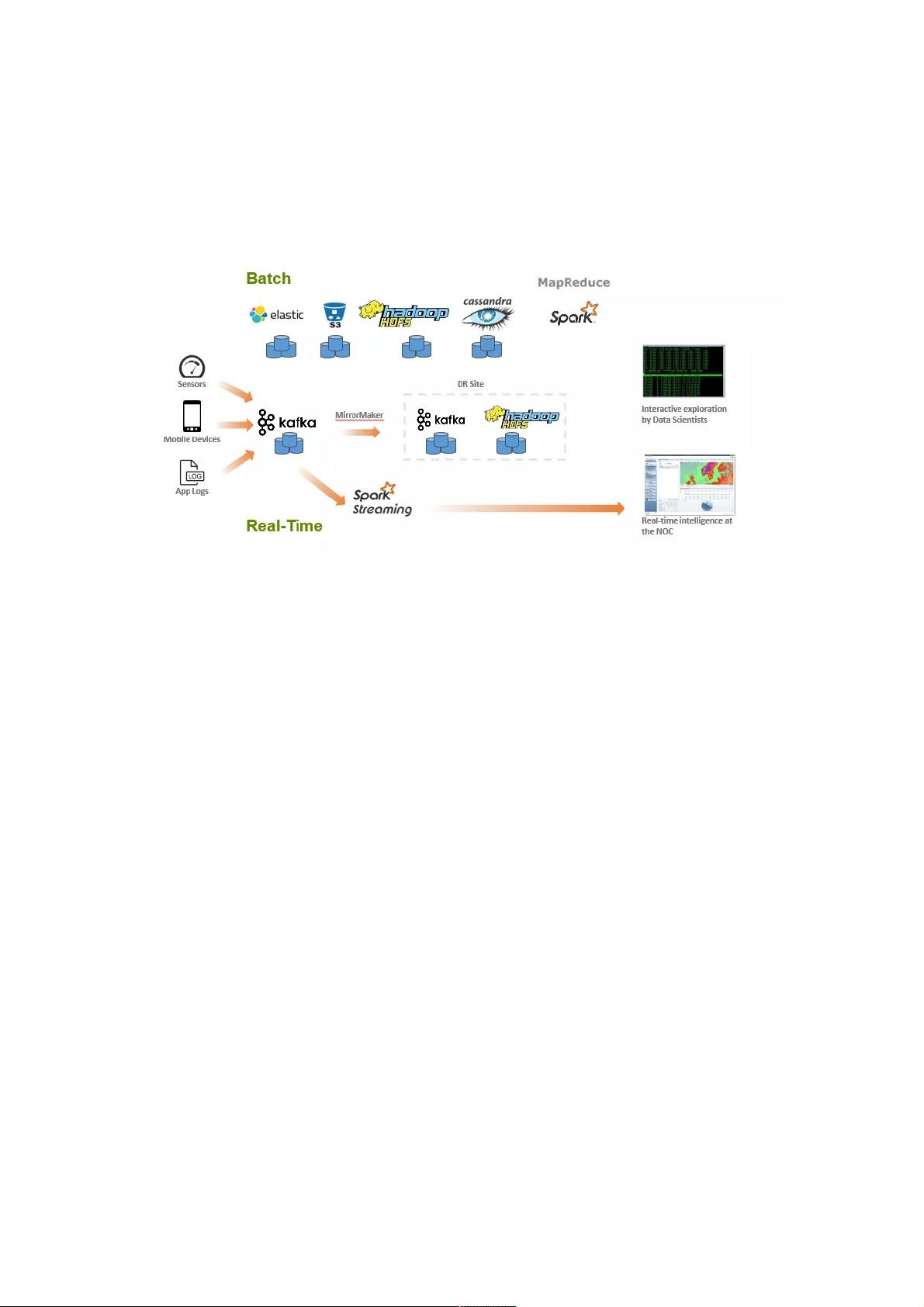
如何有效地提取和提供数据,是大数据处理应用架构是否成功的关键之处。由于处理速度和频率的不同,数据的摄取需要通过
两种策略来进行。上图就是典型的 Lambda架构:把大数据处理架构分为批处理和实时流处理两套独立的计算基础架构。
对于实时处理来说,来自传感器,移动设备或者应用日志的数据通常写入消息队列系统(如 Kafka), 消息队列负责为流处理应
用提供数据的临时缓冲。然后再使用 Spark Streaming 从 Kafka 中读取数据做实时的流计算。但由于 Kafka 不会一直保存历
史数据,因此如果用户的商业逻辑是结合历史数据和实时数据同时做分析,那么这条流水线实际上是没有办法完成的。因此为
了补偿,需要额外开辟一条批处理的流水线,即图中" Batch "部分。
对于批处理这条流水线来说,集合了非常多的的开源大数据组件如 ElasticSearch, Amazon S3, HDFS, Cassandra 以及 Spark
等。主要计算逻辑是是通过 Spark 来实现大规模的 Map-Reduce 操作,优点在于结果比较精确,因为可以结合所有历史数据
来进行计算分析,缺点在于延迟会比较大。
这套经典的大数据处理架构可以总结出三个问题:
两条流水线处理的延迟相差较大,无法同时结合两条流水线进行迅速的聚合操作,同时结合历史数据和实时数据的处理性能低
下。
数据存储成本大。而在上图的架构中,相同的数据会在多个存储组件中都存在一份或多份拷贝,数据的冗余无疑会大大增加企
业客户的成本。并且开源存储的数据容错和持久化可靠性一直也是值得商榷的地方,对于数据安全敏感的企业用户来说,需要
严格保证数据的不丢失。
重复开发。同样的处理流程被两条流水线进行了两次,相同的数据仅仅因为处理时间不同而要在不同的框架内分别计算一次,
无疑会增加数据开发者重复开发的负担。
流式存储的特点
在正式介绍 Pravega 之前,首先简单谈谈流式数据存储的一些特点。
如果我们想要统一流批处理的大数据处理架构,其实对存储有混合的要求。
下载后可阅读完整内容,剩余8页未读,立即下载
2023-03-21 上传
2022-05-08 上传
2021-05-26 上传
2021-02-05 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38528086
- 粉丝: 2
- 资源: 921
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
