"大规模发现网络服务的爬虫引擎WSCE及其效率与挑战"
41 浏览量
更新于2024-01-10
收藏 607KB DOC 举报
本文讨论了在多个UDDI商业注册表(UBR)中有效访问和发现Web服务的问题。随着这些注册表的规模和数量的增加,跨多个UBR探索Web服务的能力变得越来越具有挑战性。随着Web服务的不断增加,寻找一个或多个服务注册表中合适的Web服务变得越来越困难。
为了解决这一挑战,作者提出了一个称为WSCE(Web服务爬虫引擎)的系统。WSCE通过使用基于事件驱动和分布式的架构,实现了跨多个UBR的Web服务的自动发现和访问。该系统具有以下特点:
首先,WSCE利用分布式爬取方法,能够同时在多个UBR上执行并行爬取操作。这种并行化的策略可以提高系统的性能和效率,从而加快Web服务的发现速度。
其次,WSCE采用了基于事件驱动的架构,其中爬虫引擎会订阅来自UBR的事件通知。当UBR中的Web服务发生变化时,爬虫引擎会根据这些事件通知来更新自己的服务库。这种事件驱动的机制可以实现实时的Web服务发现和更新,保证了WSCE系统的及时性和准确性。
此外,WSCE还提供了一个多功能的查询界面,用户可以根据自己的需求进行高级查询操作。用户可以指定搜索条件,如服务名称、所在地区、关键词等,从而精确地定位到所需的Web服务。这个查询界面可以大大提高用户的搜索效率和准确性。
最后,WSCE还提供了一些管理功能,如服务监控和系统日志等。管理员可以通过这些功能对WSCE系统进行监控和调整,保证系统的稳定性和可靠性。
在实验中,作者使用了真实的UBR数据集来评估WSCE系统的性能。实验结果表明,WSCE系统能够在多个UBR上快速、准确地发现Web服务,同时具有较高的扩展性和可靠性。
综上所述,WSCE是一个用于大规模发现Web服务的爬虫引擎,通过使用分布式和事件驱动的架构,实现了跨多个UBR的Web服务的自动发现和访问。该系统具有高性能、高效率、实时性和准确性等优点,可以为用户提供便捷、高效的Web服务发现和访问功能。
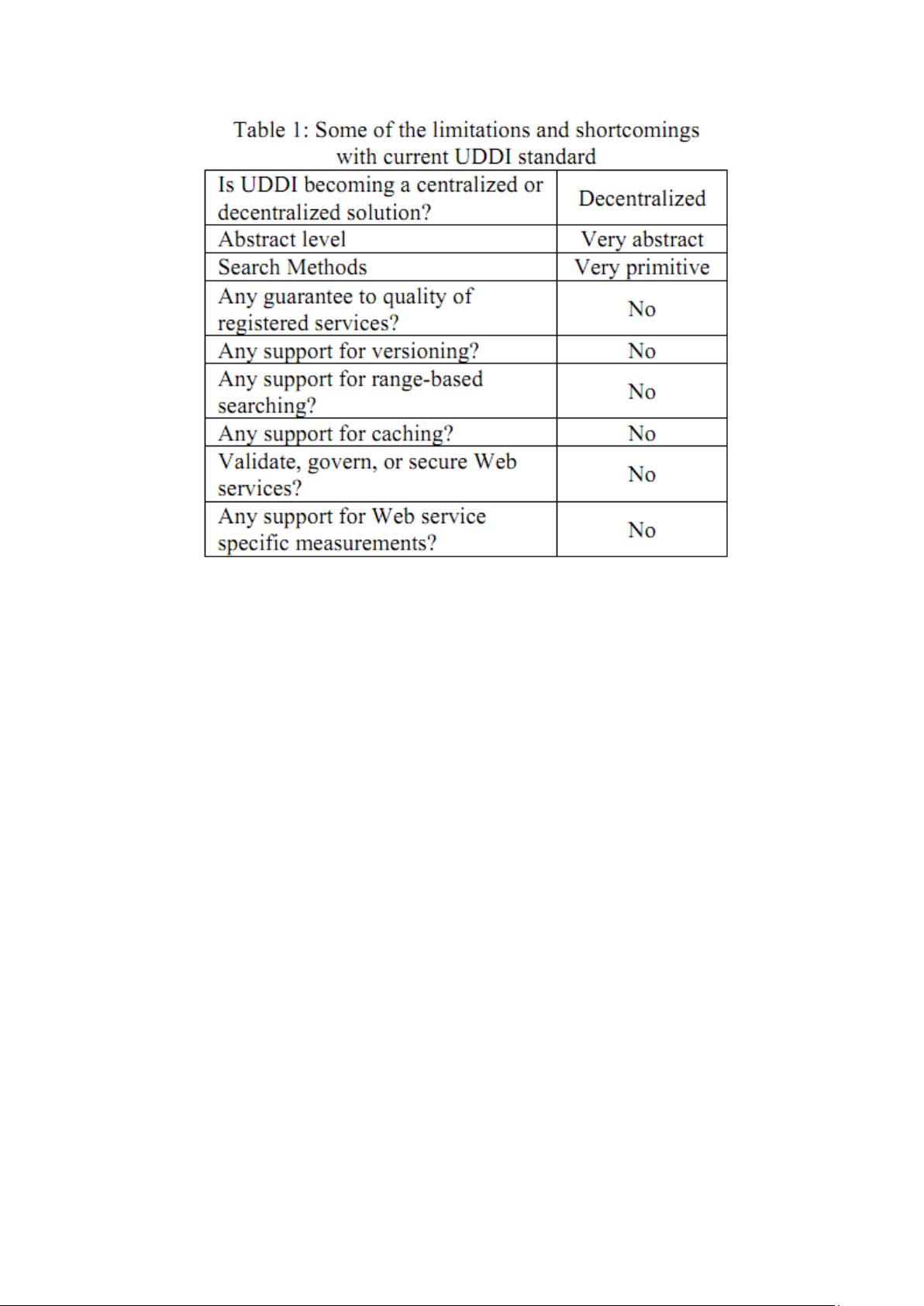
Although the UDDI has been the de facto industry standard for Web services’
discovery, the ability to find a scalable solution for handling significant amounts of
data from multiple UBRs at a large-scale is becoming a critical issue. Furthermore,
the search time when searching one or multiple UDDI registries (i.e. meta-discovery)
raises several concerns in terms performance, efficiency, reliability and the quality of
returned results.
4. Motivations for WSCE
Web services are syntactically described using the Web Service Description
Language (WSDL) which concentrates on describing Web services at the functional
level. A more elaborate business-centric model for Web services is provided by the
UDDI which allows businesses to create many-to-many partnership relationships and
serves as a focal point where all businesses of all sizes can meet together in an open
and a global framework. Although there have been numerous standards that support
the description and discovery of Web services, combining these sources of
information in a simple manner for clients to apprehend and use is not currently
present. In order for clients to search or invoke services, first they have to manually
perform search queries to an existing UBR based on a primitive keyword-based
technique, loop through returned results, extract binding information (i.e.
through bindingTemplates or via WSDL access points), and manually examine their
technical details. In this case, clients have to manually collect Web service
information from different types of resources which may not be a reliable approach
剩余28页未读,继续阅读

xinkai1688
- 粉丝: 359
- 资源: 8万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 解决Eclipse配置与导入Java工程常见问题
- 真空发生器:工作原理与抽吸性能分析
- 爱立信RBS6201开站流程详解
- 电脑开机声音解析:故障诊断指南
- JAVA实现贪吃蛇游戏
- 模糊神经网络实现与自学习能力探索
- PID型模糊神经网络控制器设计与学习算法
- 模糊神经网络在自适应PID控制器中的应用
- C++实现的学生成绩管理系统设计
- 802.1D STP 实现与优化:二层交换机中的生成树协议
- 解决Windows无法完成SD卡格式化的九种方法
- 软件测试方法:Beta与Alpha测试详解
- 软件测试周期详解:从需求分析到维护测试
- CMMI模型详解:软件企业能力提升的关键
- 移动Web开发框架选择:jQueryMobile、jQTouch、SenchaTouch对比
- Java程序设计试题与复习指南
