GPU编程深入解析:CUDA与高性能计算
需积分: 10 54 浏览量
更新于2024-07-21
收藏 1.75MB PDF 举报
"GPU编程和CUDA技术的介绍,涵盖了GPU的发展、CPU与GPU的比较、GPU的应用和资源,以及CUDA编程、性能优化和矩阵乘法的例子。内容来源于2013年中国科学技术大学计算机学院的讲座资料,部分引用自'高小鹏等,通用计算中的GPU.中国计算机学会通讯,2009,5(11)'."
正文:
GPU编程和CUDA是高性能计算的重要组成部分,特别是在科学计算、数据分析和人工智能等领域有着广泛的应用。GPU,全称为图形处理器,最初是为了加速计算机图形处理而设计的,但随着时间的发展,它逐渐演变为一种能够进行通用计算的并行处理平台。
1. GPU与GPGPU
GPU原本专用于处理复杂的图形渲染和视频处理任务,但随着技术的进步,GPU开始支持通用计算,即GPGPU(General-Purpose Computing on GPU)。GPGPU使得GPU可以执行非图形相关的计算任务,如物理模拟、机器学习和大规模数据处理,极大地提升了计算效率。
1.2 GPU的发展阶段
GPU经历了三个主要发展阶段:
- 第一代GPU:仅提供部分硬件加速,如几何引擎,无法进行软件编程。
- 第二代GPU:增加了更多的硬件加速功能,如顶点级和像素级的有限可编程性。
- 第三代GPU:引入了如CUDA这样的编程环境,使GPU可以进行更复杂的编程,显著扩展了其应用范围。
2. CPU与GPU比较
CPU(中央处理器)擅长串行处理和复杂的控制逻辑,而GPU则在并行处理大量数据时表现出色。由于GPU拥有数千个计算核心,它们能同时处理多个任务,尤其适合执行重复性高、数据密集型的工作负载。
3. CUDA编程
CUDA是NVIDIA开发的一种并行计算平台和编程模型,它允许开发者直接利用GPU的计算能力。CUDA的核心是C/C++语言,通过添加特殊的函数和数据类型,程序员可以直接控制GPU的硬件资源。CUDA程序通常包含主机代码(在CPU上运行)和设备代码(在GPU上运行),通过CUDA API进行数据传输和计算任务调度。
4. 性能和优化
在GPU编程中,性能优化是关键。这涉及到数据对齐、减少内存访问延迟、有效利用并行度和避免不必要的数据传输等策略。例如,通过使用共享内存和纹理内存可以提高内存访问效率,而精心设计的计算算法可以充分利用GPU的并行性。
5. 示例:矩阵乘法
矩阵乘法是GPU计算的经典示例,因为它可以轻松地并行化。在CUDA中,可以通过将矩阵划分为较小的块,然后在每个GPU线程块内独立计算这些块的乘积来实现高效的矩阵乘法。
GPU编程和CUDA为解决大规模计算问题提供了强大工具,通过理解和掌握这些技术,开发者可以构建出运行速度远超传统CPU的高性能应用程序。

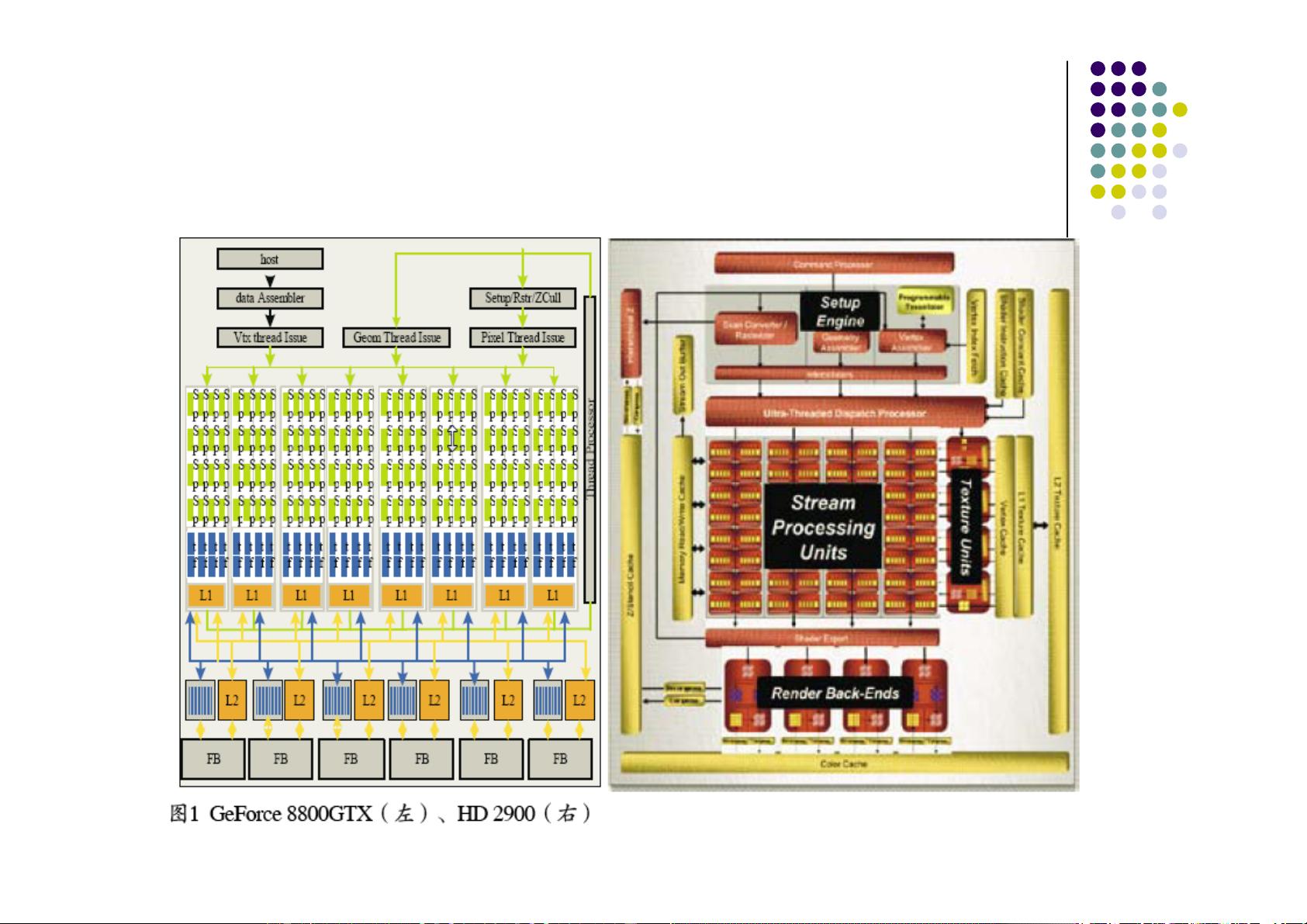
3.2 GPU的资源
NVIDIA CUDA Homepage
Contains downloads, documentation, examples and links
http://www.nvidia.com/cuda
Programming Guide
CUDA Forums
http://forums.nvidia.com
The CUDA designers actually read and respond on the
forum
Supercomputing 2007 CUDA Tutorials
http://www.gpgpu.org/sc2007/
CUDA中文网站
http://www.cuda.net/zone_tech.html



剩余108页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2011-01-12 上传
2014-07-25 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

ccdosccdos
- 粉丝: 0
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
