深度学习中的随机梯度下降详解与应用
需积分: 0 181 浏览量
更新于2024-08-05
收藏 1.4MB PDF 举报
随机梯度下降是一种优化算法,主要应用于机器学习中的神经网络模型训练,特别是在大规模数据集和深度学习中,由于计算效率的需求,它被广泛应用。本文基于《2012.李航.统计学习方法.pdf》的学习总结,介绍的是随机梯度下降的基本概念及其在深度学习中的应用。
随机梯度下降的核心思想起源于梯度法,即通过沿着函数梯度的反方向来寻找全局最小值。在深度学习中,网络的参数(如权重和阈值)非常多,传统的批量梯度下降(Batch Gradient Descent)由于需要计算所有训练样本的梯度,对于大规模数据集来说计算复杂度极高,效率低下。随机梯度下降(Stochastic Gradient Descent, SGD)则解决了这个问题,它每次仅使用单个或一小部分训练样本来更新参数,这样大大减少了计算时间。
1. 函数最小化背景
当我们训练神经网络时,目标是使预测输出(a)接近期望输出(y),通常通过最小化损失函数C,如均方误差(MSE)。损失函数表示为C(w, b),其中w和b是权重和偏置。由于实际问题中的参数维度可能非常高(例如百万级),直接使用二阶偏导数计算变得困难,因此需要寻找一种有效的求解策略,这时梯度下降方法就显得尤为重要。
2. 梯度下降原理
梯度下降的核心在于利用函数的局部梯度信息指导参数更新。在一个二维函数示例中,想象一个小球在曲面下滑,它总是朝向梯度的反方向移动,直到到达局部最小值。对于高维情况,随机梯度下降模拟了这个过程,每次迭代时仅使用一个训练样本来估计梯度并更新参数。
3. 随机梯度下降的实际操作
在随机梯度下降中,每次迭代选取一个随机的训练样本(x, y),计算该样本对应的小批量梯度,并沿此方向更新参数(w和b)。公式表达为:w_new = w_old - α * ∇C(w_old, b_old; x, y),其中α是学习率,决定每次更新的步长。这个过程不断重复,直至满足某个停止条件(如达到预设迭代次数或损失函数收敛)。
随机梯度下降是一种在大规模数据和高维参数空间中有效优化模型的重要方法,其优点在于计算速度快、易于实现,但可能会在局部最优处停滞,因此可能需要结合其他技巧(如动量、自适应学习率等)来提高性能。在实际应用中,它已经成为神经网络训练的标准工具之一。
2018/10/17 随机梯度下降 - baiyu9821179的专栏 - CSDN博客
https://blog.csdn.net/baiyu9821179/article/details/53489927 1/5
博客 学院 下载 图文课 TinyMind 论坛 APP 问答 商城 VIP会员 活动 招聘 ITeye GitChat
搜博主文章
写博客 发Chat
原
随机梯度下降
2016年12月06日 17:28:39 为爱存在 阅读数:877 标签: 神经网络 深度学习 随机梯度下降 更多
随机梯度下降( stochastic gradient descent )
简单的介绍一下什么是随机梯度下降,为什么要用随机梯度下降这个方法。
1.背景
在我们进行深度学习的时候,对于神经网络的输出结果,我们需要知道结果对不对,以及每个神经元的阈值和权重对不对,对于以及我调整一下权
神经网络的输出结果和我们预期的输出结果会更接近还是误差更大。如果更接近,那么我们可以继续调整权重和阈值,让神经网络的输出结果等于预期
何进行定量的分析呢?不能只依靠感觉,这个时候,我们引入函数
其中 代表我们预期的输出结果,比如说,一个识别手写阿拉伯数字的神经网络,我们网络的输出就是一个10维的向量,比如 代表0,
,而a代表一个神经网络实际输出的结果, 和 就分别代表了权重和阈值。也就是说,我们如果想要让一个神经网络的结果更准确,就需要找
,让C更小。即求函数C的最小值。
也就是说,我们现在是要求一个函数的最小值,让我们仅仅从数学方面思考,如何求解一个函数的最小值。假设有一个函数 ,而这个函数有两个
首先想到的就是微积分,假如只有2个变量,我们就要求出函数的二阶偏导,然后再令二阶偏导等于0,算出几个点,再判断这几个点哪个是最大值,哪
值,哪个是鞍点。可是问题是,我们处理的数据大部分都是多维的,甚至达到百万级别,所以用微积分的话,那就很难算出来了。因此我们就需要梯度
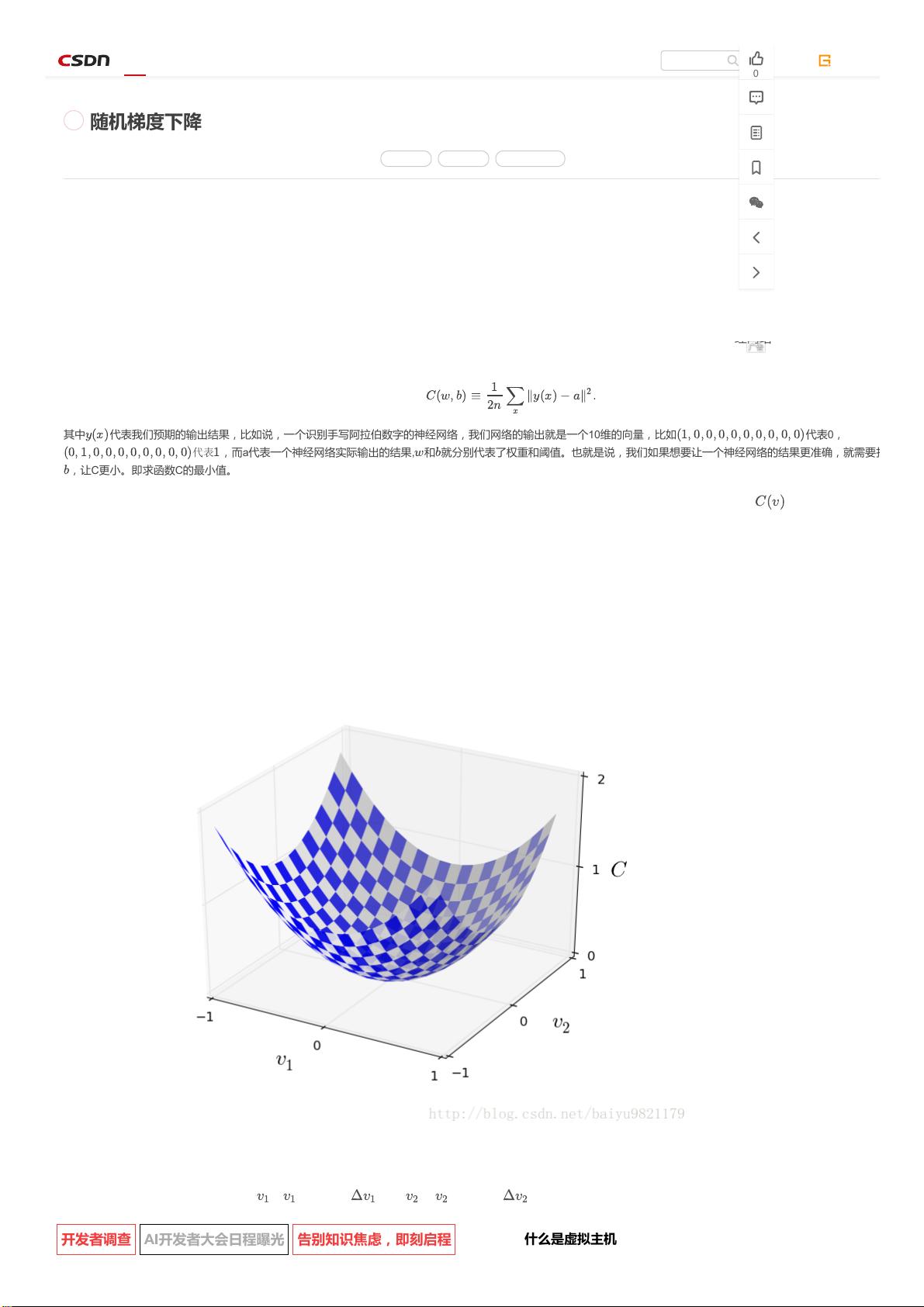
2.梯度下降的思想
我们先假设在求一个二元函数的最小值,它的图像如图所示:
假设我们在这个图像曲面上放置一个小球,它受到重力影响,肯定会往下滑落,而最终停止的地方,就是整个函数的最小值,这个就是梯度下降的
为了更清楚的说明这个问题, 我们把 在 方向移动 ,在 在 方向移动 ,根据微积分,我们可以得到:
C
(
w
,
b
) ≡ ∥
y
(
x
) −
a
.
1
2
n
∑
x
∥
2
y
(
x
) (1, 0, 0, 0, 0, 0, 0, 0, 0, 0)
(0, 1, 0, 0, 0, 0, 0, 0, 0, 0)
代表
1
w
b
b
C
(
v
)
v
1
v
1
Δ
v
1
v
2
v
2
Δ
v
2
Δ
C
≈ Δ + Δ .
∂
C
∂
v
1
v
1
∂
C
∂
v
2
v
2
0
开发者调查 AI开发者大会日程曝光 告别知识焦虑,即刻启程
什么是虚拟主机
下载后可阅读完整内容,剩余4页未读,立即下载
2022-09-14 上传
2020-08-16 上传
2023-09-08 上传
2023-08-04 上传
2024-09-09 上传
2024-09-09 上传

不美的阿美
- 粉丝: 23
- 资源: 292
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hadoop生态系统与MapReduce详解
- MDS系列三相整流桥模块技术规格与特性
- MFC编程:指针与句柄获取全面解析
- LM06:多模4G高速数据模块,支持GSM至TD-LTE
- 使用Gradle与Nexus构建私有仓库
- JAVA编程规范指南:命名规则与文件样式
- EMC VNX5500 存储系统日常维护指南
- 大数据驱动的互联网用户体验深度管理策略
- 改进型Booth算法:32位浮点阵列乘法器的高速设计与算法比较
- H3CNE网络认证重点知识整理
- Linux环境下MongoDB的详细安装教程
- 压缩文法的等价变换与多余规则删除
- BRMS入门指南:JBOSS安装与基础操作详解
- Win7环境下Android开发环境配置全攻略
- SHT10 C语言程序与LCD1602显示实例及精度校准
- 反垃圾邮件技术:现状与前景
