Linux环境下编译Hadoop2.4教程及常见问题
下载需积分: 9 | PDF格式 | 644KB |
更新于2024-09-12
| 64 浏览量 | 举报
"这篇教程详细介绍了在Linux环境下,特别是Ubuntu系统中,如何从零开始编译Hadoop 2.4及其相关知识汇总。"
在Linux环境下编译Hadoop 2.4涉及到多个步骤,首先需要获取Hadoop的源码。有两种方式获取:
1. 通过SVN:你可以使用Subversion (SVN) 工具来克隆Hadoop的源代码仓库。为了使用SVN,你需要先在你的Linux系统中安装SVN。教程推荐了TortoiseSVN作为图形化的SVN客户端,但同时也提供了命令行方式的下载链接。
2. 下载压缩包:直接从Apache Hadoop的官方网站下载Hadoop 2.4的源码压缩包。对于初学者,该教程还提供了如何在官网上找到并下载所需版本的指导。
下载源码后,你需要对其进行解压。例如,使用`tar -zxvf hadoop-2.4.0-src.tar.gz`命令可以解压Hadoop 2.4的源码包。
接下来,为了编译Hadoop,你需要确保系统上安装了一些必要的软件:
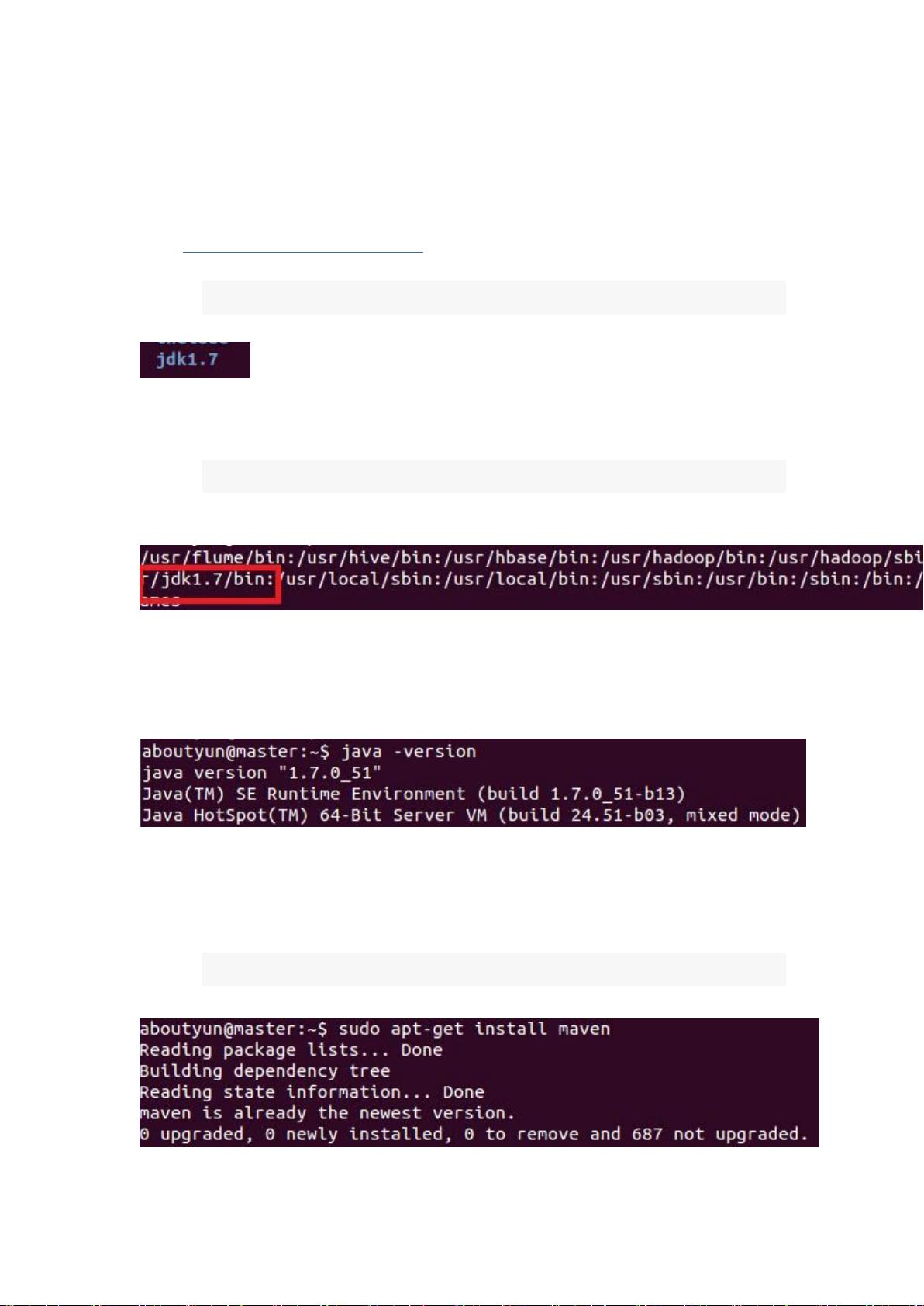
1. JDK:Hadoop的编译需要Java Development Kit (JDK)。教程中给出了下载JDK 7的链接,并提供了解压和配置环境变量的步骤。确保将环境变量`JAVA_HOME`指向JDK的实际安装路径,例如`/usr/jdk1.7`,并将`PATH`变量添加`JAVA_HOME/bin`目录,以便系统能找到Java可执行文件。
2. Maven:Apache Maven是用于构建Hadoop项目的依赖管理和构建工具。在Ubuntu上,可以通过`sudo apt-get install maven`命令安装。尽管教程提到可能需要配置Maven的环境变量,但在作者的系统中,这一步似乎是不必要的。
完成以上准备工作后,你可以开始编译Hadoop 2.4:
1. 进入Hadoop源码目录。
2. 使用Maven进行编译,通常使用`mvn clean install`命令,这会下载所有依赖并构建项目。
在编译过程中可能会遇到的问题,教程也进行了汇总,包括检查已安装软件的版本是否兼容,以及如何解决不兼容或缺失的软件包。如果你在编译过程中遇到任何问题,可以参照这个汇总来寻求解决方案。
这个教程提供了一个详尽的指南,适合那些想要从源码编译Hadoop的初学者,涵盖了从获取源码到配置环境再到实际编译的全过程。在进行编译前,确保你的Linux环境满足所有先决条件,并按照步骤操作,可以避免很多常见的问题。
剩余13页未读,继续阅读
相关推荐







丞小良
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Ruby语言集成Mandrill API的gem开发
- 开源嵌入式qt软键盘SYSZUXpinyin可移植源代码
- Kinect2.0实现高清面部特征精确对齐技术
- React与GitHub Jobs API整合的就业搜索应用
- MATLAB傅里叶变换函数应用实例分析
- 探索鼠标悬停特效的实现与应用
- 工行捷德U盾64位驱动程序安装指南
- Apache与Tomcat整合集群配置教程
- 成为JavaScript英雄:掌握be-the-hero-master技巧
- 深入实践Java编程珠玑:第13章源代码解析
- Proficy Maintenance Gateway软件:实时维护策略助力业务变革
- HTML5图片上传与编辑控件的实现
- RTDS环境下电网STATCOM模型的应用与分析
- 掌握Matlab下偏微分方程的有限元方法解析
- Aop原理与示例程序解读
- projete大语言项目登陆页面设计与实现
