Python爬虫教程:抓取百度贴吧内容并存入txt
163 浏览量
更新于2024-08-29
收藏 158KB PDF 举报
"这篇教程介绍了如何从零开始编写Python爬虫来抓取百度贴吧的内容,并将其存储到本地的TXT文件中。"
在Python爬虫的世界里,百度贴吧是一个常见的实践对象,因为它的网页结构相对简单,适合初学者进行学习。本教程针对零基础的Python学习者,讲解了如何构建一个简单的爬虫程序来抓取贴吧帖子的标题和内容,并存储到本地TXT文件。
首先,我们需要了解页面的URL结构。在百度贴吧中,当你点击“只看楼主”并翻页时,URL会包含特定参数,如`see_lz=1`表示只看楼主的帖子,`pn`则代表页码。例如,`http://tieba.baidu.com/p/2296712428?see_lz=1&pn=1`,这些参数是我们构造爬虫时需要模仿的关键部分。
接着,我们需要解析网页源码来提取所需信息。Python提供了多种库用于网页解析,如BeautifulSoup或正则表达式。在这个例子中,教程提到了使用正则表达式来匹配和提取标题和内容。标题通常被包围在`<h1>`标签内,而内容可能分散在多个`<div>`标签内,带有特定的class属性。我们需要编写正则表达式来匹配这些标签,然后提取它们之间的文本。
代码示例中展示了如何使用Python的`re`模块进行正则匹配。`BgnCharToNoneRex`和`EndCharToNoneRex`是用来清除HTML标签和不必要的字符,`BgnPartRex`则是用于匹配`<p>`标签的开始部分,以便于整理内容的格式。
在实际操作中,我们还需要处理网络请求,这通常使用`urllib2`库。这个库可以帮助我们发送HTTP请求,获取网页内容。此外,为了确保编码正确,可能会涉及到对GBK编码的处理,因为百度贴吧的页面编码可能是GBK。
程序的运行流程大致如下:
1. 发送GET请求到目标URL,获取HTML源码。
2. 使用正则表达式解析HTML,提取标题和内容。
3. 清理提取的文本,去除无用的HTML标签和空白字符。
4. 将处理后的数据写入本地TXT文件,通常使用`open()`函数和`write()`方法实现。
5. 重复步骤1-4,以抓取多页内容,通常通过改变URL中的页码参数实现。
最后,值得注意的是,网络爬虫需要遵守网站的Robots协议,尊重网站的版权,不进行非法的数据抓取。此外,频繁的爬取可能会导致IP被封禁,所以合理控制爬虫的速度和使用代理IP是避免问题的好方法。
这个项目是一个很好的起点,让初学者能够了解Python爬虫的基本工作原理,包括网络请求、HTML解析以及数据存储。通过实践这个项目,你可以掌握基本的爬虫技能,并为进一步的爬虫开发打下基础。
零基础写零基础写python爬虫之抓取百度贴吧并存储到本地爬虫之抓取百度贴吧并存储到本地txt文件改进版文件改进版
百度贴吧的爬虫制作和糗百的爬虫制作原理基本相同,都是通过查看源码扣出关键数据,然后将其存储到本地txt文件。
项目内容:
用Python写的百度贴吧的网络爬虫。
使用方法:
新建一个BugBaidu.py文件,然后将代码复制到里面后,双击运行。
程序功能:
将贴吧中楼主发布的内容打包txt存储到本地。
原理解释:
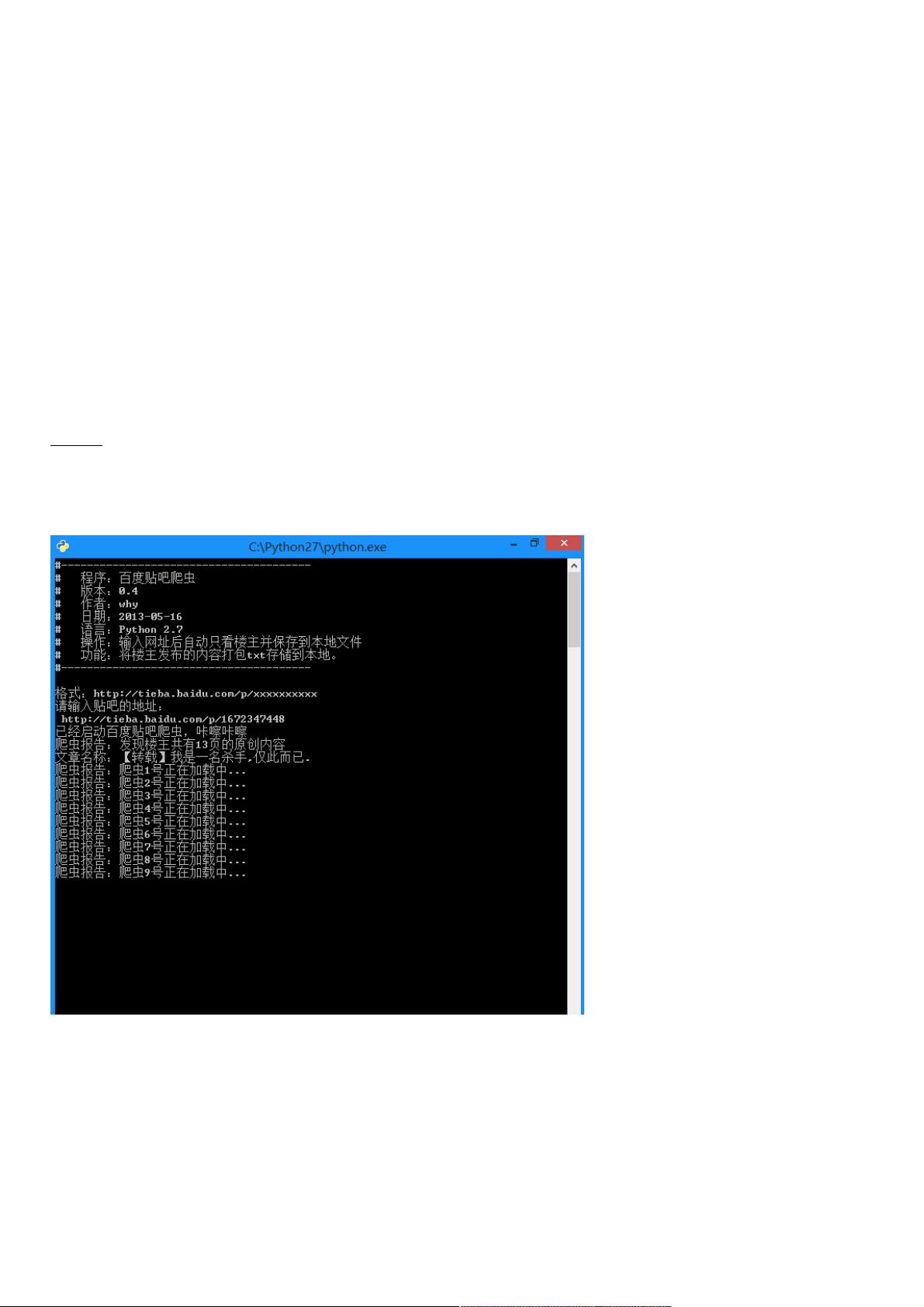
首先,先浏览一下某一条贴吧,点击只看楼主并点击第二页之后url发生了一点变化,变成了:
http://tieba.baidu.com/p/2296712428?see_lz=1&pn=1
可以看出来,see_lz=1是只看楼主,pn=1是对应的页码,记住这一点为以后的编写做准备。
这就是我们需要利用的url。
接下来就是查看页面源码。
首先把题目抠出来存储文件的时候会用到。
可以看到百度使用gbk编码,标题使用h1标记:
复制代码 代码如下:
<h1 class=”core_title_txt” title=”【原创】时尚首席(关于时尚,名利,事业,爱情,励志)”>【原创】时尚首席(关于时尚,名利,事业,爱情,
励志)</h1>
同样,正文部分用div和class综合标记,接下来要做的只是用正则表达式来匹配即可。
运行截图:
生成的txt文件:
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-12-24 上传
2021-01-20 上传
2024-12-11 上传
2020-09-20 上传
2024-03-07 上传

weixin_38713412
- 粉丝: 7
- 资源: 961
 我的内容管理
展开
我的内容管理
展开







最新资源
- Study-Circle:这个跨平台的应用程序是使用Flutter制作的,它可能会起到连接社会学习和共同成长的作用
- 一个简易的智能聊天机器人系统.zip
- MiniChickenFolkloric:TCC-UFAM 2020
- matlab心线代码-Multi-Agent-Navigation:多个代理的免费导航
- Whereby-crx插件
- Windows-NT-Native-API.zip_Windows编程_C/C++_
- the-white-rabbit:White Rabbit是基于Kotlin协程的异步RabbitMQ(AMQP)客户端
- 2Ring Extension for Cisco Finesse v4.1.1-crx插件
- 下一个示例会计笔记本
- Design_Park.rar_CAD_Windows_Unix_
- 瑞金医院MMC人工智能辅助构建知识图谱大赛.zip
- skillfactory
- 课程设计之基于HTML+CSS的网页设计.rar
- jokeapp:Spring5Framwork开玩笑的应用程序
- Monster Cards-crx插件
- 完全以SwiftUI编写的带有滑动手势的入门/滑动器。-Swift开发
