Kafka高性能架构:Partition并行处理与并发粒度解析
93 浏览量
更新于2024-08-27
收藏 632KB PDF 举报
"Kafka高性能架构之道主要集中在Partition的设计与并行处理机制,以及ConsumerGroup的并发粒度特性。"
Kafka作为一个高吞吐、低延迟的分布式消息系统,其性能优化策略主要体现在以下几个方面:
1. **Partition的并行处理**:
- Topic作为逻辑概念,由一个或多个Partition组成,Partition分布在不同的节点上,这使得Kafka能够利用集群的计算能力进行并行处理。每个Partition在物理上表现为一个本地文件夹,包含多个Segment文件和对应的索引文件。
- Partition内部通过offset作为索引,允许高效的数据访问。通过将Partition分布在不同节点或磁盘上,Kafka实现了跨机器和磁盘的并行处理,最大化利用硬件资源。
2. **多磁盘利用**:
- Kafka允许配置多个log.dirs,将不同磁盘挂载到不同目录,进而将Partition均匀分布到各个磁盘上,实现磁盘间的并行I/O操作,提高整体吞吐量。
3. **Partition是最小并发粒度**:
- 在消费端,ConsumerGroup内的多个Consumer并行消费Topic,但每个Partition的数据仅由一个Consumer消费。这种设计保证了消息的有序性,并且使得Consumer的数量可以灵活调整以匹配Partition数量,实现最佳并发处理。
4. **ConsumerGroup和负载均衡**:
- 如果Consumer的数量超过Partition的数量,部分Consumer将处于空闲状态,直到发生Rebalance,这时ConsumerGroup内的Consumer会重新分配Partition,确保负载均衡。
5. **Segment的写入与读取**:
- 写入时,Kafka一次只写入一个Partition的Segment,保证操作的简单性和效率。读取时,Consumer会顺序读取Partition内的Segment,保证了数据读取的连续性,有利于提高读取速度。
6. **并行处理限制**:
- 尽管Segment是物理存储的最小单位,但由于写入和读取的顺序性,Kafka并不支持在同一Partition内不同Segment之间的并行处理。
Kafka的这种架构设计使其在大数据实时处理场景下表现出色,能够有效地处理海量消息,同时保证数据的可靠性和处理的高效性。理解并掌握这些核心原理对于优化Kafka的部署和应用至关重要。
Kafka高性能架构之道高性能架构之道
宏观架构层面
利用Partition实现并行处理
Partition提供并行处理的能力
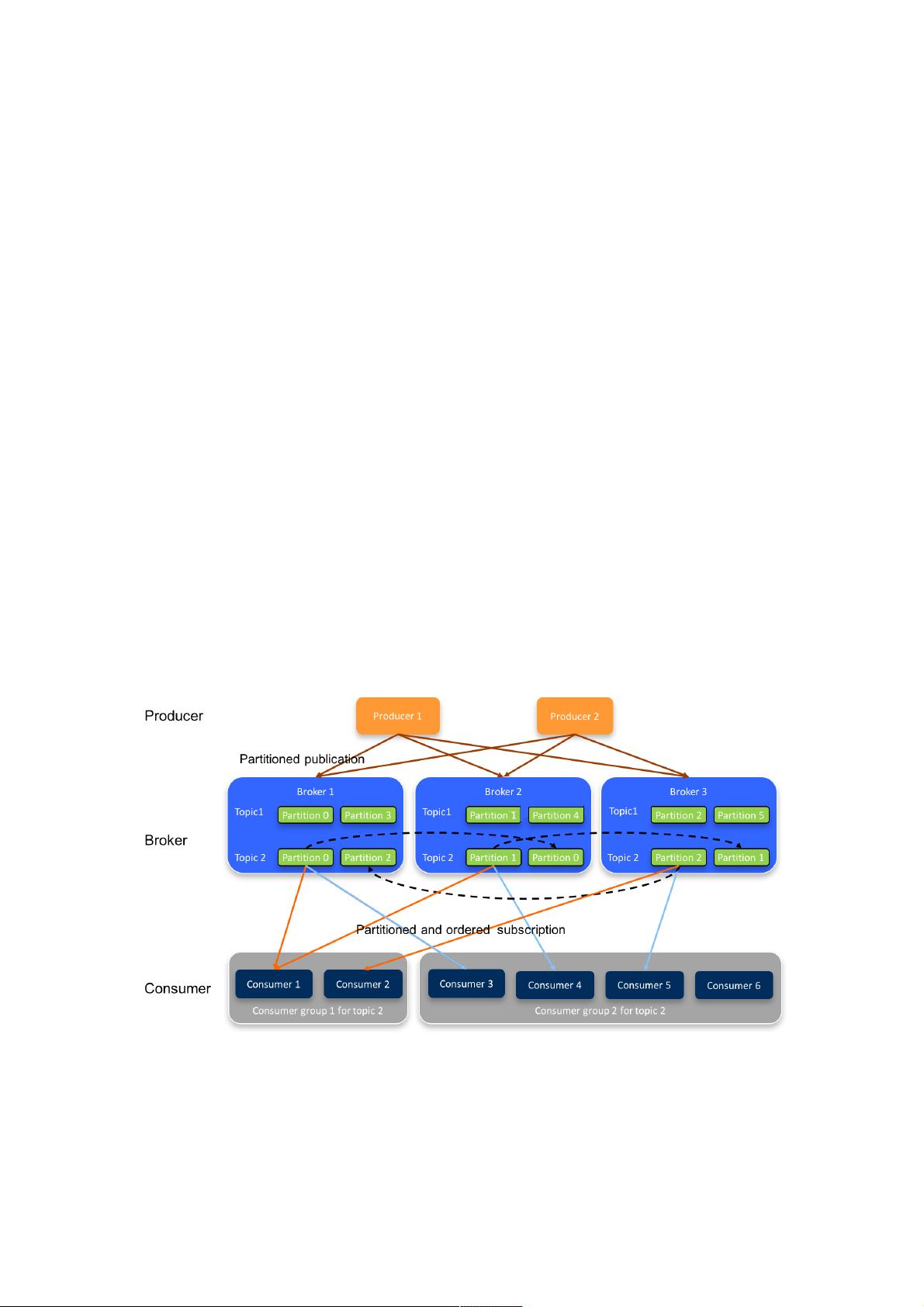
Kafka是一个Pub-Sub的消息系统,无论是发布还是订阅,都须指定Topic。如《Kafka设计解析(一)- Kafka背景及架构介
绍》一文所述,Topic只是一个逻辑的概念。每个Topic都包含一个或多个Partition,不同Partition可位于不同节点。同时
Partition在物理上对应一个本地文件夹,每个Partition包含一个或多个Segment,每个Segment包含一个数据文件和一个与之
对应的索引文件。在逻辑上,可以把一个Partition当作一个非常长的数组,可通过这个“数组”的索引(offset)去访问其数据。
一方面,由于不同Partition可位于不同机器,因此可以充分利用集群优势,实现机器间的并行处理。另一方面,由于Partition
在物理上对应一个文件夹,即使多个Partition位于同一个节点,也可通过配置让同一节点上的不同Partition置于不同的disk
drive上,从而实现磁盘间的并行处理,充分发挥多磁盘的优势。
利用多磁盘的具体方法是,将不同磁盘mount到不同目录,然后在server.properties中,将log.dirs设置为多目录(用逗号分
隔)。Kafka会自动将所有Partition尽可能均匀分配到不同目录也即不同目录(也即不同disk)上。
注:虽然物理上最小单位是Segment,但Kafka并不提供同一Partition内不同Segment间的并行处理。因为对于写而言,每次
只会写Partition内的一个Segment,而对于读而言,也只会顺序读取同一Partition内的不同Segment。
Partition是最小并发粒度
如同《Kafka设计解析(四)- Kafka Consumer设计解析》一文所述,多Consumer消费同一个Topic时,同一条消息只会被同
一Consumer Group内的一个Consumer所消费。而数据并非按消息为单位分配,而是以Partition为单位分配,也即同一个
Partition的数据只会被一个Consumer所消费(在不考虑Rebalance的前提下)。
如果Consumer的个数多于Partition的个数,那么会有部分Consumer无法消费该Topic的任何数据,也即当Consumer个数超过
Partition后,增加Consumer并不能增加并行度。
简而言之,Partition个数决定了可能的最大并行度。如下图所示,由于Topic 2只包含3个Partition,故group2中的Consumer
3、Consumer 4、Consumer 5 可分别消费1个Partition的数据,而Consumer 6消费不到Topic 2的任何数据。
以Spark消费Kafka数据为例,如果所消费的Topic的Partition数为N,则有效的Spark最大并行度也为N。即使将Spark的
Executor数设置为N+M,最多也只有N个Executor可同时处理该Topic的数据。
ISR实现可用性与数据一致性的动态平衡
CAP理论
CAP理论是指,分布式系统中,一致性、可用性和分区容忍性最多只能同时满足两个。
一致性
1.通过某个节点的写操作结果对后面通过其它节点的读操作可见
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-03-18 上传
2024-11-22 上传
2020-07-04 上传
点击了解资源详情
点击了解资源详情
2021-01-27 上传

weixin_38665490
- 粉丝: 5
- 资源: 985
 我的内容管理
展开
我的内容管理
展开







