Cassandra:分布式Key-Value存储详解
"Cassandra最新文档提供了全面的关于Cassandra分布式数据库系统的介绍,涵盖了其核心概念、数据模型、操作机制以及性能和配置等关键信息。"
Cassandra是一种非关系型数据库,它作为键值存储系统,由多个数据库节点组成一个分布式网络服务。这种设计使得Cassandra具备了高度的可扩展性和容错性。写入Cassandra的数据会被复制到集群中的其他节点,而读操作则会路由到适当的节点进行,确保高可用性和数据一致性。
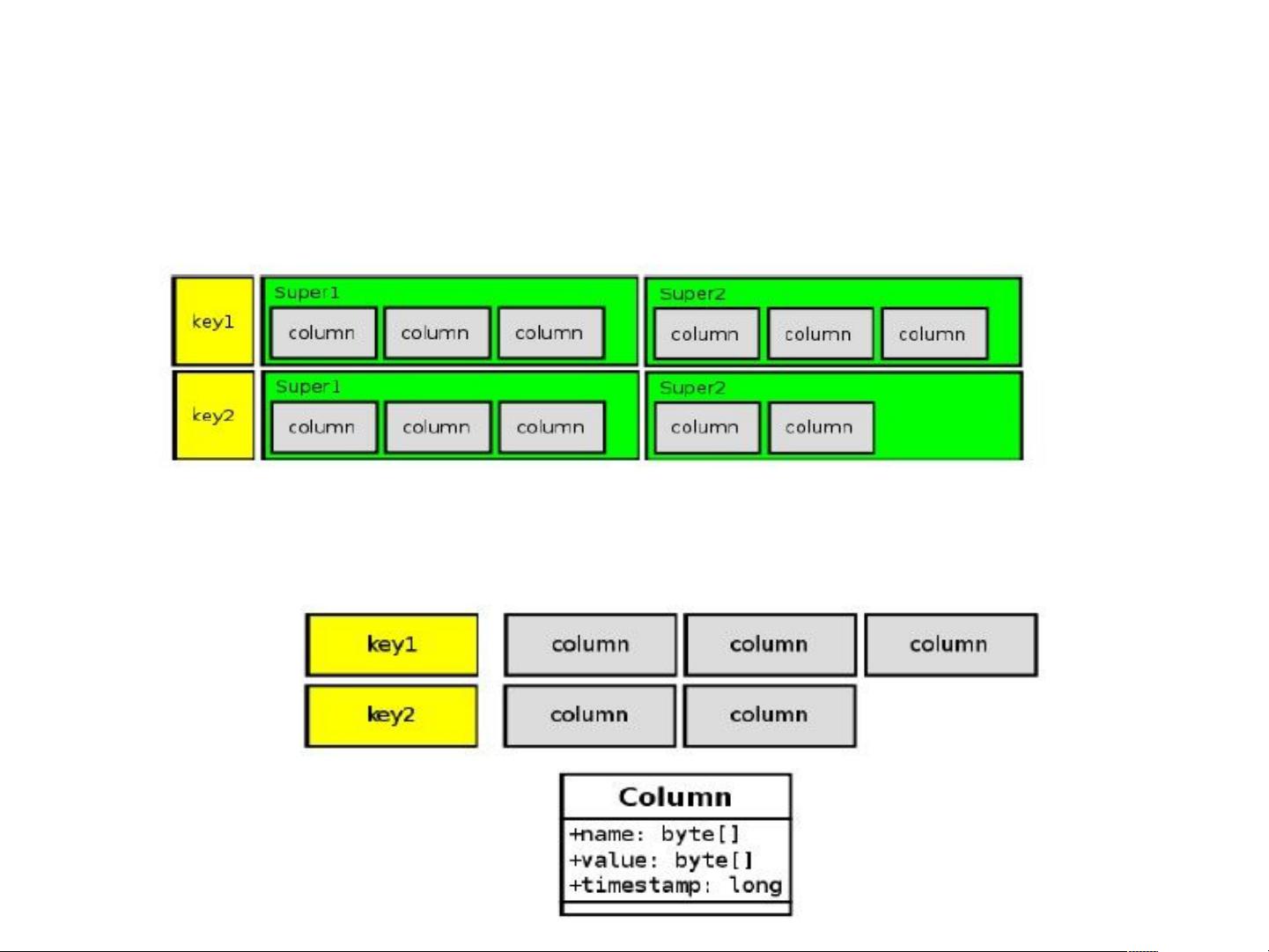
在数据模型方面,Cassandra采用了灵活的模式设计。它可以视为四维或五维的哈希结构,由Cluster、Keyspace、ColumnFamily和Column(或SuperColumn)组成。Cluster是整个系统的基础,包含多个Keyspace。每个Keyspace对应一个应用程序,可以包含多个ColumnFamily。ColumnFamily是数据的主要组织单位,类似于传统数据库中的表,它又由Column或SuperColumn构成。
Column是最小的数据单元,由name、value和timestamp三个部分组成。name和value都是字节数组,长度无限制,timestamp用于解决可能出现的数据冲突。客户端负责提供所有的值,包括timestamp,以确保数据同步。
SuperColumn是Column的集合,可以看作是Column的数组,具有一个单独的name,并包含一系列的Column。例如,一个SuperColumn可能表示"Address",其value部分包含多个Column,如"street"、"city"等,每个Column有自己的name、value和timestamp。
Cassandra的写操作和读操作具有特定的机制。写操作通过复制到多个节点实现容错,而读操作根据数据分布和一致性要求路由到适当的节点。API允许开发者与Cassandra进行交互,进行数据的增删改查。
性能测试和比较部分可能涉及与其他数据库系统的基准测试,以展示Cassandra在处理大量数据、高并发和分布式环境下的性能优势。配置说明则会详细阐述如何设置和优化Cassandra集群的各项参数,以适应不同的工作负载和环境需求。
Cassandra的最新文档是了解和掌握这一分布式数据库系统的重要资料,对于开发者和运维人员来说,它提供了深入理解Cassandra特性和使用方法的详细指南。

是一个包含了许多 的结构,类似数据库的 4# 。
每一个 都包含有 以及和该 关联的一系列 。
UserProfile // ColumnFamily
{
user1: { // key
username: “x",
email: “x@gmail.com",
phone: “134666666"
}, // 第一个 row 结束
user2: { // key
username: “zi",
email: " zi @live.com",
phone: “1399888888"
age: “24”
}, // 第二个 row 结束
}
•
ColumnFamily 的类型: Standard ( column )或 Super ( Super colu
mn )。
剩余48页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2013-07-01 上传
2014-10-12 上传
2020-08-31 上传
2015-09-02 上传
2022-08-08 上传
2021-04-10 上传

zhqi_3094
- 粉丝: 1
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多约束下多车场车辆路径问题的蚁群算法研究
- 新东方英语词根词缀记忆大全
- AspectJ in Action 2003电子书
- 使用C#获取CPU及硬盘序列号
- 嵌入式Linux应用程序开发详解-第1章
- 移动数据通信的书Wireless and Mobile Data Networks.
- UML项目指导3-用例
- Matlab7官方学习手册
- 哈尔滨工业大学贾世楼的信息论的研究生课程讲义
- AT89S51实验及实践教程
- Dreamweaver MX 入门
- 信息论的研究生课程讲义
- 3G.Evolution.HSPA.and.LTE.for.Mobile.Broadband
- 学C都要来看看(应用版)
- 程序设计经典问题.doc
- 中文版AutoCAD_2007实用教程
