斗地主RL模型:挑战与策略
需积分: 0 3 浏览量
更新于2024-08-05
收藏 1.12MB PDF 举报
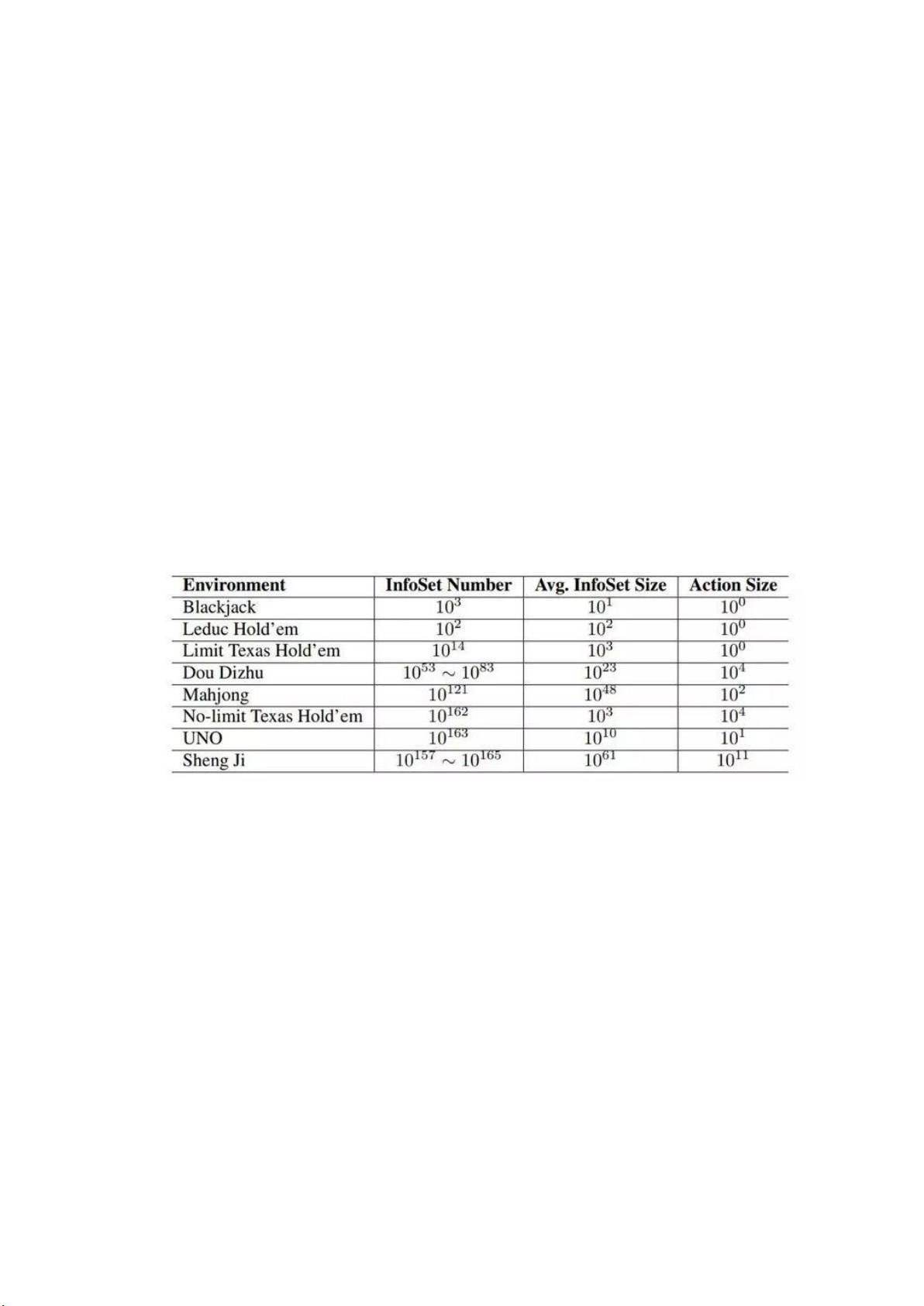
斗地主RL模型是一种应用于斗地主游戏的人工智能策略,它面临着一系列独特的挑战。首先,游戏中的行动空间极其庞大,每一步决策都牵涉到众多可能的牌组组合,例如飞机带几张单张,这需要高效的搜索算法和采样技术来处理,如宽度优先搜索,以减少搜索空间的复杂性。表1中的RLCard工具通过估计牌类的复杂度来辅助决策。
其次,动作的价值评估是关键。由于牌组在不同情境下的价值会有所变化,如在不同阶段和玩家身份下,同样的牌组合可能有不同的效果。模型需要不仅考量当前的可选动作,还要预测后续可能产生的牌组组合和整体局势,包括对家和队友的状态。此外,由于是不完全信息博弈,模型需要处理隐藏信息,避免被对手的未知优势所误导。
第三,身份转换带来的决策差异很重要。作为地主,是否选择叫地主,可能会影响整个游戏的走向;作为农民,则需要考虑合作与策略。玩家的行为习惯和个性揣测也是模型必须考虑的因素,如何根据对手出牌规律判断其真实意图,是提高胜率的关键。
最后,模型的训练环境和数据多样性是个挑战。由于不同玩家的思维方式和策略各异,模型需要具备适应性和泛化能力,能够在各种类型的玩家中找到最佳策略。斗地主中的语言隐喻,就像中文的多义性,提示了模型需要理解牌的组合背后的丰富含义,才能做出最精确的决策。
斗地主RL模型需要综合运用搜索算法、动态评估、信息推理和策略适应性等技术,以在复杂的牌局环境中寻找最优策略,这是人工智能在具体游戏场景中应用的典型例子。
斗地主 RL 模型
任务介绍
斗地主是一种扑克游戏。游戏最少由 3 个玩家进行,用一副 54 张牌(连鬼牌),其中一
方为地主,其余两家为另一方,双方对战,先出完牌的一方获胜。
潜在问题与解决思路
潜在问题
1.行动空间庞大,举个例子飞机带几个单张,有超多种可能。需要进行动作空间的搜索和
简化、采样。
表 1:RLCard 中牌类复杂度估计
2.动作的价值估计。首先,在不同对局、不同时段中,同样的牌组(合理的牌组合,如单
张、对子、三带一等)表现的信息是不同的。其次,每一次行动并不只是比较可选动作集
而已,还要考虑每次出牌后的牌组集合价值,与对家的关系、与队友的关系(农民)等整
体状态、策略。
3.不完全信息博弈。手上的牌有时非常好,但是不可见的是,已被对手完全的克制,实际
上这一局完全没有胜利的希望,这样模型学习起来往往是无益的。
4.不同阶段不同身份,存在不同的分析决策方式。我的牌很好,但是叫地主?也许会破坏
牌!牌很差,但是差几张就会顺?搏一搏,也许胜率更高!地主独自战斗,农民之间又讲
究协作。
5.人格揣测。根据每一位选手的出牌规律、习惯,猜测 ta 手上的余牌—>虚张声势?or 确
有其事?or 声东击西...从对家的出牌中学习知识,也要结合自身的牌,理性思考。
6.试验环境与数据。不同的玩家思维/策略不同,模型的分析能力未必适用。
下载后可阅读完整内容,剩余8页未读,立即下载
114 浏览量
105 浏览量
121 浏览量
2022-08-08 上传
2009-08-24 上传
2022-08-08 上传
2022-08-08 上传
2022-09-21 上传
2022-09-24 上传

生活教会我们
- 粉丝: 33
- 资源: 315
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
