HBase检索优化:列族、Rowkey与性能提升策略
86 浏览量
更新于2024-09-04
收藏 321KB PDF 举报
"本文介绍了HBase数据库的特性以及检索性能优化策略,强调了HBase在非结构化数据存储中的应用,并概述了其与HDFS、MapReduce、ZooKeeper、Pig、Hive和Sqoop的集成关系。文章还讨论了HBase的Rowkey、ColumnFamily、Cell和Timestamp的概念,以及Region和Store的存储结构。"
HBase是一种针对大规模非结构化数据存储设计的分布式数据库,其设计理念源于Google的BigTable。这个系统主要依赖于Apache Hadoop的组件,如HDFS提供底层存储,MapReduce负责处理计算任务,而ZooKeeper用于协调服务和故障转移。此外,Pig和Hive提供了高级语言接口,使得HBase可以进行复杂的数据统计,如多表join操作,而Sqoop则用于将关系型数据库的数据导入到HBase。
HBase的数据模型不同于传统的SQL数据库,它不支持WHERE条件查询或ORDER BY操作,但可以通过Rowkey进行高效检索。Rowkey是HBase中唯一标识一行数据的键,数据根据Rowkey进行排序存储。数据访问通常包括单行键访问、行键范围访问和全表扫描。为了优化检索性能,设计良好的Rowkey至关重要,因为它直接影响数据分布和查找效率。
ColumnFamily是HBase中的列族概念,数据的存储和管理在列族级别进行,每个列都有一个列族前缀。Cell是数据存储的最小单元,由行键、列族和时间戳唯一确定,其值以字节形式存储。时间戳用于区分同一单元的不同版本,新版本的数据会按时间戳倒序排列。
HBase的数据物理存储分为多个Region,Region随着数据增长自动分裂,每个Region包含一个或多个ColumnFamily。Region按照ColumnFamily进一步划分为Store,每个Store包含内存中的memstore(临时存储新写入的数据)和磁盘上的HFile(持久化存储)。这种结构允许HBase在数据读写时提供高性能。
为了优化HBase的性能,可以采取以下策略:
1. Rowkey设计:设计紧凑且具有高查询效率的Rowkey,避免热点现象,确保数据均匀分布。
2. ColumnFamily管理:合理规划列族,减少不必要的列族和列,降低IO压力。
3. 合理设置Region大小:避免Region过小导致的过多RegionServer负载,或Region过大导致的慢查询。
4. 调整memstore和HFile:控制memstore的大小和 flush策略,平衡内存和磁盘的使用。
5. 使用布隆过滤器和压缩:减少无效的磁盘访问,节省存储空间。
6. 负载均衡:根据服务器负载和Region大小调整Region分配,确保均衡。
7. 监控和调优:定期监控系统性能,根据实际情况调整配置参数。
通过理解HBase的基本原理和这些优化策略,可以有效地提高HBase的检索性能,满足大数据场景下的高效数据处理需求。
HBase 数据库检索性能优化策略数据库检索性能优化策略
HBase 数据表介绍
HBase 数据库是一个基于分布式的、面向列的、主要用于非结构化数据存储用途的开源数据库。其设计思路来源于
Google 的非开源数据库”BigTable”。
HDFS 为 HBase 提供底层存储支持,MapReduce 为其提供计算能力,ZooKeeper 为其提供协调服务和 failover(失效转
移的备份操作)机制。Pig 和 Hive 为 HBase 提供了高层语言支持,使其可以进行数据统计(可实现多表 join 等),Sqoop 则
为其提供 RDBMS 数据导入功能。
HBase 不能支持 where 条件、Order by 查询,只支持按照主键 Rowkey 和主键的 range 来查询,但是可以通过 HBase
提供的 API 进行条件过滤。
HBase 的 Rowkey 是数据行的标识,必须通过它进行数据行访问,目前有三种方式,单行键访问、行键范围访问、全表
扫描访问。数据按行键的方式排序存储,依次按位比较,数值较大的排列在后,例如 int 方式的排序:
1,10,100,11,12,2,20…,906,…。
ColumnFamily 是“列族”,属于 schema 表,在建表时定义,每个列属于一个列族,列名用列族作为前缀“ColumnFamily:
qualifier”,访问控制、磁盘和内存的使用统计都是在列族层面进行的。
Cell 是通过行和列确定的一个存储单元,值以字节码存储,没有类型。
Timestamp 是区分不同版本 Cell 的索引,64 位整型。不同版本的数据按照时间戳倒序排列,新的数据版本排在前面。
Hbase 在行方向上水平划分成 N 个 Region,每个表一开始只有一个 Region,数据量增多,Region 自动分裂为两个,不
同 Region 分布在不同 Server 上,但同一个不会拆分到不同 Server。
Region 按 ColumnFamily 划分成 Store,Store 为小存储单元,用于保存一个列族的数据,每个 Store 包括内存中的
memstore 和持久化到 disk 上的 HFile。
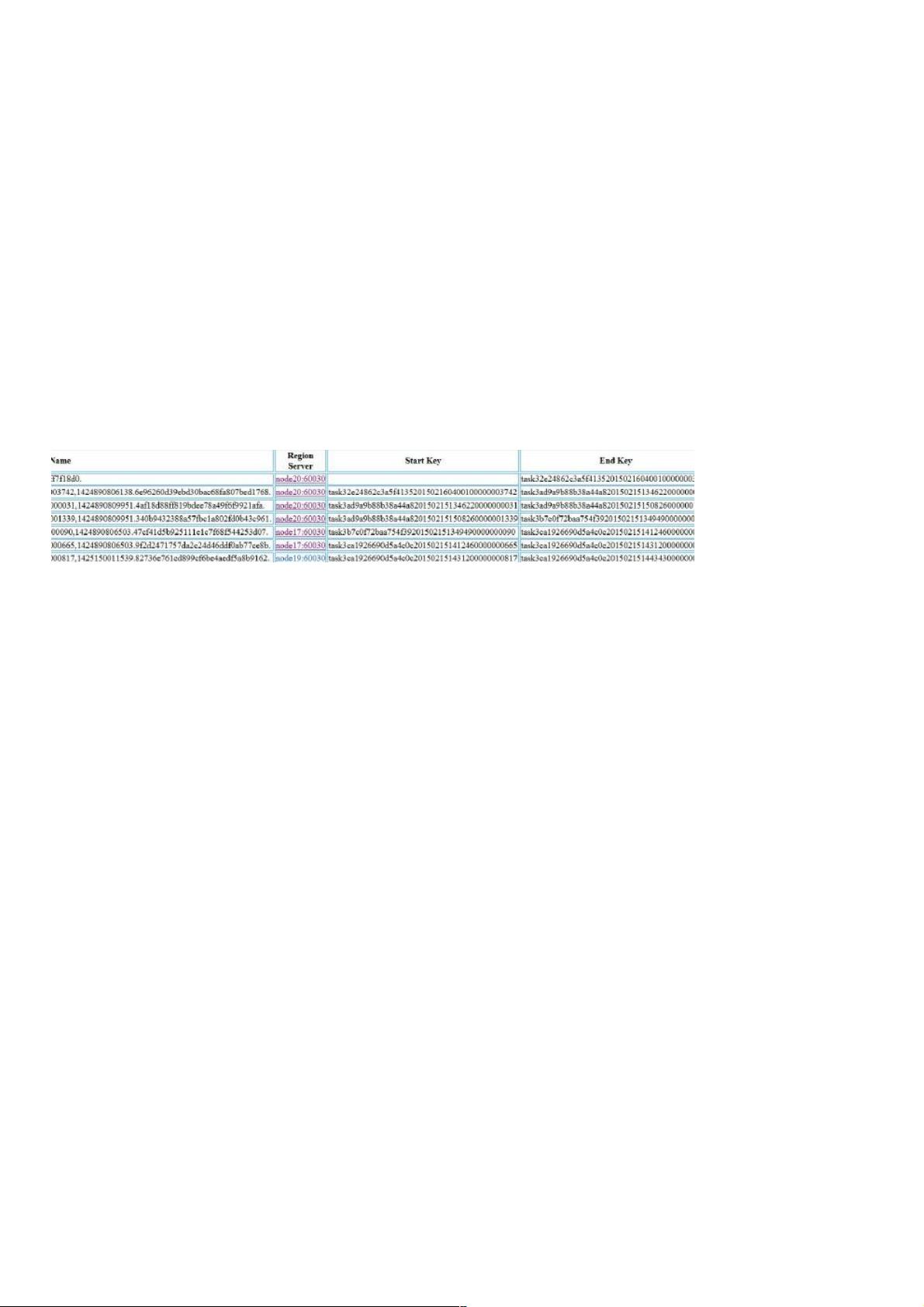
图 1 是 HBase 数据表的示例,数据分布在多台节点机器上面。
HBase 调用 API 示例
类似于操作关系型数据库的 JDBC 库,HBase client 包本身提供了大量可以供操作的 API,帮助用户快速操作 HBase 数
据库。提供了诸如创建数据表、删除数据表、增加字段、存入数据、读取数据等等接口。清单 1 提供了一个作者封装的工具
类,包括操作数据表、读取数据、存入数据、导出数据等方法。
清单 1.HBase API 操作工具类代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class HBaseUtil {
private Configuration conf = null;
private HBaseAdmin admin = null;
protected HBaseUtil(Configuration conf) throws IOException {
this.conf = conf;
this.admin = new HBaseAdmin(conf);
}
public boolean existsTable(String table)
throws IOException {
return admin.tableExists(table);
}
public void createTable(String table, byte[][] splitKeys, String… colfams)
throws IOException {
HTableDescriptor desc = new HTableDescriptor(table);
for (String cf : colfams) {
HColumnDescriptor coldef = new HColumnDescriptor(cf);
desc.addFamily(coldef);
下载后可阅读完整内容,剩余6页未读,立即下载
2017-11-03 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38678498
- 粉丝: 3
- 资源: 915
 我的内容管理
展开
我的内容管理
展开







最新资源
- StarModAPI: StarMade 模组开发的Java API工具包
- PHP疫情上报管理系统开发与数据库实现详解
- 中秋节特献:明月祝福Flash动画素材
- Java GUI界面RPi-kee_Pilot:RPi-kee专用控制工具
- 电脑端APK信息提取工具APK Messenger功能介绍
- 探索矩阵连乘算法在C++中的应用
- Airflow教程:入门到工作流程创建
- MIP在Matlab中实现黑白图像处理的开源解决方案
- 图像切割感知分组框架:Matlab中的PG-framework实现
- 计算机科学中的经典算法与应用场景解析
- MiniZinc 编译器:高效解决离散优化问题
- MATLAB工具用于测量静态接触角的开源代码解析
- Python网络服务器项目合作指南
- 使用Matlab实现基础水族馆鱼类跟踪的代码解析
- vagga:基于Rust的用户空间容器化开发工具
- PPAP: 多语言支持的PHP邮政地址解析器项目
