Catalyst:Spark与Shark优化框架详解——规则驱动的查询优化
需积分: 9 164 浏览量
更新于2024-07-23
收藏 459KB PDF 举报
Catalyst是Apache Spark和Shark查询优化框架的重要组成部分,由Databricks高级软件工程师Michael Armbrust在2013年的Spark Summit上详细阐述。查询优化是一个核心概念,它在SQL这种声明性语言中起着关键作用,允许用户指定他们想要检索的数据,而不是指定具体的执行方式。数据库系统通过优化过程选择最合适的执行策略。
在传统的查询规划中,如"Naïve Query Planning"示例所示,查询会被分解成一系列步骤,包括投影(Project)、过滤(Filter)和表扫描(TableScan)。这种方法虽然直观,但在编写指令代码来优化这类模式时通常非常复杂,因为每一步都需要精确的控制。
Catalyst采用了一种更为高效的方法,即构建一个基于规则的优化框架。这个框架以关系运算符的优化树结构为基础,通过编写简单规则来逐步改变查询计划,每条规则仅针对查询中的一个小部分进行优化。例如,一个规则可能提出将某个过滤操作转换为利用索引查找(Index Lookup),从而提高性能。这种方法的优势在于减少了对开发者学习特定定制语言的需求,而且语言的灵活性允许更广泛地优化策略。
Volcano/Cascades模型是早期的一种查询优化技术,它涉及创建一个用于表达规则的语言,并通过编译器生成可执行代码。然而,这种方法存在局限性,如开发人员需要学习新的语言,且语言可能不够强大,难以处理复杂的优化场景。
Catalyst框架作为改进,解决了这些问题,它简化了规则的编写和应用,使得查询优化变得更加直观和易于维护。通过将优化过程分解为一系列可组合的规则,Catalyst能够更高效地处理大规模数据处理任务,提升Apache Spark在云计算环境下的性能。Catalyst是Apache Spark查询优化的关键组件,它极大地推动了分布式计算平台在大数据处理领域的效率和灵活性。
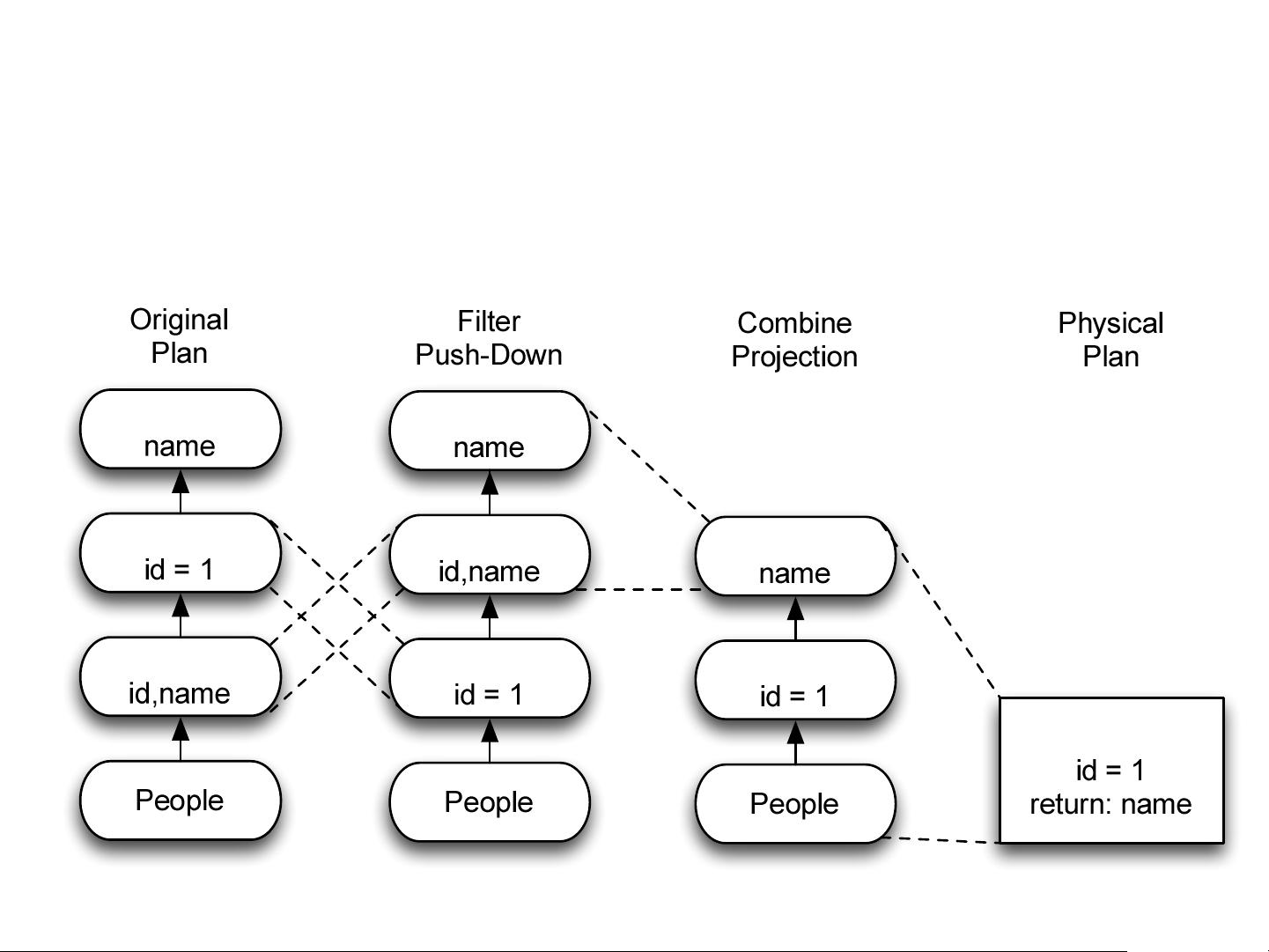
Optimizing with Rules
Project
Project
Filte r
Pro ject
Pro ject
Filte r
Pro ject
Filte r
IndexLookup
剩余22页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-07-12 上传
2022-07-12 上传
2016-04-08 上传
2021-10-27 上传
2017-12-11 上传
点击了解资源详情

腾讯开发者
- 粉丝: 1482
- 资源: 52
 我的内容管理
展开
我的内容管理
展开







最新资源
- builder-docs:builder.swillkb.com的文档源文件
- 用于使用PostgREST编写REST API后端的入门工具包和工具-Node.js开发
- 绿色精品漂亮旅游项目互联网公司模板5691.zip
- EverythingSDK
- 股票热点板块竞价筛选-统计分析
- Calculadora-javascript
- kandycreateuser
- 七色幻彩大气的幻灯片html5网站模板6147.zip
- 安卓Android源码——安卓Android 图片缓存、加载器.zip
- 【本人姓名】实验1欢迎程序.zip
- VB图像的剪切、复制和粘贴
- instantclient-basic-windows.x64-11.2.0.4.0.zip
- Simon_game-WebApp:西蒙是一个有趣的记忆技巧游戏。 科技栈
- ammo-core:弹药核心安卓服务
- CIE_color_plot:一个用于将RGB颜色绘制到CIE颜色空间上的小应用程序
- CSSD - 不连续信号的三次平滑样条附matlab代码.zip
