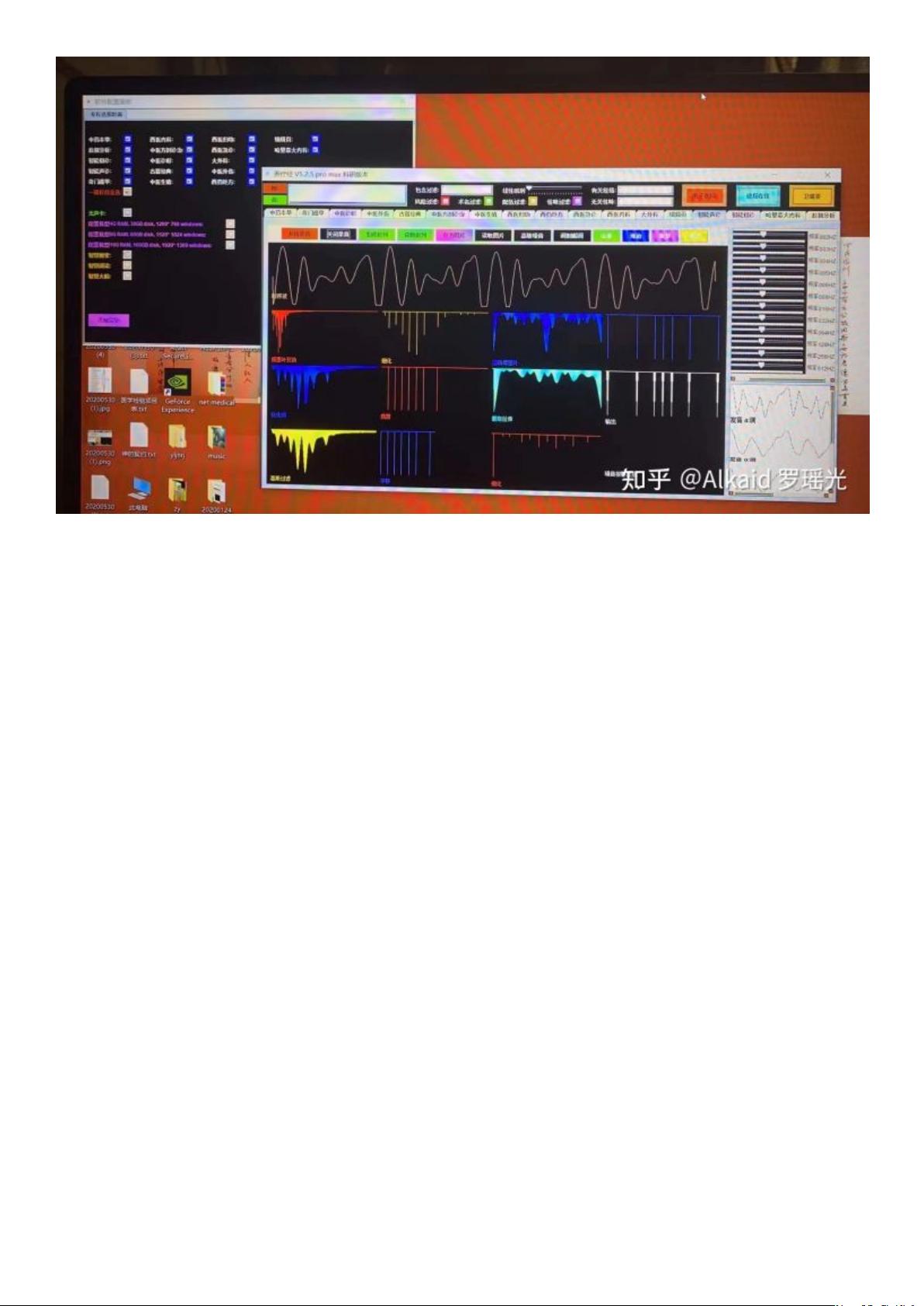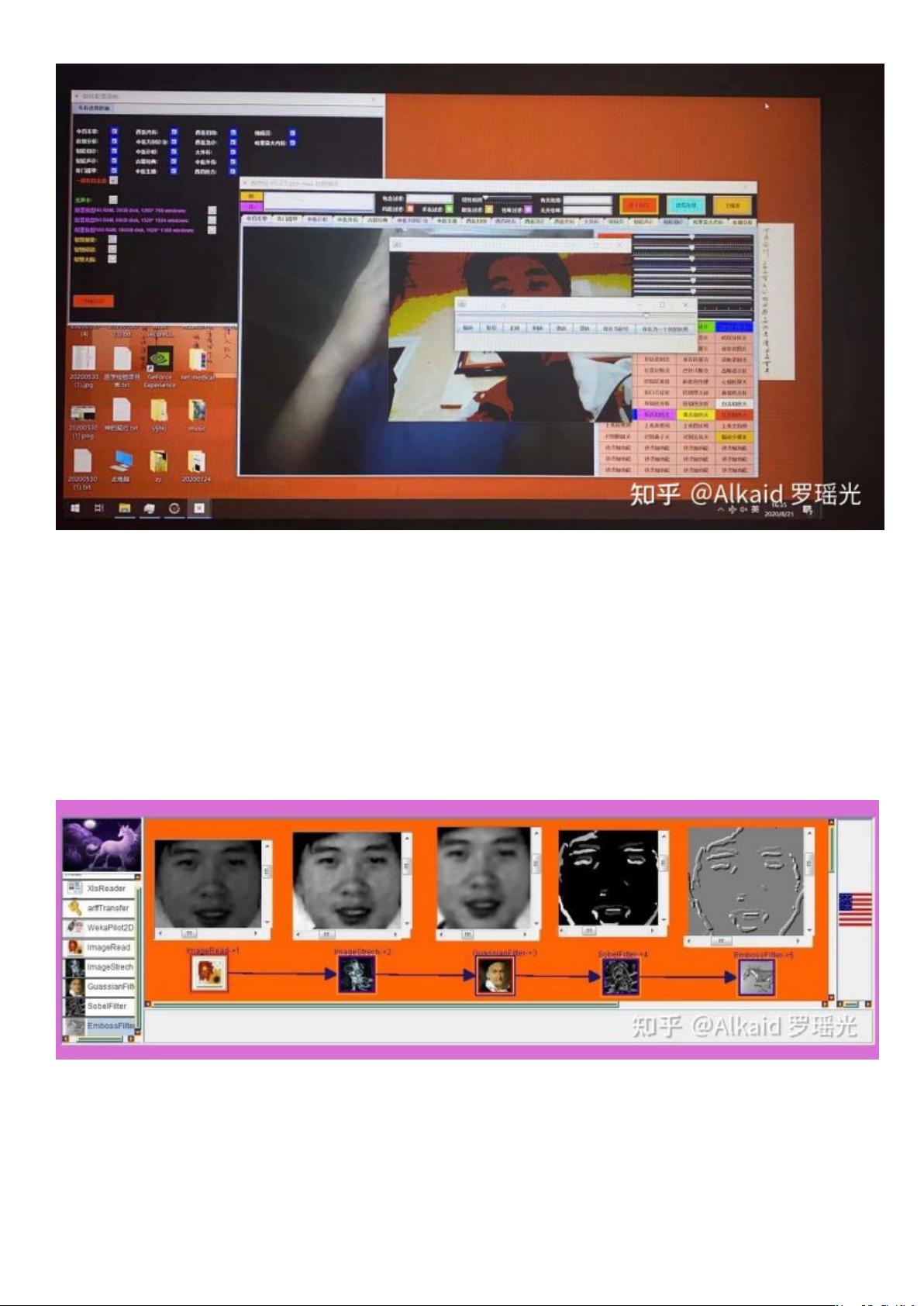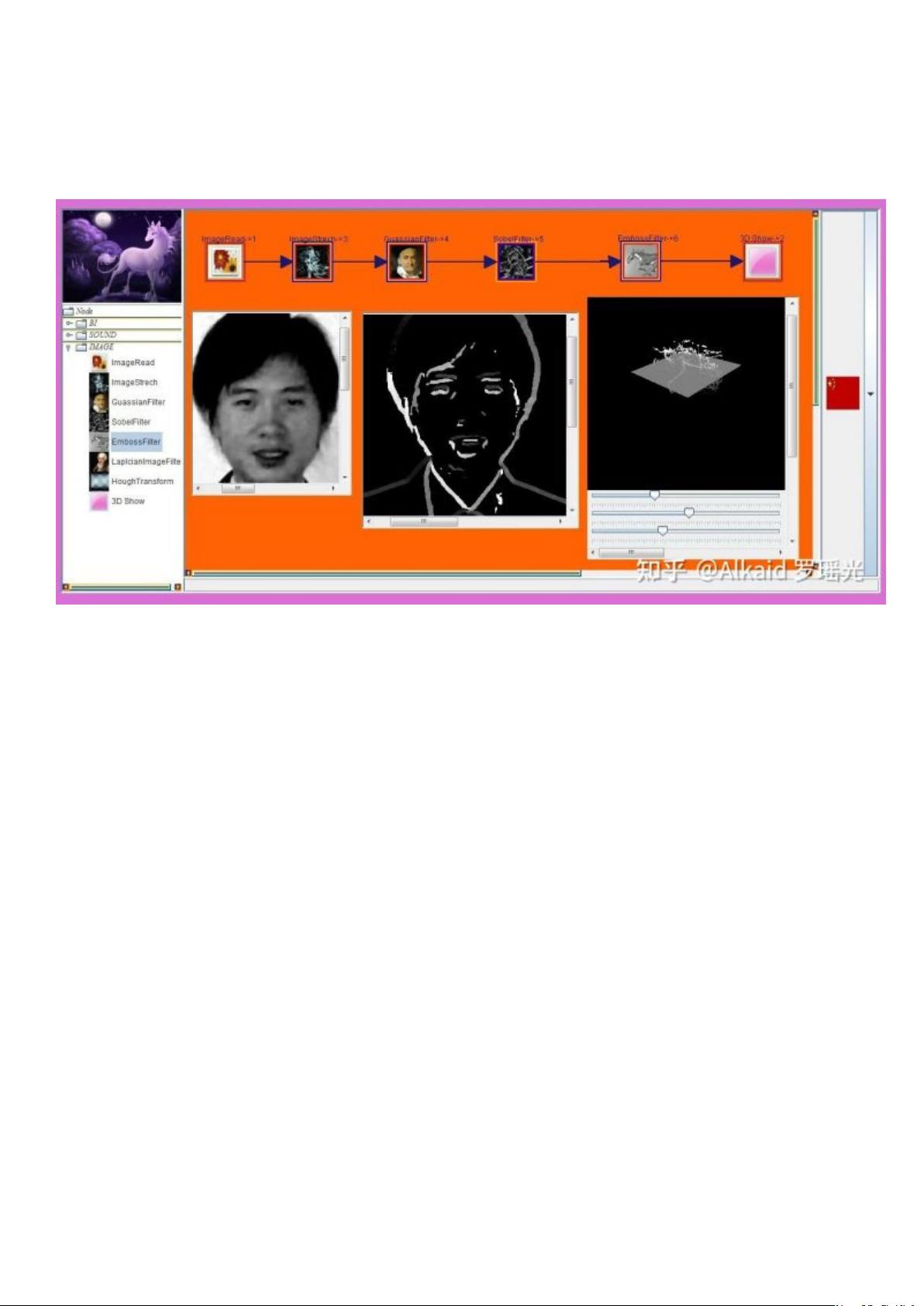
3 凹度计算 emboss 浮雕,索贝尔 mask,refer page 204,
4 频率计算 傅里叶时序域,傅里叶频率域,哈尔计算,refer page 258, 211,
5 腐蚀计算 膨胀计算,侵蚀计算,均值计算,高斯计算 1D 一字, 高斯 2D 十字。refer page 202, 204, 205, 206
排序,
1 德塔的排序作者早期 2009 年设计《算法导论》 黑皮书 ,北邮出版社有其 数据结构 影印教材 的 快速排序 4 代,
进行了 10 年优化,refer
page https://github.com/yaoguangluo/Data_Processor/blob/master/DP/sortProcessor/Quick_4D_Sort.java
2 优化过程归纳,逐渐的形成了一个微分催化排序体系。refer page 247,248,250, 658,下册 134,
3 左右比对算法优化,小高峰过滤优化,缺陷峰归纳,催化算子优化,离散逻辑优化。refer page 658,下册 134,
左右比对算法优化,一般指在不对称的数列中,为了寻找对称性观测面,作者设计了一种比较简单的方法,如将数
列逐渐拆分, 取出拆分后的小数列的初值和尾值进行比较,作为一个参照点,用于躲避计算高峰。测试发现具有强
大的实用性。
小高峰过滤优化,一般指为了躲避内存计算高峰而导致的延迟,卡顿,死锁,堆栈溢出等问题 而设计的一类高效率
算法集合。
缺陷峰归纳, 一般指计算数列在不断的拆分中的中值基偶问题导致了变量,算子,函数的使用频率不对称而出现
的一系列蝴蝶效应问题集的归纳。
催化算子优化,一般指 计算的中间过程中 因 变量,算子,函数的使用频率 不对称,不稳定导致的各种问题 ,为了
解决这类问题而 进行的不断 的对 变量,算子,函数优化与校正过程。
离散逻辑优化,一般指 对 变量,算子,函数优化与校正过程中 通过离散数学, 迪摩根定律,等客观存在的逻辑
定律进行 不断优化与校正过程。