聚簇索引与非聚簇索引详解:数据存储与优化策略
157 浏览量
更新于2024-08-31
1
收藏 375KB PDF 举报
在数据库管理系统中,聚簇索引和非聚簇索引是两种重要的索引类型,它们在数据存储和查询性能方面有着显著的区别。
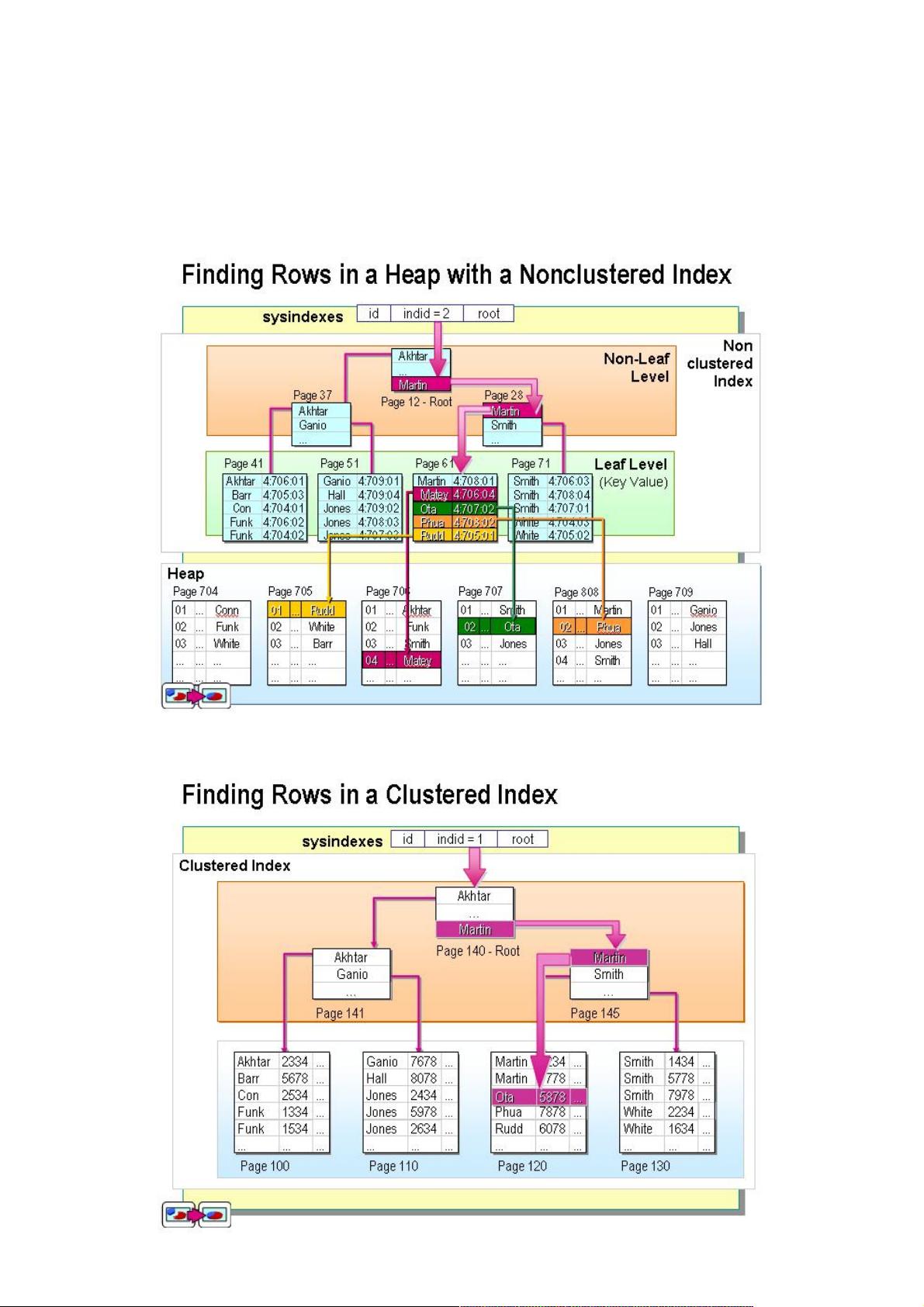
首先,聚簇索引(Custom Index)的特点在于其顺序直接反映了数据的物理存储顺序。在《数据库原理》中,聚簇索引被定义为数据行在数据库中的物理存储方式。这意味着表的主键或唯一键通常会作为聚簇索引,且表中任何一条记录都存储在一个单独的物理位置,因此每次插入、删除或更新操作时,数据可能会发生物理移动。由于这种特性,一个数据库表最多只能有一个聚簇索引。
非聚簇索引(Non-Custom Index)则独立于数据的物理存储,索引的顺序并不依赖于数据行的物理位置。非聚簇索引的叶子节点包含的是指向实际数据行的指针,而非数据本身。创建非聚簇索引时,系统会为每个索引项维护一个独立的索引条目,这使得多个字段或组合可以构成非聚簇索引,非常适合于多列排序或全文搜索。在查找数据时,查询引擎先通过非聚簇索引来定位到数据所在的物理位置,然后再访问实际的数据块。
索引优化技术对于查询性能至关重要。尽管索引可以显著减少数据查找时间,但如果应用不当,也可能带来负面影响。例如,在检索大量记录时,如果目标是查找所有记录,使用索引反而可能导致更多的磁盘I/O操作,因为索引本身也需要被扫描。这时,如果没有特定的查询过滤条件,不使用索引可能更快。因此,设计合理的索引策略是根据查询模式和表结构来决定的,以平衡索引的创建、维护成本和查询效率。
在SQL Server中,索引的内部结构如B树(用于非聚簇索引)和索引块与数据块的关系有助于理解这些概念。索引块的大小与数据块相比更小,允许在更短的时间内找到所需数据,从而提高查询速度。但这也意味着频繁的索引更新可能会占用更多存储空间,对数据一致性有更高的要求。
总结来说,选择聚簇索引还是非聚簇索引取决于具体的应用场景,包括查询模式、数据更新频率、数据分布、存储成本等因素。理解这两种索引类型的特点及其在查询优化中的作用,可以帮助数据库管理员做出明智的设计决策。
数据库中聚簇索引与非聚簇索引的区别数据库中聚簇索引与非聚簇索引的区别[图文图文]
在《数据库原理》里面,对聚簇索引的解释是:聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的解
释是:索引顺序与数据物理排列顺序无关。正式因为如此,所以一个表最多只能有一个聚簇索引
在《数据库原理》里面,对聚簇索引的解释是:聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的解释是:索引顺序
与数据物理排列顺序无关。正式因为如此,所以一个表最多只能有一个聚簇索引。
不过这个定义太抽象了。在SQL Server中,索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶
节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。如下图:
非聚簇索引
聚簇索引
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-12-14 上传
2023-09-12 上传
2023-11-27 上传
2023-05-13 上传
2023-08-17 上传
2023-02-26 上传

weixin_38742421
- 粉丝: 2
- 资源: 954
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
