Canoco CCA数据处理详解:Excel准备与WCanoImp操作指南
本文主要解析了如何使用Canoco进行CCA (Canonical Correspondence Analysis) 数据处理的详细步骤。首先,数据准备工作至关重要,需确保数据格式为Excel表格中的矩形形式,样本编号和变量名称清晰明了,且不超过8个字符。所有数值数据应占据表格主体,定性变量需转换为哑变量。在数据整理完成后,通过复制到剪贴板,利用WCanoImp工具导入。
在WCanoImp程序中,用户需要根据数据的原始结构进行相应设置。若数据是标准的样方-变量格式,第一选项通常不选;若数据结构特殊,如列代表样方,行代表变量,则应勾选“Each column is a Sample”。同时,程序会自动生成样本编号或提供选项让用户输入。关于数据类型,除非存储空间紧张,否则通常无需选择压缩格式。
数据导入后,用户需选择保存文件的位置、命名,并添加一个用于识别的标注。这个标注将出现在数据内容的第一行。接下来,程序会提示保存成功,并展示数据的参考模式,以及对话框中的选项,其中包含了回归预测器(解释变量)的信息,这是CCA分析的核心,用于确定坐标轴以找到最佳预测变量之间的关系。
整个过程旨在确保数据的准确性和可用性,以便进行有效的CCA分析,从而揭示生态系统中物种与环境因素之间的关系,这对于生态学研究和理解生物多样性具有重要意义。通过细致的操作和理解,研究人员可以充分利用Canoco的强大功能,挖掘数据背后的科学信息。
基于 Canoco 的 CCA 数据处理过程解析
一、 数据处理
1、数据格式要求
在 Excel 表格里面,你必须将数据做成矩形形式。默认的方式(也是常用的方式)
是一行代表一个样方,一列代表一个变量。表格左顶格最好是空着。最好第一列和第
一行分别有样方编号和变量的名称。必须注意的是名称不能超过 8 个字符,如果超过 8
个字符,CANOCO 会自动截取前 8 个字符作为名称。变量名称最好是英文字母、数字 、
圆点或是连字符,空格也可以。
除了第一行和第一列,表格内剩下的填充内容必须是数字或是空着,绝对不能使
用字符型数据。定性变量(因子)必须转换为哑变量( 0‐1 数据)方可进入 CANOCO
分析。
当数据在 Excel 表格里按要求整理好后,将包含数据的矩形方阵选定,然后选择
“复制”按钮,此时数据便复制到剪贴板中。WCanoImp 便可以从剪贴板中读取数据。如
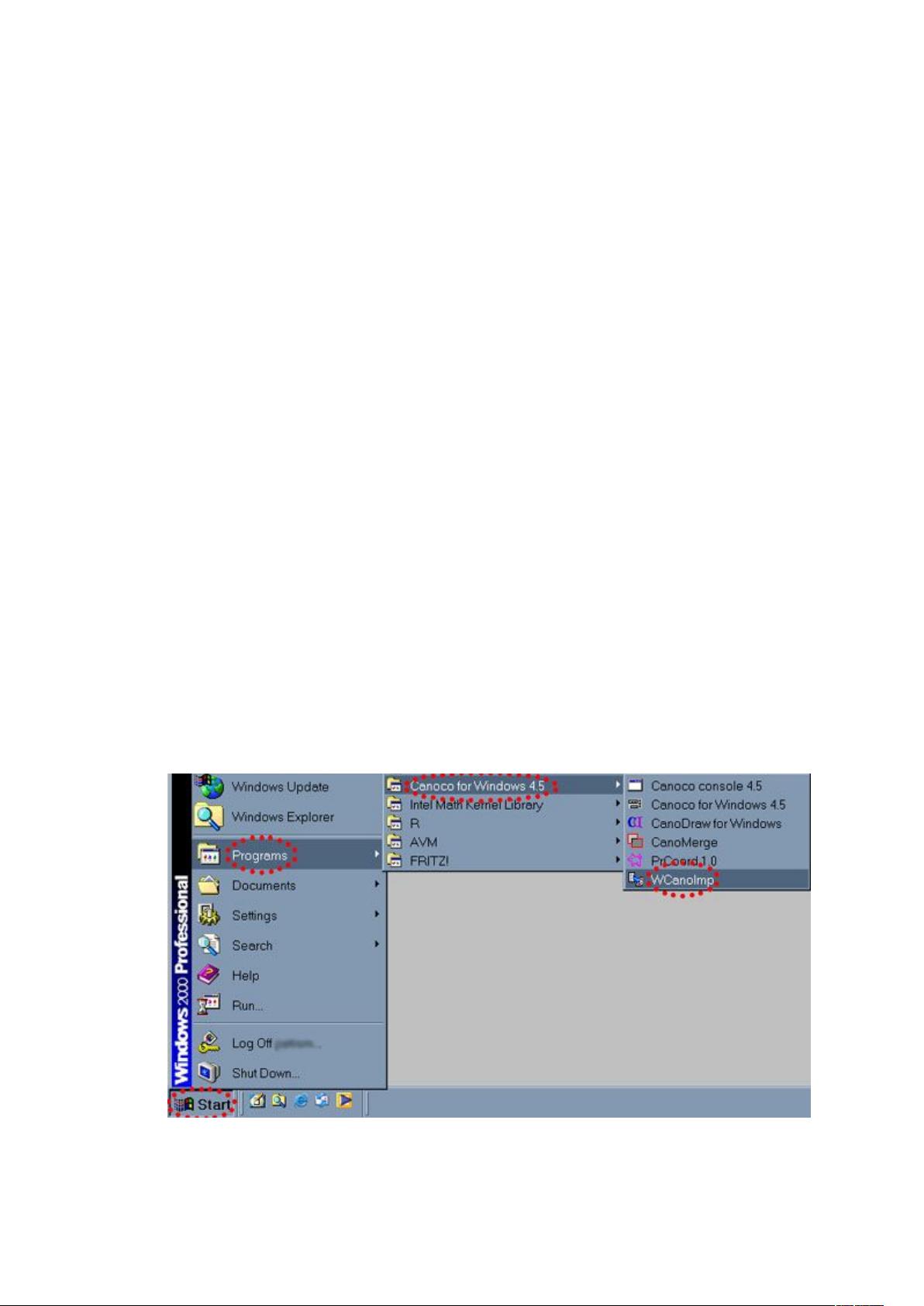
图 1‐2a 所示,WCanoImp 可以从“开始”菜单中 Canoco for windows 下来菜单中打开。此
时会弹出 WCanoImp 对话框,上半部分包含如何使用该程序的简短信息,下半部分是
一些可选框。如果在 Excel 表格数据是按照默认方式组织你的数据,第一选项不必选,
相反,如果是数据结构正好相反,以列代表样方,以行代表变量,必须选中这个“Each
column is a Sample”选项。除非你的数据是样方很少而变量很多(Excel 表格里面列数不
能超过 256 列),否则不推荐用这种方式组织数据。如果你没有样方或是变量没有编号
或 是 名 称 , 可 以 选 择 下 面 两 个 选 框 , 程 序 会 帮 你 给 各 行 各 列 附 上 默 认 名 称
(Sample1,)。最后一个选项是问你是否存为压缩型数据类型,除非你觉得硬盘空间不
够大,否则不必选这个选项,是否选这个选项中对于分析结果毫不影响。
当你确定所以的选择是正确的,你就可以按下 save 按钮,系统弹出新的对话框让
你选择保存新文件地方和取个文件名,之后会让你给这个文件加个标注,这个标注内
容将显示在新文件的数据内容第一行,以便日后数据内容的识别。选定确认后,程序
会告诉你保存成功。
图 1‐2a WCanoimp 程序打开途径
下载后可阅读完整内容,剩余5页未读,立即下载
2011-04-02 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

doukezhhiwu
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
