利用torchvision构建CIFAR10图像分类器:数据预处理与训练
需积分: 0 132 浏览量
更新于2024-08-05
收藏 571KB PDF 举报
在训练分类器的过程中,首要任务是准备高质量的训练数据。在Python环境下,特别是针对图像数据,我们通常使用诸如Pillow和OpenCV这样的库来加载和预处理图像。这些库可以帮助我们将图像转换为Numpy数组,以便于后续的模型训练。PyTorch的torchvision模块为数据处理提供了便利,它包含了CIFAR10这样的常用数据集,包括10类不同对象的32x32像素图片,如飞机、汽车、鸟等。
在构建训练流程时,以下步骤至关重要:
1. **数据加载与预处理**:
- 使用torchvision.datasets.CIFAR10加载训练集和测试集,并确保数据已经下载到本地(如果尚未存在)。数据默认是以PILImage格式提供,值范围为[0, 1],需要进行标准化处理,使其落在[-1, 1]范围内,以适应神经网络的输入要求。为此,我们可以定义一个Compose变换器(transforms.Compose),结合ToTensor()和Normalize()方法进行归一化。
```python
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(root='./data/', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True, num_workers=2)
```
2. **构建卷积神经网络**:
- 设计一个适合图像分类任务的卷积神经网络(CNN)。这可能包括卷积层(Conv2d)、池化层(MaxPool2d)、批量归一化(BatchNorm2d)、激活函数(ReLU)以及全连接层(Dense)。常用的框架如PyTorch的torch.nn模块提供了这些组件的实现。
3. **定义损失函数**:
- 选择适当的损失函数,对于图像分类任务,交叉熵损失(CrossEntropyLoss)是常见选择,它衡量了模型预测结果与真实标签之间的差异。
4. **模型训练**:
- 将构建好的网络模型传入训练循环,设置优化器(如Adam、SGD等)和学习率,然后在训练集上迭代执行前向传播、反向传播和参数更新。
5. **模型评估**:
- 在训练完成后,在测试集上验证模型的泛化能力,计算准确率等指标,确保模型不会过度拟合训练数据。
6. **可视化训练过程**:
- 可视化训练中的图片样本,观察模型学习进度和性能。这有助于调试模型和理解训练效果。
训练分类器涉及到数据的获取、预处理、模型构建、训练和评估等多个环节。每个步骤都需要根据具体任务和数据特性进行调整,以达到最佳的模型性能。在实际操作中,可能还需要对网络架构进行迭代优化,调整超参数,以达到最佳的训练效果。
注:此处存在PyTorch BUG之一,详情点这里
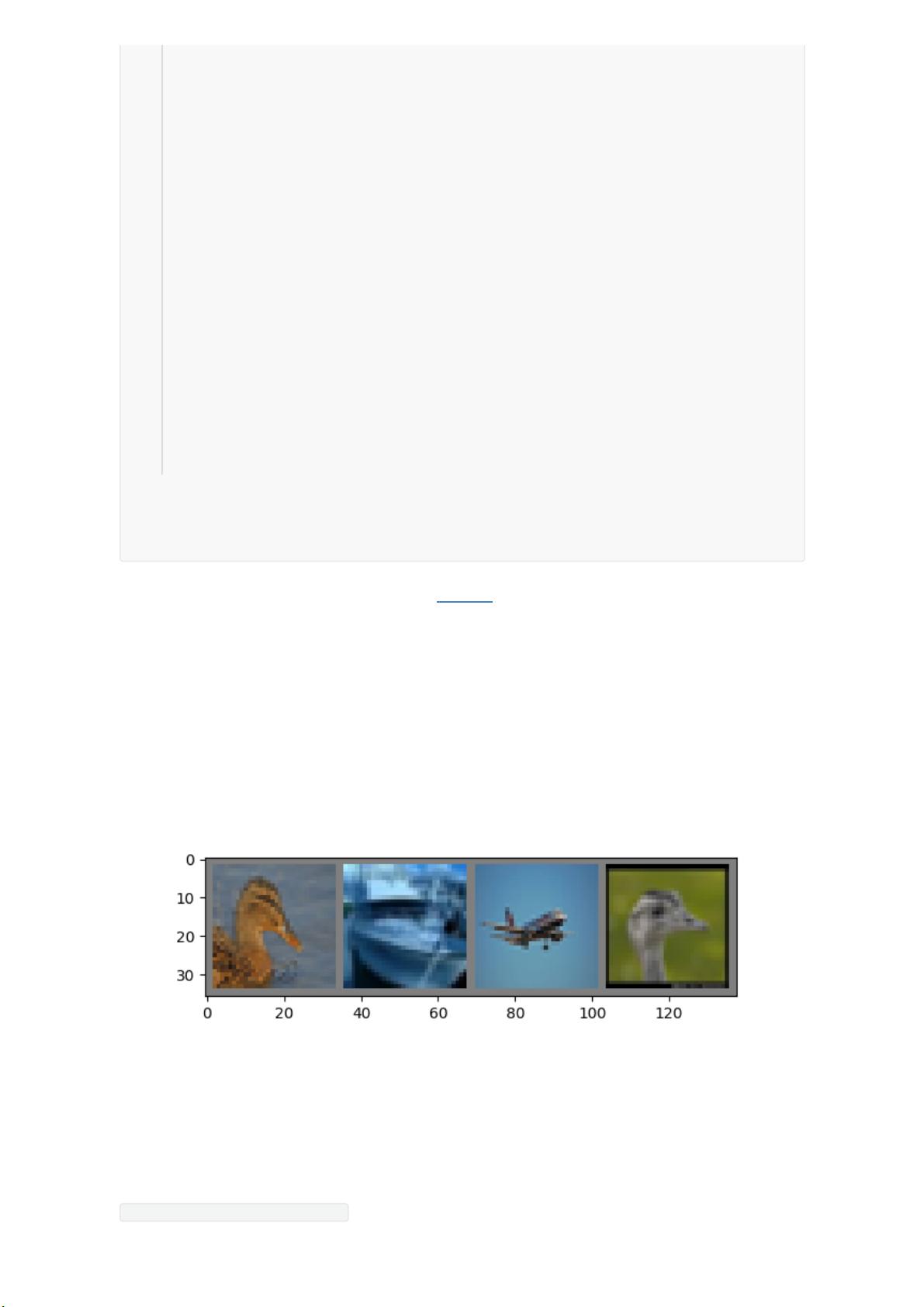
可视化数据:
bird ship plane bird
img = img / 2 + 0.5 # 非归一化
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
if __name__ == '__main__':
# 注:若未将以下内容写在主函数接口下,直接运行,mac可以成功运行,但
是win10由于无法启动 多线程环境而无法成功运行,报错:
BrokenPipeError: [Errno 32] Broken pipe
# 随机获取训练集图片
dataiter = iter(trainloader)
images, labels = dataiter.next()
# 展示图片
imshow(torchvision.utils.make_grid(images))
# 打印图片类别标签
print(' '.join('%5s' % classes[labels[j]] for j in
range(4)))
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
剩余10页未读,继续阅读
293 浏览量
190 浏览量
364 浏览量
119 浏览量
290 浏览量
829 浏览量
1130 浏览量

半清斋
- 粉丝: 968
- 资源: 322
 我的内容管理
展开
我的内容管理
展开







最新资源
- article-api:使用Sails的文章API
- maurooviedo.com:使用vue.js和早午餐建立的个人网站博客
- Web网站实现用户的增删改查服务.zip
- nupurmurthy.github.io
- 维宏四轴五轴水切割V10用户手册-R1.rar
- 伺服控制器28335 sch.rar
- React-TS-Demo
- pyiron_atomistics:pyiron_atomistics-用于计算材料科学中原子模拟的集成开发环境(IDE)
- 和利时 中央空调专用PLCe.rar
- mysql-5.6.9-rc-winx64.zip
- 自动泊车代码Matlab-ANPR:ANPR是一种软件,可在收费站捕获车辆的图像,然后从图像中提取车辆的车牌,并执行OCR以获取车牌号,以进行
- holbertonschool-web_front_end
- NETCFv35.Messages.zh-CHT.wm.rar
- 聊天空间
- SIMATIC WinCC v7 正版有“礼”.rar
- JobScheduler
