斯坦福机器学习笔记:回归与模型详解
需积分: 0 181 浏览量
更新于2024-07-19
收藏 11.4MB PDF 举报
本篇笔记是关于斯坦福大学的机器学习课程——CS229的学习心得,由作者在2011年上半年完成。课程内容主要围绕经典的机器学习算法,包括线性回归、逻辑回归、一般回归、支持向量机(SVM)、规则化和模型选择、K-means聚类、高斯混合模型与EM算法等。这些算法都是回归和分类问题的基础,属于有监督学习方法,目标是通过统计数据分析找到数学模型,用于预测或分类。
首先,回归问题作为课程的开端,如线性回归,是通过拟合数据中的模式来预测一个连续变量,如房屋面积与销售价格之间的关系。通过解决误差问题,理解模型的拟合程度和预测精度。逻辑回归则扩展到了二分类问题,通过sigmoid函数处理非线性关系。
接着,SVM是另一核心内容,分为两部分,涉及分类和回归,其目标是找到最优超平面,使得不同类别的样本能够最大化间隔。规则化和模型选择是为了避免过拟合,选择合适的模型复杂度和正则化参数。
K-means聚类算法用于无监督学习,它将数据集划分为预设数量的类别,每个类别内部的样本相似度最高。高斯混合模型(GMM)和EM算法则是用来处理复杂数据分布,通过迭代优化混合多个高斯分布以更好地拟合数据。
在线学习和降维技术如主成分分析(PCA)、独立成分分析(ICA)、线性判别分析(LDA)以及因子分析,进一步拓展了对数据的理解和处理能力,尤其在大数据背景下,这些方法对于数据预处理和特征提取至关重要。
此外,课程还涉及了偏最小二乘法回归,一种用于解决线性关系中多重共线性问题的方法,以及典型关联分析,一种发现变量间关系的统计方法。
作者强调,虽然笔记基于Andrew Ng教授的讲义和视频,但可能存在错误,因为这是个人学习笔记,建议读者查阅原著资料验证。对于更深入的问题,作者建议寻求专业人士的帮助或阅读相关论文。作者自身在研究生阶段专注于分布式计算和大数据处理领域,因此未来笔记内容可能会偏向这个方向。
这篇笔记提供了对斯坦福大学机器学习课程中关键概念和方法的深入理解,对于希望入门或复习机器学习的读者,是一个宝贵的学习资源。
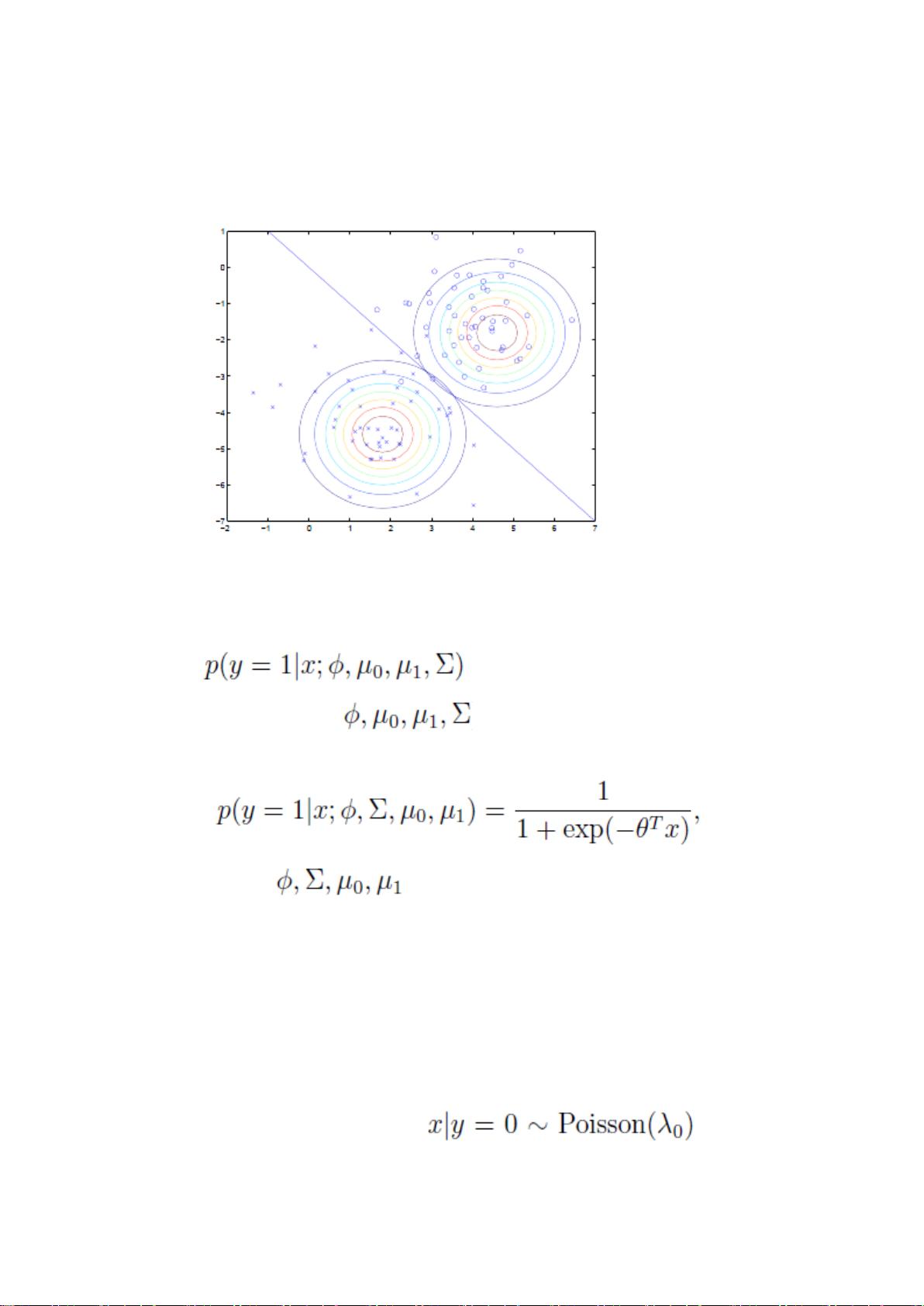
是 y=1 的样本中特征均值。
是样本特征方差均值。
如前面所述,在图上表示为:
直线两边的 y 值不同,但协方差矩阵相同,因此形状相同。不同,因此位置不同。
3) 高斯判别分析(GDA)与 logistic 回归的关系
将 GDA 用条件概率方式来表述的话,如下:
y 是 x 的函数,其中 都是参数。
进一步推导出
这里的是 的函数。
这个形式就是 logistic 回归的形式。
也就是说如果 p(x|y)符合多元高斯分布,那么 p(y|x)符合 logistic 回归模型。反之,
不成立。为什么反过来不成立呢?因为 GDA 有着更强的假设条件和约束。
如果认定训练数据满足多元高斯分布,那么 GDA 能够在训练集上是最好的模型。然
而,我们往往事先不知道训练数据满足什么样的分布,不能做很强的假设。Logistic
回归的条件假设要弱于 GDA,因此更多的时候采用 logistic 回归的方法。
例如,训练数据满足泊松分布,
13



剩余136页未读,继续阅读
257 浏览量
344 浏览量
490 浏览量
2024-10-26 上传
256 浏览量
166 浏览量
513 浏览量
2024-11-10 上传

weixin_38292787
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







