Hadoop MapReducev1:深入分析JobClient提交流程
149 浏览量
更新于2024-08-27
收藏 148KB PDF 举报
"MapReduceV1的Job提交流程分析"
MapReduceV1是Hadoop早期版本中的分布式计算框架,其核心组件包括JobClient、JobTracker和TaskTracker。在MapReduceV1中,当开发人员编写完MapReduce程序后,需要通过JobClient将Job提交到JobTracker进行调度和执行。本文将详细分析Job提交在JobClient端的具体步骤。
1. 创建Job实例与设置状态
在MapReduce程序中,开发者首先会创建一个Job实例,通过`Configuration`对象设置各种作业参数,例如输入路径、输出路径、Mapper和Reducer类等。同时,Job的状态也会被初始化。
2. 初始化JobClient并建立连接
接着,创建JobClient对象,这个对象负责与JobTracker进行通信。在初始化过程中,JobClient会尝试建立到JobTracker的远程过程调用(RPC)连接,确保可以进行后续的交互。
3. 获取新的JobID
JobClient通过JobSubmissionProtocol协议与JobTracker进行远程通信,请求并获取一个唯一的JobID,用于标识即将提交的Job。
4. 准备Job资源
JobClient将Job相关的资源(如jar文件、配置文件、输入数据等)复制到HDFS上。这些资源包括临时文件(tmpfiles)、临时jar文件(tmpjars)、临时归档文件(tmparchives)以及Job的主jar文件。这样做是为了使得JobTracker和TaskTracker可以在需要时访问这些资源。
5. 计算输入Split和元数据
根据Job配置的InputFormat,JobClient会计算输入数据的Split,生成SplitMetaInfo信息,包括每个Split的起始位置、长度等。此外,还会计算出所需的map任务和reduce任务的数量。
6. 写入HDFS
JobClient将计算出的Split信息、元数据以及Job配置写入HDFS的一个特定目录,这样JobTracker在接收到Job提交请求后,能够读取这些信息来准备和调度任务。
7. 提交Job
最后,JobClient通过JobSubmissionProtocol的submitJob方法,将整个Job提交给JobTracker。JobTracker接收到Job后,会进行一系列的检查和预处理,然后开始调度map和reduce任务给合适的TaskTracker执行。
通过以上步骤,MapReduce程序的Job成功地在JobClient端完成提交,进入了JobTracker的调度和执行阶段。理解这一过程对于优化MapReduce作业性能、调试问题或实现自定义的Job提交逻辑至关重要。
MapReduceV1::Job提交流程之提交流程之JobClient端分析端分析
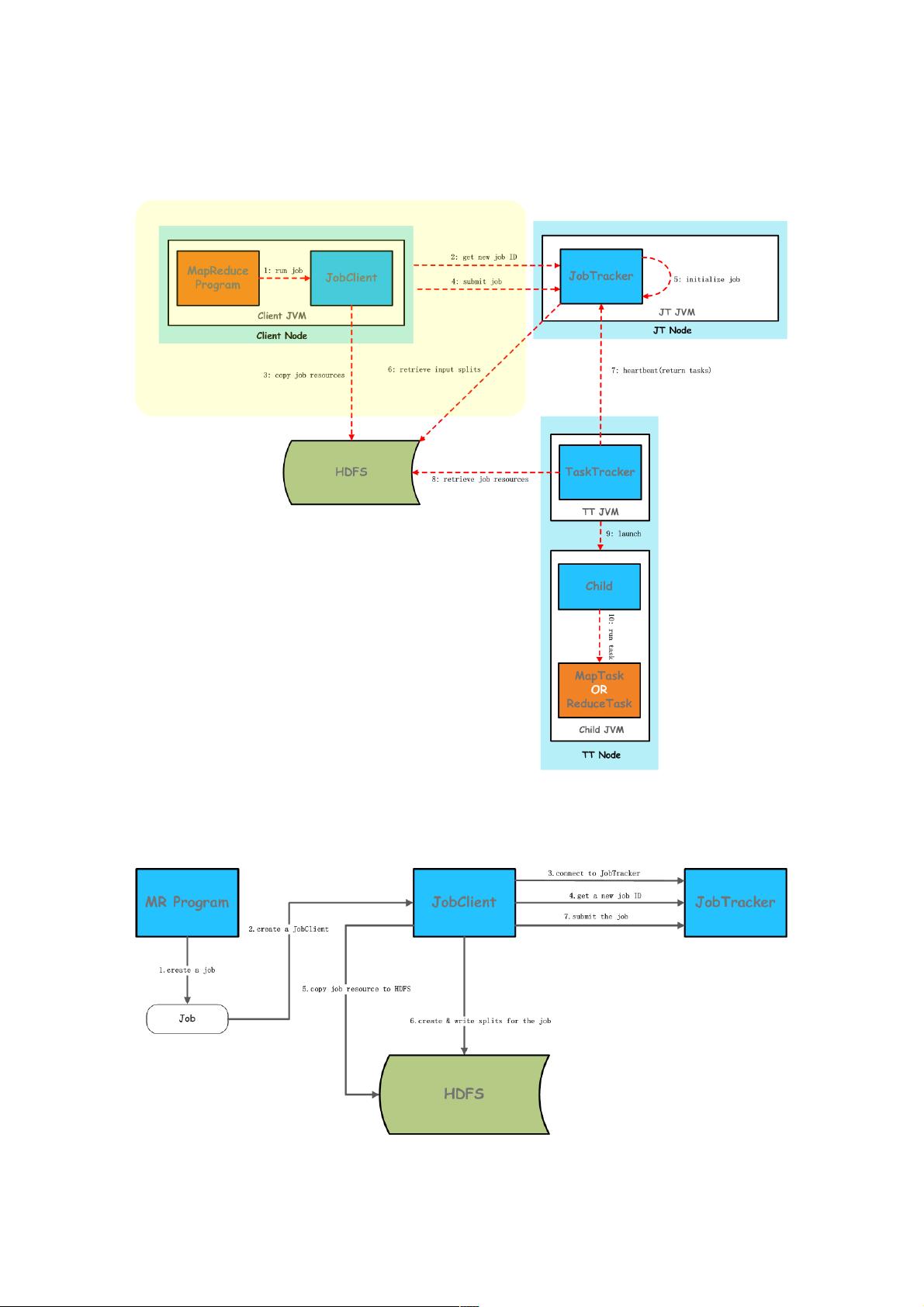
我们基于Hadoop 1.2.1源码分析MapReduce V1的处理流程。
MapReduce V1实现中,主要存在3个主要的分布式进程(角色):JobClient、JobTracker和TaskTracker,我们主要是以这
三个角色的实际处理活动为主线,并结合源码,分析实际处理流程。下图是《Hadoop权威指南》一书给出的MapReduce V1
处理Job的抽象流程图:
如上图,我们展开阴影部分的处理逻辑,详细分析Job提交在JobClient端的具体流程。
在编写好MapReduce程序以后,需要将Job提交给JobTracker,那么我们就需要了解在提交Job的过程中,在JobClient端都做
了哪些工作,或者说执行了哪些处理。在JobClient端提交Job的处理流程,如下图所示:
上图所描述的Job的提交流程,说明如下所示:
在MR程序中创建一个Job实例,设置Job状态
创建一个JobClient实例,准备将创建的Job实例提交到JobTracker
下载后可阅读完整内容,剩余5页未读,立即下载
188 浏览量
315 浏览量
188 浏览量
132 浏览量
190 浏览量
112 浏览量
2021-04-23 上传
点击了解资源详情
点击了解资源详情

weixin_38612811
- 粉丝: 5
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







最新资源
- DFSBack:DFS站点管理系统
- docker-tutorial:零基础学习docker,从应用入手带你深入理解docker
- 易语言学习-高级表格支持库最新测试版(2012-11-2).zip
- appfuse-service-3.0.0.zip
- 精益求精上网导航精美版生成htmlV090308
- ScoketServer.7z
- 参考正点原子,二次改造的STM32板卡原理图分享-电路方案
- Accelerated C# 2010.rar
- AcidPlatformer:这是一个简单的javascript平台程序,可能会随着时间的推移而演变为更多东西
- apm-agent-python:弹性APM的官方Python代理
- eshop-cache.rar
- studentManage.zip
- Module-6-Assessment-2
- :laptop:功能齐全的本地AWS云堆栈。 离线开发和测试您的云和无服务器应用程序!-Python开发
- 一组经典小图标 .xd .sketch .fig .png .svg素材下载
- django-accounting:适用于Django 1.7+项目的计费可插拔应用
