数据库排序实现技术探析
50 浏览量
更新于2024-07-14
收藏 506KB PDF 举报
"这篇文章是Goetz Graefe在2006年发表的关于在数据库系统中实现排序的技术探讨。文章指出,大多数商业数据库系统利用了许多公开但研究文献中不常见的排序技术,这些技术能提升现代计算机系统上的排序性能,并使系统在多用户操作中面对资源波动时能更好地适应。该文收集了这些技术,方便学生、研究人员和产品开发者参考。内容涵盖内存排序、磁盘外部排序以及数据库系统特有的考虑因素。"
在数据库系统中,排序是一个核心的操作,它涉及数据的组织、访问方法和查询处理。文章深入讨论了以下知识点:
1. **内存排序**:在内存中进行排序时,文章可能涵盖了快速排序、归并排序、堆排序等经典算法,同时可能也探讨了如何优化这些算法以适应现代计算机的多核架构和动态内存管理。
2. **磁盘外部排序**:当数据量超出内存容量时,需要在磁盘上进行排序。外部排序通常涉及到多个阶段,如多路归并和缓冲区管理。文章可能讨论了如何有效地管理磁盘I/O,减少磁盘交换,以及如何通过数据压缩来提高排序效率。
3. **数据库系统的特殊考虑**:数据库排序不同于一般的数据结构操作,因为它们需要考虑到事务处理、并发控制和一致性。文章可能讨论了如何在保持ACID属性的同时实现高效排序,以及在数据库系统中如何处理键的规范化和条件化。
4. **资源管理**:在多用户环境中,数据库系统必须能够优雅地应对资源波动。这可能包括动态内存资源分配、资源的优雅降级策略,以及如何避免因资源争抢导致的性能下降。
5. **并发和异步操作**:在数据库系统中,排序可能与并发查询和更新操作交织在一起。文章可能会介绍如何使用锁、多线程或异步处理来确保排序过程的正确性和性能。
6. **关键字和短语**:文章还可能涉及了键的标准化(Key normalization)、键的预处理(Key conditioning)、数据压缩、动态内存资源分配、优雅降级(Graceful degradation)、嵌套迭代(Nested iteration)和异步处理(Asynchronous processing)等技术细节,这些都是优化数据库排序的关键因素。
通过这篇文章,读者可以深入了解数据库系统中的排序机制,以及如何在实际应用中提高排序性能和系统的鲁棒性。对于数据库设计者和开发者来说,这些技术和概念具有很高的实用价值。

Implementing Sorting in Database Systems 7
Fig. 4. Order-preserving dictionary compression.
symbol has been encountered for the first time. Alternatively, encoding or decoding
may start with a tree constructed for static order-preserving Huffman compression
based on a fixed sample of text. Hybrids of the two approaches are also possible, that
is, starting with a nonempty tree and developing it further if necessary. Similarly, a
binary tree with leaves containing strings rather than single characters can be used for
order-preserving dynamic dictionary encoding. A separate parser must cut the input
into encoding units, which are then encoded and decoded using a binary tree.
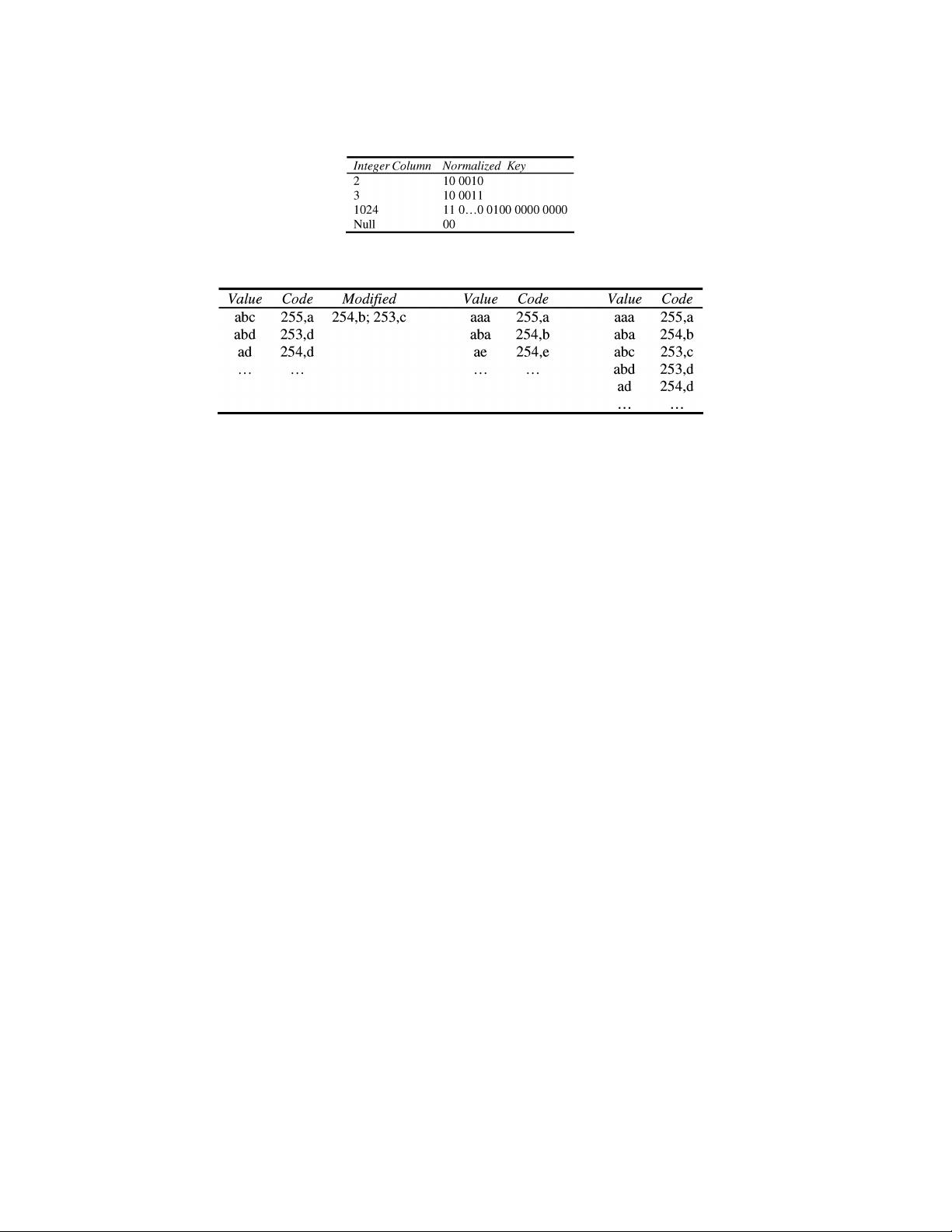
When run-length encoding and dictionary compression are modified to be order-
preserving, the symbols following the substituted string must be considered. When a
new string is inserted into the dictionary, the longest preexisting prefix of a new string
must be assigned two encodings, rather than only one [Antoshenkov et al. 1996]. For
example, assume that a dictionary already contains the string “the” with an appropri-
ate code, and the string “there” is to be inserted into the dictionary with its own code. In
this case, the string “the” must be assigned not one, but two codes: one for “the” strings
followed by a string less than “re,” and one for “the” strings followed by a string greater
than “re.” The encoding for “there” might be the value 124, and the two encodings for
“the” are either 123 or 125, depending on its continuation. Using these three codes, the
strings “then,” “therefore,” and “they” can be compressed based on the encodings. The
prefix “the” within “then” requires code 123, whereas “the” within “they” requires code
125 such that “then,” “therefore,” and “they” can be sorted correctly.
Figure 4 illustrates the idea and combines it with earlier concepts about adaptive
order-preserving Huffman compression. At some point, the string “the” has an encoding
or bit pattern assigned to it in the example ending in “1.” When the string “there”
is introduced, the leaf node representation of “the” is expanded into a small subtree
with 3 leaf nodes. Now, the compression of “the” in “then” ends in “10” and of “the”
in “they” ends in “111.” The compression of “there” in “therefore” ends in “110,” which
sorts correctly between the encodings of “then” and “they.” The newly created subtree
in Figure 4 is right-deep based on the assumption that future text will contain more
occurrences of “the” sorting lower than “there” than occurrences sorting higher than
“there.” Subsequent tree rotations may optimize the compression scheme further.
Dictionary compression is particularly effective for long strings of padding charac-
ters (e.g., white space in fixed-size string fields) and for default values. Of course, it
is also related to the normalization of NULL values, as described earlier. A useful ex-
tension uses multiple bits to compress NULL, default, and otherwise frequent values.
For example, 2 bits (instead of only 1 bit for NULL values) permit one value for NULL
values (“00”) that sort lower than all valid data values, one for the default value (“10”),
and two for actual values that are smaller or larger than the default value (“01” and
“11”). For example, the value 0 is a frequent value in many numeric columns, so the
2-bit combination “10” may indicate the column value 0, which does not need to be
stored explicitly, “01” indicates negative values, and “11” indicates positive values. If
multiple frequent values are known a priori, say 7 values in addition to NULL, then
ACM Computing Surveys, Vol. 38, No. 3, Article 10, Publication date: September 2006.
剩余36页未读,继续阅读
2010-03-06 上传
2018-11-21 上传
2009-11-27 上传
点击了解资源详情
点击了解资源详情
2024-10-17 上传
2024-10-17 上传
2024-10-17 上传

weixin_38707826
- 粉丝: 5
- 资源: 907
 我的内容管理
展开
我的内容管理
展开







最新资源
- 新型智能电加热器:触摸感应与自动温控技术
- 社区物流信息管理系统的毕业设计实现
- VB门诊管理系统设计与实现(附论文与源代码)
- 剪叉式高空作业平台稳定性研究与创新设计
- DAMA CDGA考试必备:真题模拟及章节重点解析
- TaskExplorer:全新升级的系统监控与任务管理工具
- 新型碎纸机进纸间隙调整技术解析
- 有腿移动机器人动作教学与技术存储介质的研究
- 基于遗传算法优化的RBF神经网络分析工具
- Visual Basic入门教程完整版PDF下载
- 海洋岸滩保洁与垃圾清运服务招标文件公示
- 触摸屏测量仪器与粘度测定方法
- PSO多目标优化问题求解代码详解
- 有机硅组合物及差异剥离纸或膜技术分析
- Win10快速关机技巧:去除关机阻止功能
- 创新打印机设计:速释打印头与压纸辊安装拆卸便捷性
