MeMOTR:长时记忆增强Transformer提升多目标跟踪性能
需积分: 0 66 浏览量
更新于2024-08-03
收藏 4.04MB PDF 举报
MeMOTR是一个专为多目标跟踪(Multi-Object Tracking,MOT)设计的深度学习模型,特别是在视频处理任务中,它解决了现有方法的一个关键问题,即缺乏对长期时间信息的有效建模。传统的MOT方法往往依赖于相邻帧之间的目标特征,忽略了跨帧的连续性和一致性,这限制了它们在捕捉目标随时间变化的行为和关联性方面的表现。
MeMOTR的核心创新在于引入了一种长期记忆增强的Transformer架构。Transformer最初在自然语言处理中大放异彩,但在多目标跟踪领域,它被改造为一个定制的记忆-注意力层,这一层允许模型在追踪过程中存储和检索长期的时空信息。这种记忆机制增强了同一目标的跟踪嵌入的稳定性和区分度,从而显著提高了目标关联的能力。换句话说,MeMOTR能够更好地识别和跟踪动态场景中目标的持续变化,即使在时间跨度较大的情况下也能保持一致性。
实验结果在DanceTrack数据集上展示了MeMOTR的强大性能。与最先进的方法相比,MeMOTR在HOTA(全帧平均精度和召回率)指标上提升了7.9%,在AssA(短期跟踪精度)上更是达到了13.0%的改进。这表明MeMOTR在处理复杂和动态的多目标场景时,不仅在精确度上表现出色,而且在长期跟踪的稳定性上也超越了同类技术。
除了在特定数据集上的优秀表现,MeMOTR在MOT17数据集上的关联性能也优于其他基于Transformer的解决方案,显示出其在多目标跟踪领域的广泛适用性。此外,它还展示了良好的泛化能力,在BDD100K这样的大规模现实世界视频数据集上依然能保持高效稳定的追踪性能。
MeMOTR作为一种结合了Transformer架构和长期记忆机制的多目标跟踪方法,为解决视频任务中的跟踪难题提供了一个新颖且有效的解决方案。它的成功不仅体现在性能提升上,还在于它如何通过长期记忆增强来提升模型的动态对象识别和关联能力,这对于实时、复杂的多目标跟踪应用具有重要意义。
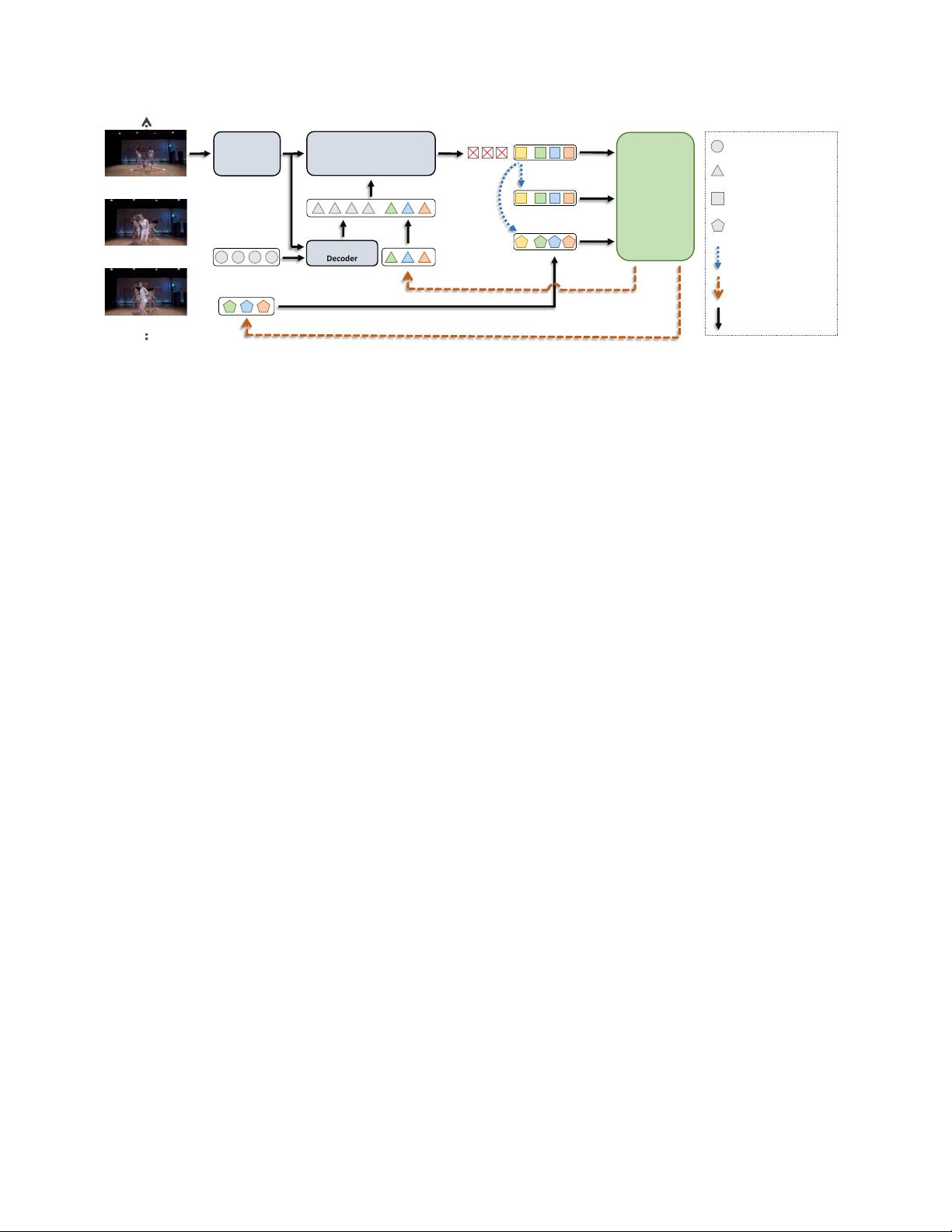
𝑰
𝒕
𝑰
𝒕"𝟏
𝑰
𝒕"𝟐
Input Video Stream
Backbone
&
Encoder
Transformer Joint
Decoder
Detection
Decoder
𝑸
𝒅𝒆𝒕
𝑬
𝒅𝒆𝒕
𝒕
𝑬
𝒕𝒄𝒌
𝒕
𝑴
𝒕𝒄𝒌
𝒕
𝑶
𝒕𝒄𝒌
𝒕
𝑶
𝒕𝒄𝒌
𝒕&𝟏
Temp ora l
Interaction
Module
copy for newborn targets
update for subsequent
normal input
𝑴
𝒕𝒄𝒌
𝒕
learnable detect query
track and detect embedding
long-term memory
output embedding
Figure 1. Overview of MeMOTR. Like most DETR-based [6] methods, we exploit a ResNet-50 [15] backbone and a Transformer [32]
Encoder to learn a 2D representation of an input image. We use different colors to indicate different tracked targets, and the learnable
detect query Q
det
is illustrated in gray. Then the Detection Decoder D
det
processes the detect query to generate the detect embedding
E
t
det
, which aligns with the track embedding E
t
tck
from previous frames. Long-term memory is denoted as M
t
tck
. The initialization process
in the blue dotted arrow will be applied to newborn objects. Our Long-Term Memory and Temporal Interaction Module is discussed in
Section 3.3 and 3.4. More details are illustrated in Figure 2.
ing the encoded image feature with [E
t
det
, E
t
tck
], the Trans-
former Joint Decoder D
joint
produces the corresponding
output [
ˆ
O
t
det
,
ˆ
O
t
tck
]. For simplicity, we merge the newborn
objects in
ˆ
O
t
det
(yellow box) with tracked objects’ output
ˆ
O
t
tck
, denoted by O
t
tck
. Afterward, we predict the classifi-
cation confidence c
t
i
and bounding box b
t
i
corresponding to
the i
th
target from the output embeddings. Finally, we feed
the output from adjacent frames [O
t
tck
, O
t−1
tck
] and the long-
term memory M
t
tck
into the Temporal Interaction Module,
updating the subsequent track embedding E
t+1
tck
and long-
term memory M
t+1
tck
. The details of our components will be
elaborated in the following sections.
3.2. Detection Decoder
In the previous Transformer-based methods [22, 43],
the learnable detect query and the previous track query
are jointly input to Transformer Decoder from scratch.
This simple idea extends the end-to-end detection Trans-
former [6] to multi-object tracking. Nonetheless, we argue
that this design may cause misalignment between detect and
track queries. As discussed in numerous works [6, 20], the
learnable object query in DETR-family plays a role similar
to a learnable anchor with little semantic information. On
the other hand, track queries have specific semantic knowl-
edge to resolve their category and bounding boxes since
they are generated from the output of previous frames.
Therefore, as illustrated in Figure 1, we split the origi-
nal Transformer Decoder into two parts. The first decoder
layer is used for detection, and the remaining five layers are
used for joint detection and tracking. These two decoders
have the same structure but different inputs. The Detection
Decoder D
det
takes the original learnable detect query Q
det
as input and generates the corresponding detect embedding
E
t
det
, carrying enough semantic information to locate and
classify the target roughly. After that, we concatenate the
detect and track embedding together and feed them into the
Joint Decoder D
joint
.
3.3. Long-Term Memory
Unlike previous methods [17, 43] that only exploit ad-
jacent frames’ information, we explicitly introduce a long-
term memory M
t
tck
to maintain longer temporal information
for tracked targets. When a newborn object is detected, we
initialize its long-term memory with the current output.
It should be noted that in a video stream, objects only
have minor deformation and movement in consecutive
frames. Thus, we suppose the semantic feature of a tracked
object changes only slightly in a short time. In the same
way, our long-term memory should also update smoothly
over time. Inspired by [29], we apply a simple but effec-
tive running average with exponentially decaying weights
to update long-term memory M
t
tck
:
f
M
t+1
tck
= (1 − λ)M
t
tck
+ λ · O
t
tck
, (1)
where
f
M
t+1
tck
is the new long-term memory for the next
frame. The memory update rate λ is experimentally set to
0.01, following the assumption that the memory changes
smoothly and consistently in consecutive frames. We also
tried some other values in Table 7.
3.4. Temporal Interaction Module
Adaptive Aggregation for Temporal Enhancement. Is-
sues such as blurring or occlusion are often seen in a video
stream. An intuitive idea to solve this problem is using
剩余11页未读,继续阅读
373 浏览量
2024-06-08 上传
323 浏览量
2025-01-04 上传
206 浏览量
177 浏览量
180 浏览量
127 浏览量
112 浏览量

学术菜鸟小晨
- 粉丝: 2w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 初学者入门必备!Visual C++开发的连连看小程序
- C#实现SqlServer分页存储过程示例分析
- 西门子工业网络通信例程解读与实践
- JavaScript实现表格变色与选中效果指南
- MVP与Retrofit2.0相结合的登录示例教程
- MFC实现透明泡泡效果与文件操作教程
- 探索Delphi ERP框架的核心功能与应用案例
- 爱尔兰COVID-19案例数据分析与可视化
- 提升效率的三维石头制作插件
- 人脸C++识别系统实现:源码与测试包
- MishMash Hackathon:Python编程马拉松盛事
- JavaScript Switch语句练习指南:简洁注释详解
- C语言实现的通讯录管理系统设计教程
- ASP.net实现用户登录注册功能模块详解
- 吉时利2000数据读取与分析教程
- 钻石画软件:从设计到生产的高效解决方案
