HBase二级索引实现与设计
"HBase二级索引实现方案,参照华为公布方案,设计了HBase二级索引机制,旨在提高查询效率,通过为DataTable创建对应的IndexTable并保持两者在RegionServer上的对应,实现局部索引功能。"
HBase是一个分布式的、面向列的NoSQL数据库,它在大数据处理和实时分析中被广泛应用。然而,HBase原生支持的一级索引(RowKey索引)在某些复杂的查询场景下效率较低,因此二级索引成为提高查询性能的关键。
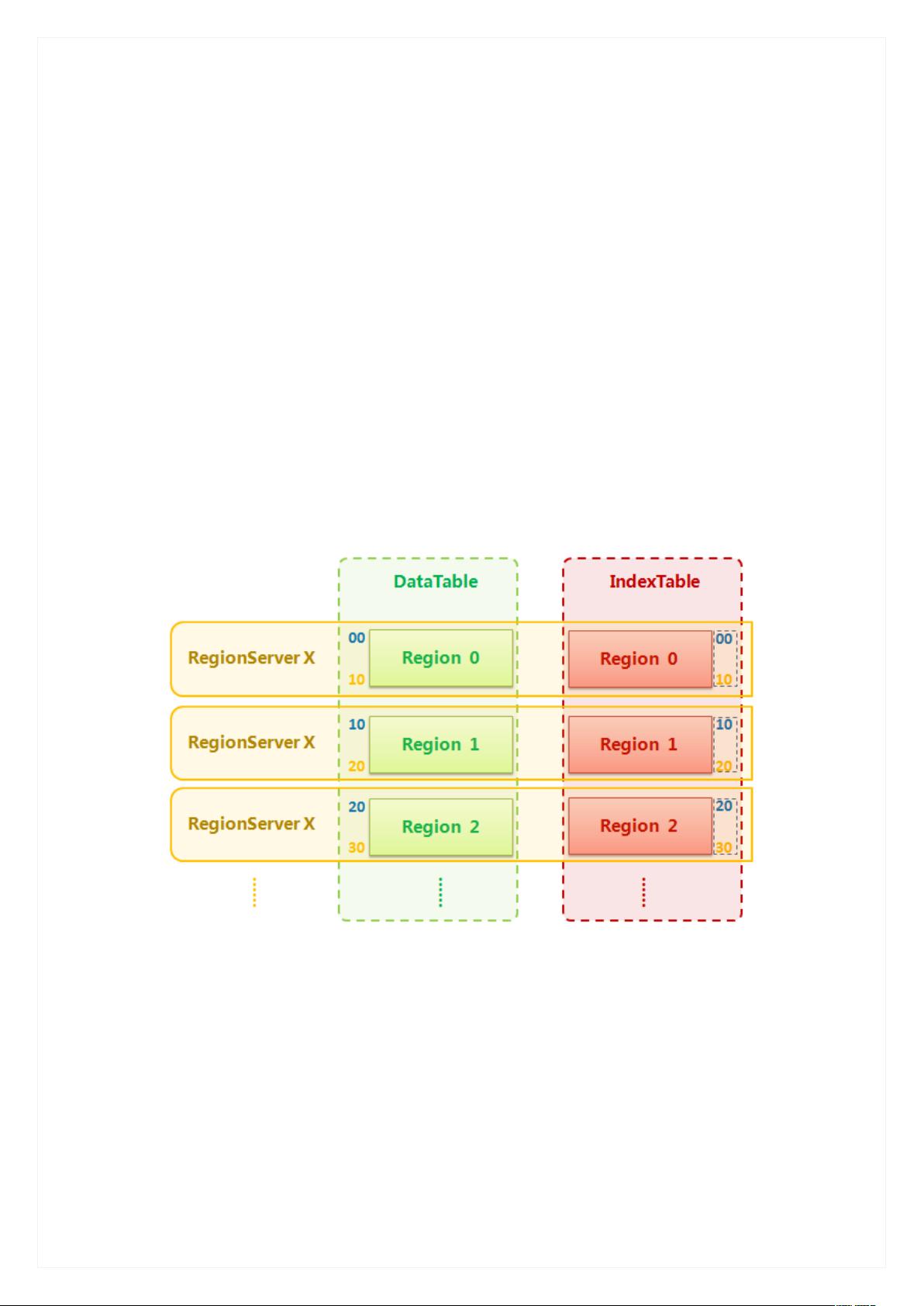
在华为提出的HBase二级索引实现方案中,主要目标是为每个DataTable创建一个对应的IndexTable,确保它们的Region在物理上一一对应,并存储在同一RegionServer上。这样的设计能够使索引查询更加高效,因为只需要在相对较小的IndexTableRegion中查找,然后直接定位到DataTableRegion读取数据。
1. **IndexTable的创建**
创建IndexTable有两种情况:一是创建新DataTable时同步创建;二是对已有DataTable,用户可以动态添加索引。创建过程涉及获取DataTable的所有RegionInfo,利用StartKey来指导IndexTable的分割和创建,确保IndexTableRegion与DataTableRegion的一一对应。
2. **IndexTableRowKey设计**
IndexTableRowKey的设计至关重要,因为它决定了索引的查询效率。IndexTableRowKey由四部分构成:
- A.DataTableRegionStartKey:作为RowKey的开头,用于快速定位到相应的DataTableRegion。这有助于减少索引扫描的范围,因为相同StartKey的记录会存储在一起。
- B.IndexName:标识索引类型,便于多索引管理。
- C.IndexValue:根据索引字段的值,是实际查询条件。
- D.DataTableRowKey:原DataTable的RowKey,用于在找到匹配的IndexRow后,准确地定位到DataTable中的数据。
3. **查询流程**
当执行查询时,首先在IndexTable中进行查找,匹配IndexValue。找到的每个匹配项都会提供一个DataTableRowKey,然后系统使用这些RowKey直接从DataTable对应的Region中读取数据。这种方式避免了全表扫描,显著提高了查询速度。
4. **优化与维护**
为了保持二级索引的有效性,需要在DataTable数据更新时同步更新IndexTable。此外,可能还需要定期进行索引重建或优化,以应对数据分布的变化和Region分裂。
HBase二级索引是一种提升查询性能的策略,通过精心设计的数据结构和索引更新机制,实现了在大数据场景下的高效查询。这种方案在处理复杂查询需求时,尤其能展现其优势。
HBase 二级索引实现方案
——ODP
说明:本方案主要参照了华为公布的
HBase
二级索引实现方案。
1. 概要设计
主要思路:为每个 DataTable 创建一个与之对应的 IndexTable,通过各种途径,保证
IndexTable Region 与 DataTable Region 一一对应,并且存储在同一个 RegionServer 上,存储
结构如图 1 所示。最终要实现的效果是,每个 IndexTable Region 是对应的 DataTable Region
的局部索引,使用索引进行查询时,将对每个 IndexTable Region 进行检索,找出所有符合
条件的 DataTable RowKey,再根据 DataTable RowKey 到对应的 DataTable Region 中读取相应
DataTable Row。
图 1 HBase 二级索引存储结构示意图
2. 详细设计
2.1. IndexTable 的创建
IndexTable 的创建主要出现在两个时机,一是创建新 DataTable 时,系统根据索引定义,
下载后可阅读完整内容,剩余5页未读,立即下载
548 浏览量
518 浏览量
214 浏览量
748 浏览量
215 浏览量
178 浏览量
119 浏览量
点击了解资源详情

chengchaoli
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 保险行业培训资料:胡萝卜、鸡蛋、咖啡豆
- pts后处理
- lms2021.1
- neo4j-community-3.5.13-windows.zip
- Computational_Physics:3月优先注意事项
- Gymzzy-Demo:演示Gymzzy角站点托管
- 电子功用-带滤波功能的轮椅电机
- MyPasswords:个人密码管理器-开源
- partners:Qiskit合作伙伴计划的主要存储库
- 保险行业培训资料:目标市场增员
- 随机生成70多万的网名数据
- codecon2015samples:AsyncAwait的TypeScript a Babel在CodeCon 2015之前的示例
- 电子功用-圆柱形锂离子电池化成分容设备
- sphinx-html-multi-versions:允许在 Sphinx 生成的文档中切换产品版本的简单模板和包含脚本
- 搏斗
- neo4j-community-3.5.13-unix.tar.gz
