Druid精确去重设计与实现解析
版权申诉
110 浏览量
更新于2024-07-05
收藏 30.78MB PDF 举报
"Druid精确去重在的设计与实现(38页).pdf"
本文档主要介绍了Druid数据处理框架在实现精确去重方面的设计与实践,它是一款强大的在线分析型数据库(OLAP),广泛应用于大数据分析领域。Druid以其高效的数据存储、实时查询和复杂聚合能力而知名。
1. Druid简介:
Druid是一个开源的分布式数据存储系统,专为实时分析和大规模数据集而设计。其架构包括数据摄取、中间层(Broker)、数据存储(Segment)和查询引擎等组件。Druid的特点在于对数据进行列式存储,支持快速的点查询、范围查询以及复杂的聚合操作。
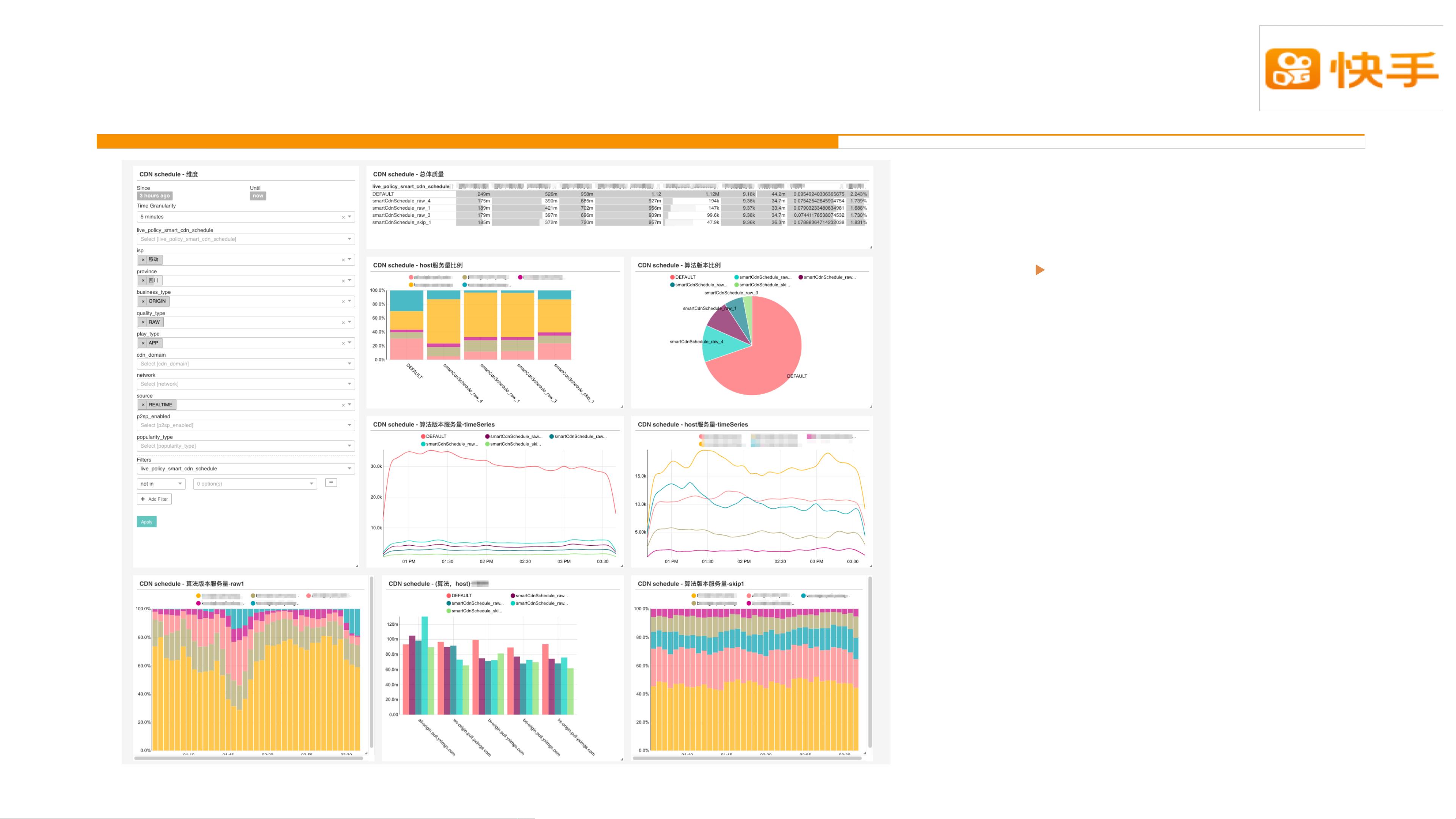
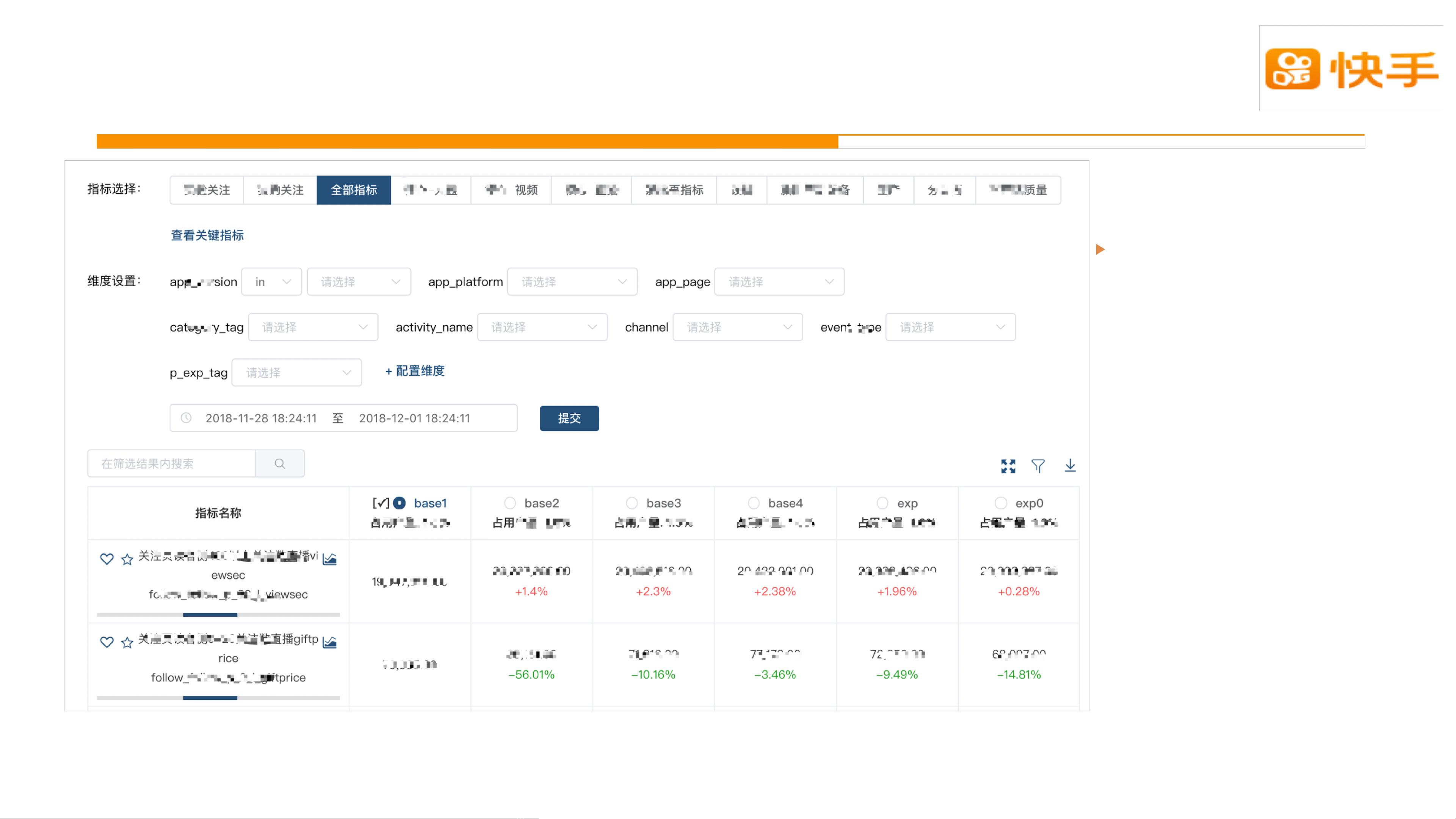
2. 精确去重设计:
在大数据场景下,去重是常见的需求,Druid通过使用HyperLogLog(HLL)算法实现了高效的近似去重。HLL是一种概率统计方法,能够在较低的空间复杂度下估算集合的唯一元素数量,同时保持较高的精度。Druid中的`cardinality`聚合函数就是基于此算法来计算不重复值的数量。
3. Druid的数据模型:
Druid的数据模型由维度(Dimensions)和指标(Metrics)组成,维度是用于区分事件的属性,指标是用于聚合的数值。在Druid中,每个事件被分割成多个Segment,这些Segment分布在不同的节点上,可以并行处理查询,加速响应速度。
4. Druid的扩展性:
Druid支持Hadoop和Kylin等生态系统的集成,允许用户利用这些工具进行数据处理和分析。此外,文档中提到了`druidcontributor`,这可能是指Druid社区贡献者的项目,表明Druid有活跃的开发者社区进行持续优化和扩展。
5. Druid Roadmap:
Druid的未来发展规划可能涉及到性能提升、新功能添加和与其他技术的更紧密集成。具体细节未在摘要中详细展开,但可以推测Druid将持续关注实时分析的效率和准确性。
6. Q&A部分:
提供了关于Druid的常见问题解答,可能涵盖了Druid的安装、配置、使用和优化等方面的问题,帮助用户更好地理解和使用Druid系统。
7. 其他内容:
文档还包含了Druid与其他工具如Hadoop和KwaiBI的比较,以及性能测试和实际应用场景的案例,展示了Druid在不同场景下的优秀表现。
总结来说,这份文档详细阐述了Druid如何实现精确去重,并提供了关于Druid系统设计、特性和使用场景的深入理解,对于需要进行大数据实时分析的开发者和数据分析师具有很高的参考价值。
7
剩余37页未读,继续阅读
169 浏览量
1330 浏览量
194 浏览量
169 浏览量
170 浏览量
2344 浏览量
2022-03-26 上传
2023-12-11 上传

行业报告
- 粉丝: 4
- 资源: 6233
 我的内容管理
展开
我的内容管理
展开







最新资源
- python代码自动办公 Excel_更灵活的操作方式 项目源码有详细注解,适合新手一看就懂.rar
- 基于基于粒子滤波器的SLAM算法实现地图的成像matlab仿真
- 《鬼鬼盯着你》绘本故事PPT模板
- alfabetizar.aprender.digital
- 紫色花朵 潮流壁纸 高清风景 新标签页 主题-crx插件
- hveto_graph:hveto 摘要页面的 D3.js 版本
- who-does-not-follow-me:一个Node.js脚本,用于检查谁没有在GitHub上关注您
- CSS3地图热点文字标注提示特效代码
- python代码自动办公excel处理实例(单工作簿拆分到多工作簿中(多表中) 项目源码有详细注解,适合新手一看就懂.rar
- 对tabcontrol的应用及tabpage的处理
- emv:EMV芯片和PIN库
- giffus:一个允许用户通过互联网发送礼物的小型社交应用程序。 支持音乐等多种类型的礼物,特别是打开礼物,接收者必须去发送者想要的地方
- github-repos-react:添加GitHub repos并查看其详细信息和问题
- Khayyam-crx插件
- smoothing(imagetosm_ooth)_滤波_去噪_通信去噪_
- 局域网 【飞秋】 【FeiQ】 下载
