SparkSQL Catalyst Optimizer深度解析
135 浏览量
更新于2024-08-27
收藏 196KB PDF 举报
"SparkSQLCatalyst源码分析之Optimizer"
SparkSQL的Catalyst模块是其高性能查询引擎的关键组成部分,而Optimizer则是Catalyst中的核心组件,负责将解析后的逻辑计划(LogicalPlan)转化为更高效、优化过的执行计划。这篇文章主要探讨了Optimizer的工作原理和实现方式。
在SparkSQL的处理流程中,Analyzer首先解析SQL语句并生成LogicalPlan,这是一个抽象的数据处理描述,表示了SQL语句的逻辑含义。Optimizer紧接着Analyzer工作,它的主要任务是对LogicalPlan进行一系列的优化操作,这些操作通常按照预定义的策略组织成多个优化批次(Batches)。每个批次包含一组规则(Rules),这些规则由Catalyst中的Rule对象表示,它们会对LogicalPlan进行迭代修改,直到满足某个停止条件,如达到固定次数的迭代或计划不再变化。
在Optimizer的batches列表中,我们可以看到三个主要的优化策略:
1. **CombineLimits**:这个批次的目的是合并多个LIMIT子句,减少不必要的数据处理步骤,提高效率。
2. **ConstantFolding**:常量折叠策略会识别并计算表达式中的常量,简化计划,比如将`SELECT 2 + 2 FROM table`优化为`SELECT 4 FROM table`。
3. **FilterPushdown**:过滤器下推策略尽可能地将过滤条件推到数据源的最底层,减少数据传输量和处理节点的数量。它包括CombineFilters、PushPredicateThroughProject和PushPredicateThroughJoin等规则,分别处理不同类型的过滤条件。
每个Batch里的规则通过`FixedPoint(100)`来设定,意味着每个批次的规则将被执行最多100次,直到没有更多的改变发生。这种迭代优化的方式确保了优化过程可以充分进行,但又避免了无限循环。
除了上述的优化策略,还有其他优化规则,如NullPropagation(空值传播)、BooleanSimplification(布尔表达式简化)、SimplifyFilters(简化过滤条件)、SimplifyCasts(简化类型转换)和SimplifyCaseConversionExpressions(简化CASE转换表达式)等,这些规则有助于消除冗余操作,提高计划的效率。
在实际应用中,理解这些优化策略和它们在源码中的实现对于调优和解决性能问题至关重要。通过对SparkSQL Catalyst Optimizer的深入分析,开发者能够更好地定制优化规则,或者针对特定场景优化查询执行性能。
总结来说,SparkSQL的Catalyst Optimizer是一个强大的工具,通过一系列精心设计的优化策略和规则,实现了对LogicalPlan的高效优化,确保SparkSQL在处理大规模数据时具备优秀的性能。对它的源码进行深入研究,不仅可以帮助我们理解SparkSQL的工作机制,还能为开发高性能的数据处理应用提供宝贵的指导。
SparkSQLCatalyst源码分析之源码分析之Optimizer
前几篇文章介绍了Spark SQL的Catalyst的核心运行流程、SqlParser,和Analyzer 以及核心类库TreeNode,本文将详细讲解Spark
SQL的Optimizer的优化思想以及Optimizer在Catalyst里的表现方式,并加上自己的实践,对Optimizer有一个直观的认识。
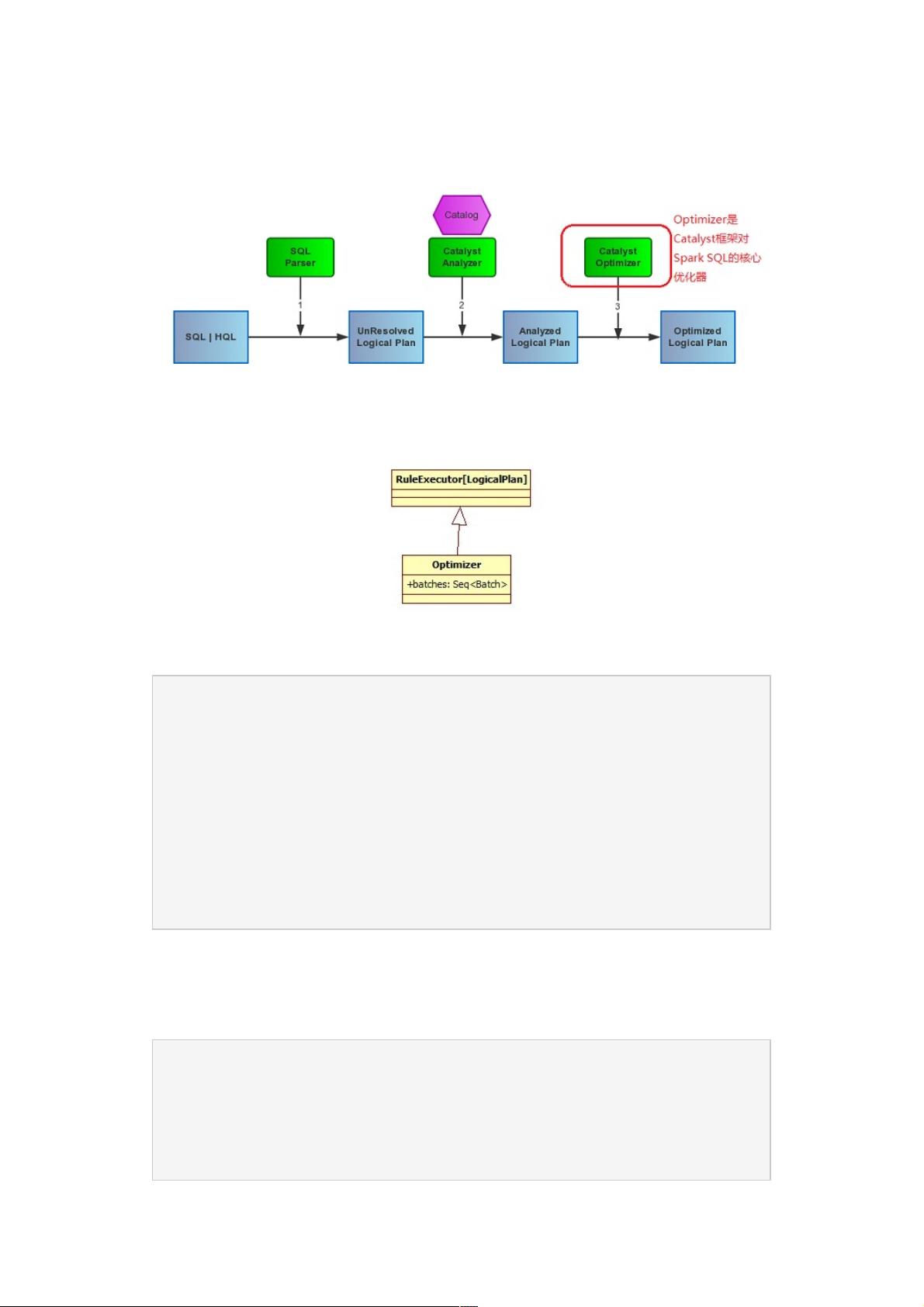
Optimizer的主要职责是将Analyzer给Resolved的Logical Plan根据不同的优化策略Batch,来对语法树进行优化,优化逻辑计划节点
(Logical Plan)以及表达式(Expression),也是转换成物理执行计划的前置。如下图:
一、Optimizer
Optimizer这个类是在catalyst里的optimizer包下的唯一一个类,Optimizer的工作方式其实类似Analyzer,因为它们都继承自
RuleExecutor[LogicalPlan],都是执行一系列的Batch操作:
Optimizer里的batches包含了3类优化策略:1、Combine Limits 合并Limits 2、ConstantFolding 常量合并 3、Filter Pushdown 过滤
器下推,每个Batch里定义的优化伴随对象都定义在Optimizer里了:
object Optimizer extends RuleExecutor[LogicalPlan] {
val batches =
Batch("Combine Limits", FixedPoint(100),
CombineLimits) ::
Batch("ConstantFolding", FixedPoint(100),
NullPropagation,
ConstantFolding,
BooleanSimplification,
SimplifyFilters,
SimplifyCasts,
SimplifyCaseConversionExpressions) ::
Batch("Filter Pushdown", FixedPoint(100),
CombineFilters,
PushPredicateThroughProject,
PushPredicateThroughJoin,
ColumnPruning) :: Nil
}
另外提一点,Optimizer里不但对Logical Plan进行了优化,而且对Logical Plan中的Expression也进行了优化,所以有必要了解一下
Expression相关类,主要是用到了references和outputSet,references主要是Logical Plan或Expression节点的所依赖的那些
Expressions,而outputSet是Logical Plan所有的Attribute的输出:
如:Aggregate是一个Logical Plan, 它的references就是group by的表达式 和 aggreagate的表达式的并集去重。
case class Aggregate(
groupingExpressions: Seq[Expression],
aggregateExpressions: Seq[NamedExpression],
child: LogicalPlan)
extends UnaryNode {
override def output = aggregateExpressions.map(_.toAttribute)
override def references =
(groupingExpressions ++ aggregateExpressions).flatMap(_.references).toSet
}
下载后可阅读完整内容,剩余7页未读,立即下载
2018-11-05 上传
2021-03-03 上传
2021-01-30 上传
点击了解资源详情
点击了解资源详情
2016-12-15 上传
2024-11-27 上传
2024-11-27 上传

weixin_38677227
- 粉丝: 4
- 资源: 929
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
