"Hadoop分析涉及HDFS元数据解析、元数据备份方案机制、NameNode类的功能与角色以及HDFS NameNode的双机热备份方案。HDFS的元数据由NameNode维护,包括内存元数据和元数据文件,如FSImage和edits。文件寻址流程从Client开始,通过INode和BlockInfo找到DataNode。FSImage和edits用于备份,FSImage在检查点过程中变为FsImage.ckpt,而edits变为edits.new。NameNode的format操作会遍历元数据存储目录并询问用户是否进行格式化。"
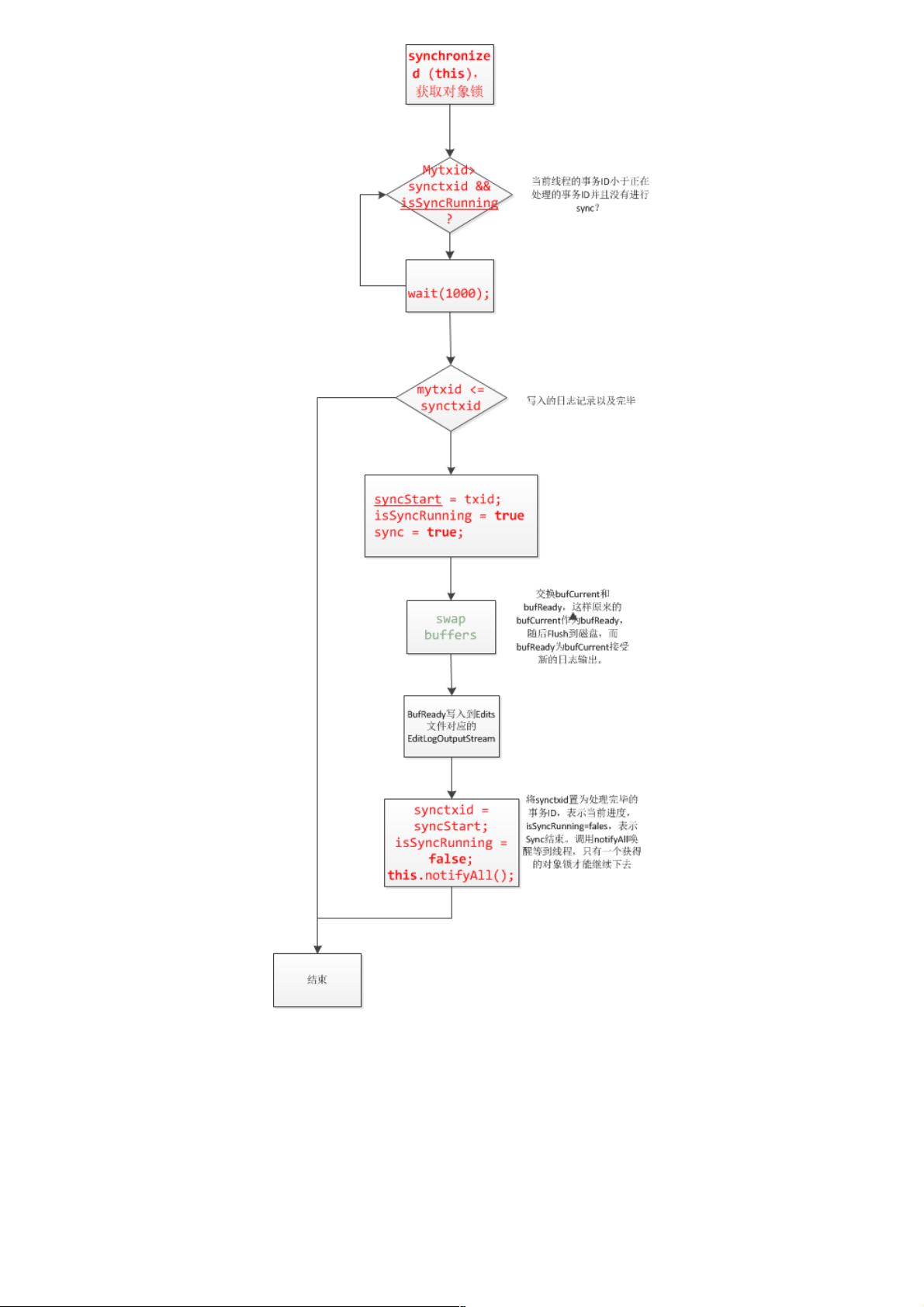
在Hadoop分析中,HDFS(Hadoop Distributed File System)的元数据管理是其核心部分,负责跟踪文件系统中的文件和目录信息。元数据包括内存中的信息和持久化的FSImage与edits文件。NameNode是HDFS的主要组件,它负责管理整个元数据。当HDFS启动时,NameNode将加载FSImage到内存中,该文件包含了HDFS的初始状态,而edits文件记录了自上次检查点以来的所有更改。
元数据备份策略采用了FSImage和edits的组合。FSImage是一个静态文件,包含了HDFS的元数据快照,而edits文件则记录了对这些元数据的修改。每当需要创建检查点时,NameNode会将当前的FSImage和edits合并成一个新的FSImage,并清空edits,同时创建一个新的edits.new文件来记录后续的更改。这一过程确保了即使NameNode故障,也可以通过恢复最新的FSImage和edits来重建文件系统状态。
寻查文件路径的过程是从客户端开始,通过文件路径查找对应的INode,INode包含了文件或目录的信息。接着,从INode获取BlockInfo,BlockInfo代表文件内容的物理分块。最终,DatanodeDescriptor提供了关于具体存储这些Block的DataNode的信息。
Hadoop分析还包括NameNode的双机热备份方案,这通常通过HA(High Availability)模式实现,包括两个处于活动和备用状态的NameNode。当主NameNode故障时,备用NameNode可以接管,确保服务的连续性。这种机制依赖于ZooKeeper协调服务,以决定哪个NameNode是活动的,并在需要时进行安全的故障切换。
在进行NameNode格式化时,`format`函数会在配置指定的目录中遍历所有的元数据存储位置,并询问用户是否确认要清除现有数据。这是初始化NameNode或恢复损坏文件系统状态的重要步骤。
Hadoop分析涵盖了HDFS的元数据管理、备份策略、NameNode的角色以及高可用性设置,这些都是理解Hadoop分布式文件系统运行的关键知识点。通过深入理解这些概念,可以更好地优化Hadoop集群的性能和稳定性。


 我的内容管理
展开
我的内容管理
展开









