数据挖掘导论:聚类分析基础 - 第七章详解
需积分: 5 162 浏览量
更新于2024-07-09
收藏 2.94MB PPTX 举报
本章节主要介绍的是《数据挖掘导论(第二版)》的第七章——聚类分析,这是一个基础但至关重要的数据分析技术,它通过在数据中寻找内在的结构和模式,将对象分组成相似的群体(簇)。聚类分析的目标是无监督地识别数据对象之间的相似性,常用于生物学的层次结构分类、信息检索的检索结果分类、医学的病情诊断以及商业领域的客户细分,有助于数据简化、理解和预测。
首先,聚类分析的核心概念是将数据对象划分为不重叠的子集(簇),确保每个对象仅属于一个簇。在层次聚类方法中,形成了一种树状结构,如谱系图,每个节点代表一个簇,且有明确的层次关系。传统层次聚类遵循逐层合并的原则,而非传统的则可能涉及谱系图或非互斥的聚类,允许对象同时归属于多个组。
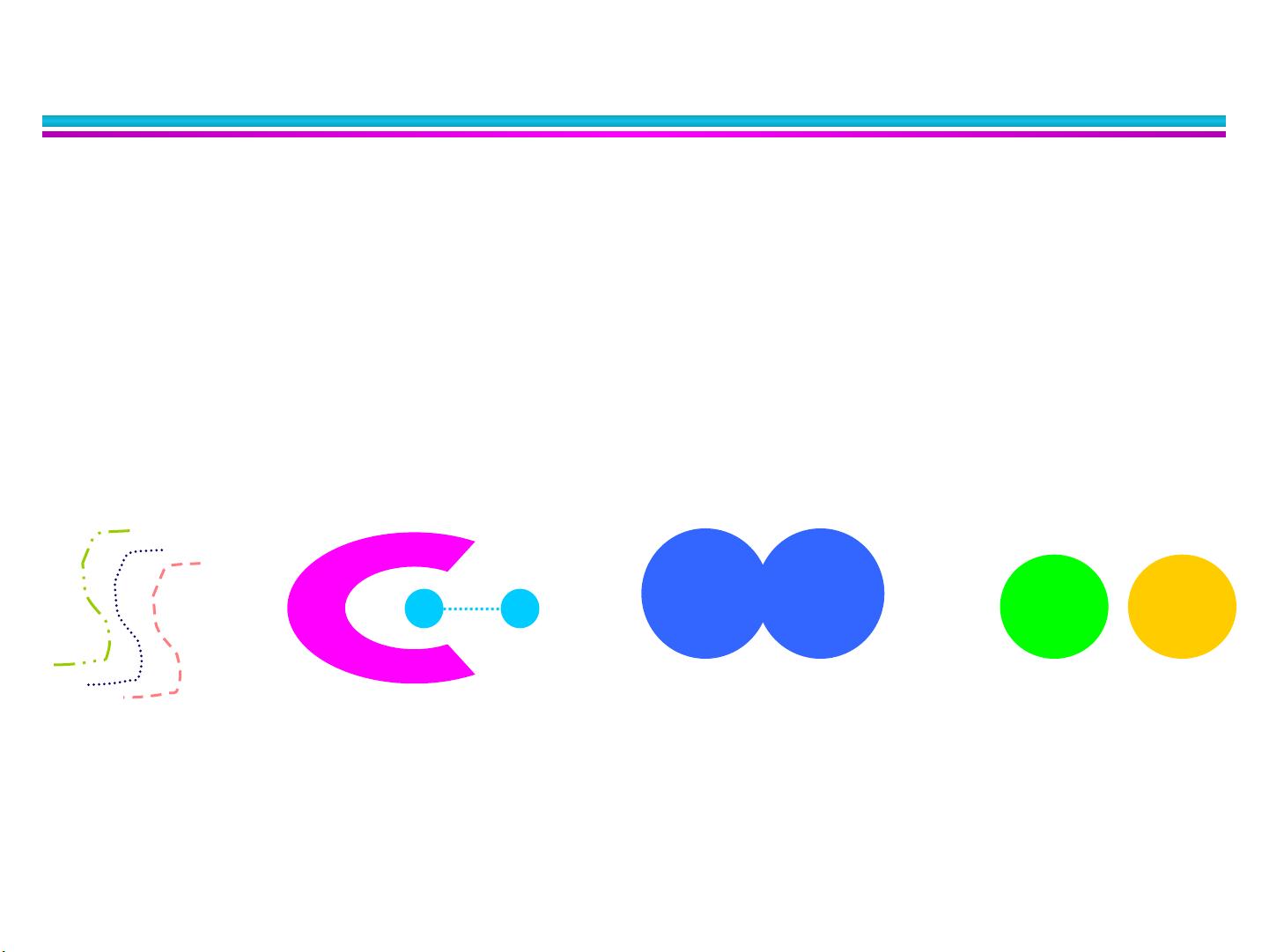
区分了几种主要的聚类类型,如明显分离的、基于原型的(如质心聚类,如K均值算法)、基于邻近的(如DBSCAN)和基于密度的聚类。每种类型强调不同的连接度和密度测量,例如,明显分离的簇强调对象间的紧密度,而基于密度的簇则关注高密度区域和周围低密度区域的对比。
在聚类过程中,度量因素至关重要,包括数据的维度、稀疏性以及属性类型,这些都会影响邻近度和密集度的计算。例如,对于高维数据,可能需要降维技术来提高效率。此外,聚类中心(如质心)的选择也对结果有显著影响,它们可能是所有点的平均值或最中心的点。
值得注意的是,聚类分析并不总是清晰的二元分类,而是可以处理模糊性和概率性,如模糊聚类和概率聚类。这两种方法允许对象在多个簇中具有不同程度的归属权,权值总和通常为1。最后,聚类分析有时可能面临选择问题,因为用户可能会根据特定兴趣或问题的复杂性选择只对某些部分数据进行聚类。
总结来说,聚类分析在数据挖掘中扮演着关键角色,它通过探索数据内在结构帮助决策者理解数据的复杂性,并为后续的分析和决策提供基础。理解和掌握各种聚类算法和类型,以及影响聚类效果的关键参数,是数据科学家和分析师必备的技能。
11/14/2020 11
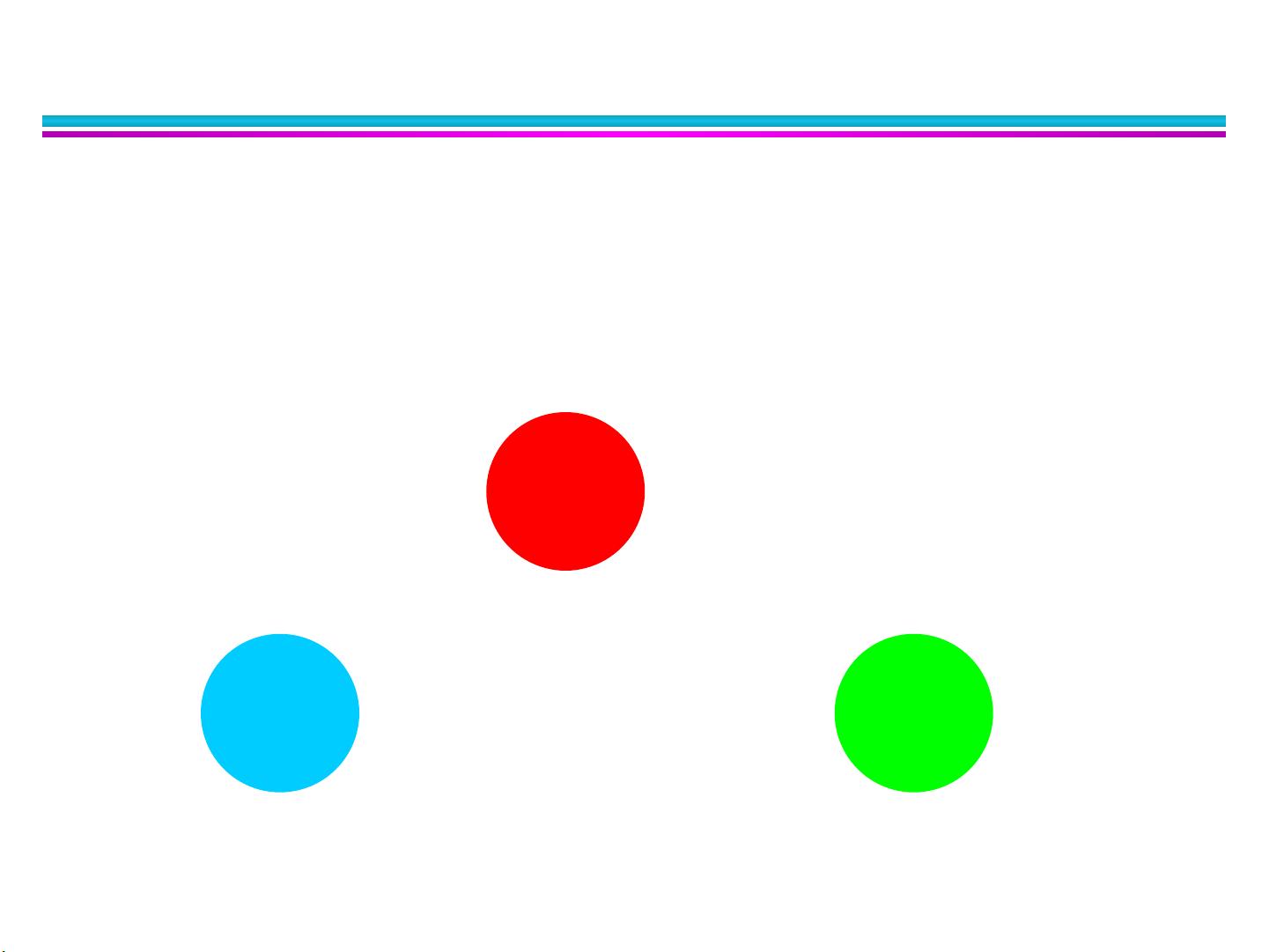
簇的类型 : 明显分离的
明显分离的簇 :
–
簇是对象的集合,其中每个对象到同簇中的每个对象的距离比
到不同簇中任意对象的距离都近 .
3 个明显分离的簇
剩余63页未读,继续阅读
3337 浏览量
401 浏览量
121 浏览量
2021-11-09 上传

hj_911
- 粉丝: 3
- 资源: 15
 我的内容管理
展开
我的内容管理
展开







