HBase二级索引实现与优化
需积分: 48 162 浏览量
更新于2024-07-23
收藏 619KB PDF 举报
"本文档主要介绍了在HBase中创建二级索引的方法,以解决HBase原生不支持字段多维索引的问题。文档作者是华为公司的Anoop Sam John,他在Hadoop开发方面有深入研究,并积极参与Apache HBase社区的贡献。"
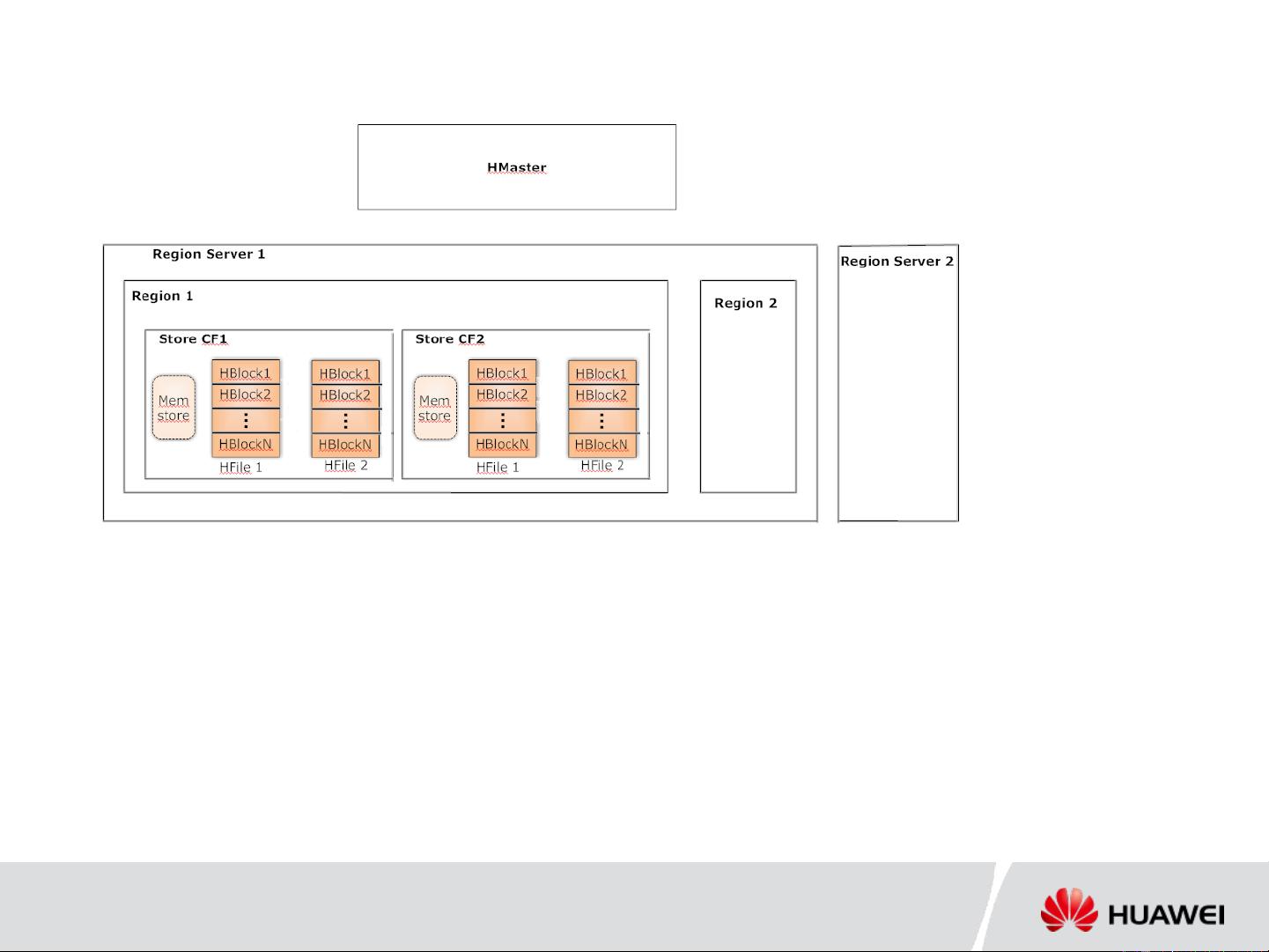
在HBase中,二级索引是一种扩展其原生功能的手段,因为HBase本身并不直接支持基于字段的多维索引。这在处理大数据量且需要高效查询的场景下显得尤为重要。HBase的设计基于列式存储,将表分割成多个Region,每个Region包含一个或多个列族(ColumnFamily),数据以列族的形式组织。内存中的数据存储在Memstore中,当达到一定阈值后,Memstore的内容会被持久化到HDFS上的HFile中,这些HFiles被逻辑上划分为更小的块以便于数据的读写。
然而,HBase在执行带有条件的列值扫描时,效率较低,尤其是在数据稀疏且数据量庞大的情况下。这是由于HBase的默认查询机制依赖于行键(Row Key)排序,对于非行键的查询,必须遍历整个Region来查找匹配的记录,这可能导致性能瓶颈。
二级索引的引入旨在解决这个问题。二级索引为特定的列创建额外的数据结构,使得查询可以直接定位到满足条件的行,而无需全表扫描。通常,二级索引会维护一个指向原始行键的指针,这个指针存储在另一个表(也称为索引表)中,根据索引列的值进行组织。这样,当查询指定列的值时,可以通过索引表快速找到对应的行键,然后在主表中获取完整数据。
在实现HBase二级索引时,需要注意几个关键点:
1. **索引设计**:需要考虑索引列的选择,通常选择经常用于查询的列。
2. **索引更新**:数据修改时,需要同步更新二级索引,以保持数据一致性。
3. **查询优化**:合理利用二级索引可以提高查询效率,但过度依赖索引可能导致额外的写入开销和存储空间占用。
4. **监控与维护**:定期检查索引的使用情况和性能,适时调整索引策略。
HBase二级索引的实现可以采用社区的一些开源解决方案,如HBase-Indexer、Phoenix等,它们提供了创建和管理二级索引的工具和API。通过这些工具,开发者可以在不改变HBase核心架构的前提下,增强HBase的查询能力,提高大数据环境下的应用性能。
HBase二级索引是应对大数据查询需求的一种有效策略,它能够帮助优化基于列值的查询,减少不必要的数据扫描,从而提升整体系统的响应速度。同时,由于HBase本身并未内置索引机制,因此在实际应用中,需要谨慎设计和管理二级索引,以确保最佳的性能和数据一致性。
HUAWEI TECHNOLOGIES CO., LTD.
Slide title :32-35pt
Color: R153 G0 B0
Corporate Font :
FrutigerNext LT Medium
Font to be used by customers
and
partners :
Arial
Slide text :20-22pt
Bullets level 2-5:
18pt
Color:Black
Corporate Font :
FrutigerNext LT Medium
Font to be used by customers
and
partners :
Arial
Top right corner
for field-mark,
customer or partner
logotypes.
----------------
The following nine
groups of colors
are an example of
how our design
colors can be used,
please take note
that you should
only use one
design color group
per slide.
For specific usage
details, refer to the
“Typesetting
Standard”.
Master, Region servers
Table split into regions
Columnar storage, Column family
Memstore, Hfiles in DFS
Hfiles logically split into smaller blocks, data write/read as blocks
HBase Recap
Page 4
剩余17页未读,继续阅读
2018-04-12 上传
2018-01-22 上传
2021-01-07 上传
2015-04-08 上传
2014-10-23 上传
2021-05-17 上传
点击了解资源详情
点击了解资源详情
2023-05-09 上传

chenyaodian123
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 虚拟人中台相关方案文档
- unity 3D文字系统源码VText.zip
- madgrad:MADGRAD的JAX实现
- SimpleHUD:SimpleHUD是一款易于使用但美观的Android HUD(或对话框)
- 汇编语言程序设计(资料+视频教程).rar
- 信呼协同办公OA系统 v2.1.8
- meelouth.github.io:网站
- bank-java:一个用 Java 编写的带有 GUI 的基本银行程序
- 亚马逊交易-crx插件
- stylex
- Data-Analysis-Project-in-Python:Python中Fifa 18数据集的数据分析。 该项目包括可视化和用于预测目的的机器学习
- glslmath:C ++仅限头文件的库,可模拟GLSL数学-开源
- TongYWPF.Template.NumberOne202303DemoK
- 剁手党买家秀助手-crx插件
- ExpandTabView-master
- React
