一致性Hash算法:解决分布式缓存问题的良方
版权申诉
88 浏览量
更新于2024-08-03
收藏 219KB DOCX 举报
一致性 Hash 算法详解
一致性 Hash 算法是一种分布式数据存储策略,旨在解决大规模数据存储和查询问题。当数据量很大、访问压力很大时,单台服务器无法满足需求,需要使用多台服务器组成集群来存储和处理数据。然而,这就产生了一个问题:如何将数据平均地分布到每台服务器上,以便快速查询和存储数据?
传统的解决方法是使用取模算法,即 hash(key) % N,N 是服务器的数量。但是,这种方法存在问题:当服务器数量变化时,数据的分布会被严重影响,可能会造成缓存雪崩。
一致性 Hash 算法可以很好地解决这个问题。其工作原理是:将 0 作为起点,2^32-1 作为终点,画一条直线,然后将起点和终点重合,直线变成一个圆,方向是顺时针从小到大。然后,对每个服务器的 IP 或关键字进行 Hash 后对 2^32 取模,得到一个 Node 节点。对数据 key 进行相同的操作,也可以得到一个 Node 节点。然后,顺时针行走,可以找到某一个 Node,这就是这个 key 要存储的服务器。
一致性 Hash 算法解决了大部分数据的问题,但是仍然存在一些问题:如果节点太少或分布不均匀,容易造成数据倾斜,也就是大部分数据会集中在某一台服务器上。为了解决数据倾斜问题,一致性 Hash 算法提出了虚拟节点的概念,即对每一个服务节点计算多个哈希,然后放到圈上的不同位置。
一致性 Hash 算法是一种高效的分布式数据存储策略,能够解决大规模数据存储和查询问题。但是,它也存在一些缺陷,需要在实际应用中进行调整和优化。
知识点:
1、一致性 Hash 算法是分布式数据存储策略的重要组成部分。
2、传统的取模算法存在问题:服务器数量变化时,数据分布会被严重影响。
3、一致性 Hash 算法可以解决大部分数据的问题,但也存在一些缺陷,如数据倾斜问题。
4、虚拟节点是解决数据倾斜问题的重要方法。
5、一致性 Hash 算法可以提高数据存储和查询的效率。
一致性 Hash 算法是分布式数据存储策略的重要组成部分,可以解决大规模数据存储和查询问题。但是,需要在实际应用中进行调整和优化,以提高数据存储和查询的效率。
什么是一致性 Hash 算法?面试又被问到怎么办?
数 据 分 ⽚
✔ 先让我们看一个例子吧
我们经常会用 Redis 做缓存,把一些数据放在上面,以减少数据的压力。
当数据量少,访问压力不大的时候,通常一台Redis就能搞定,为了高可用,弄个主从也就足够了;
当数据量变大,并发量也增加的时候,把全部的缓存数据放在一台机器上就有些吃力了,毕竟一台机器的资源是有限的,
通常我们会搭建集群环境,让数据尽量平均的放到每一台
R
e
d
i
s
中,比如我们的集群中有
4
台
R
e
d
i
s
。
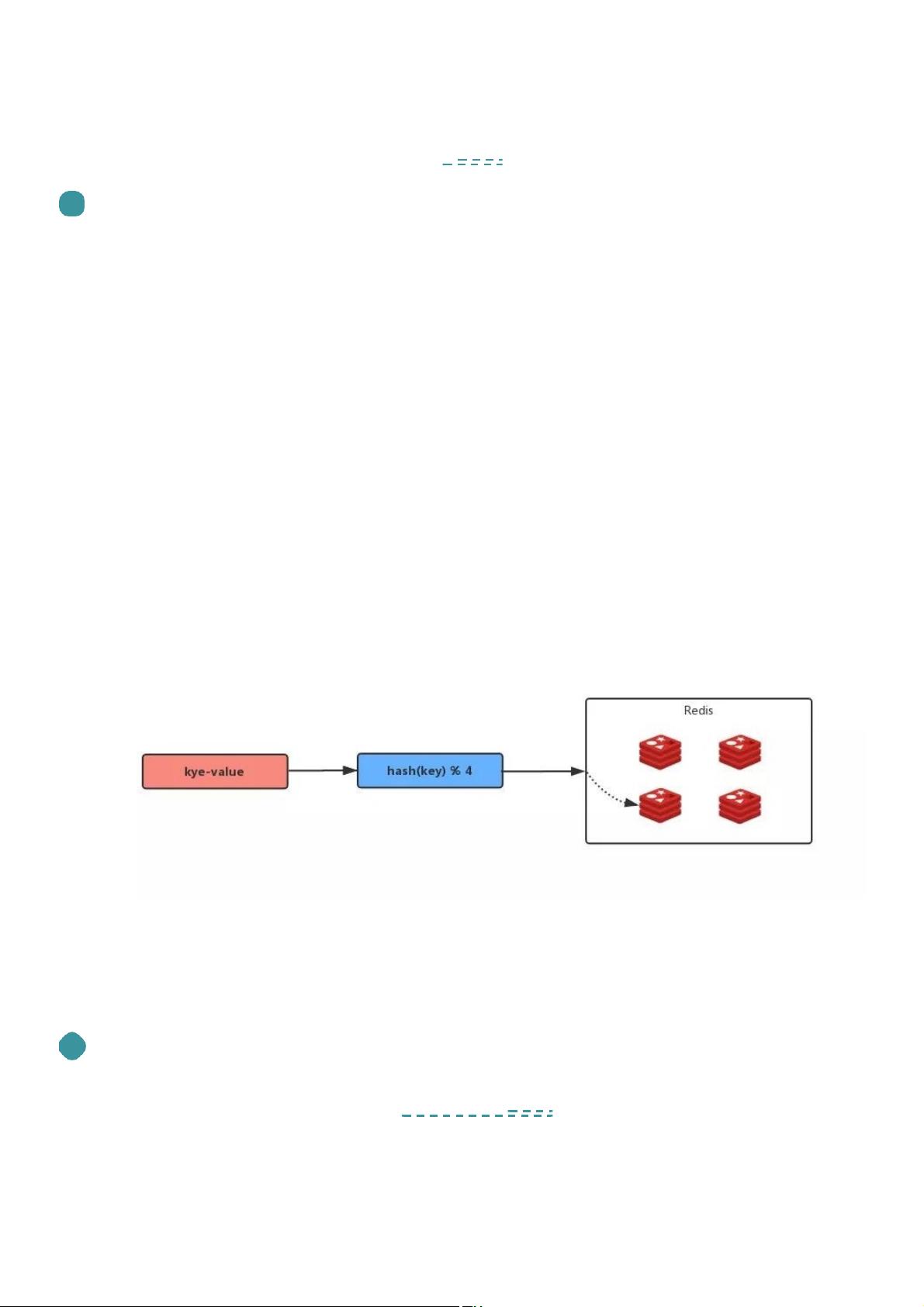
那么如何把数据尽量平均地放到这 4 台Redis中呢?最简单的就是取模算法:
hash( key ) % N,N 为 Redis 的数量,在这里 N = 4 ;
看起来非常得美好,因为依靠这样的方法,我们可以让数据平均存储到 4 台 Redis 中,当有新的请求过来的时候,我们也可
以定位数据会在哪台 Redis 中,这样可以精确地查询到缓存数据。
数 据 分
⽚
会 遇 到 的 问 题
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-05-01 上传
2024-03-08 上传
2021-10-26 上传
2022-06-10 上传
2023-06-10 上传
2022-06-03 上传

小小哭包
- 粉丝: 2086
- 资源: 4286
 我的内容管理
展开
我的内容管理
展开







