理解统计基础与混合效应模型:从一般线性到广义线性混合模型
需积分: 5 36 浏览量
更新于2024-06-19
收藏 5.37MB PDF 举报
"该资源是关于统计基础与混合效应模型的讲解,主要涵盖了从一般线性模型到广义线性混合效应模型的概念及其应用。由兰州大学生态学院的张鹏提供,强调了统计方法应服务于科学问题,并对数据前提要求的重要性。通过实例展示了统计在处理数据变异中的作用,旨在分析变异的来源。"
详细知识点:
1. **一般线性模型 (GLM)**: 这是最基础的统计模型之一,包括线性回归、方差分析和T检验等,适用于连续型数据,假设因变量与自变量之间的关系是线性的。
2. **广义线性模型 (GLMM)**: 广义线性模型扩展了GLM,允许因变量服从非正态分布,如泊松回归(处理计数数据)、二项回归(处理二分类数据)和负二项回归(处理过度dispersion的计数数据),还包括beta回归和Gamma回归等。
3. **线性混合效应模型 (LMMs)**: 在LMMs中,不仅包含固定效应(所有观察均受影响的效应),还包含随机效应(影响部分观察的效应),常用于处理嵌套或相关数据,例如时间序列数据或分层数据。
4. **广义线性混合效应模型 (GLMMs)**: 结合了GLM和LMMs,允许因变量具有非正态分布且存在随机效应。这种模型可以处理复杂数据结构中的异方差性和相关性。
5. **随机效应模型**: 随机效应模型考虑了数据中可能存在的一些不可观测的个体差异,如随机斜率或随机截距,能够更准确地估计参数。
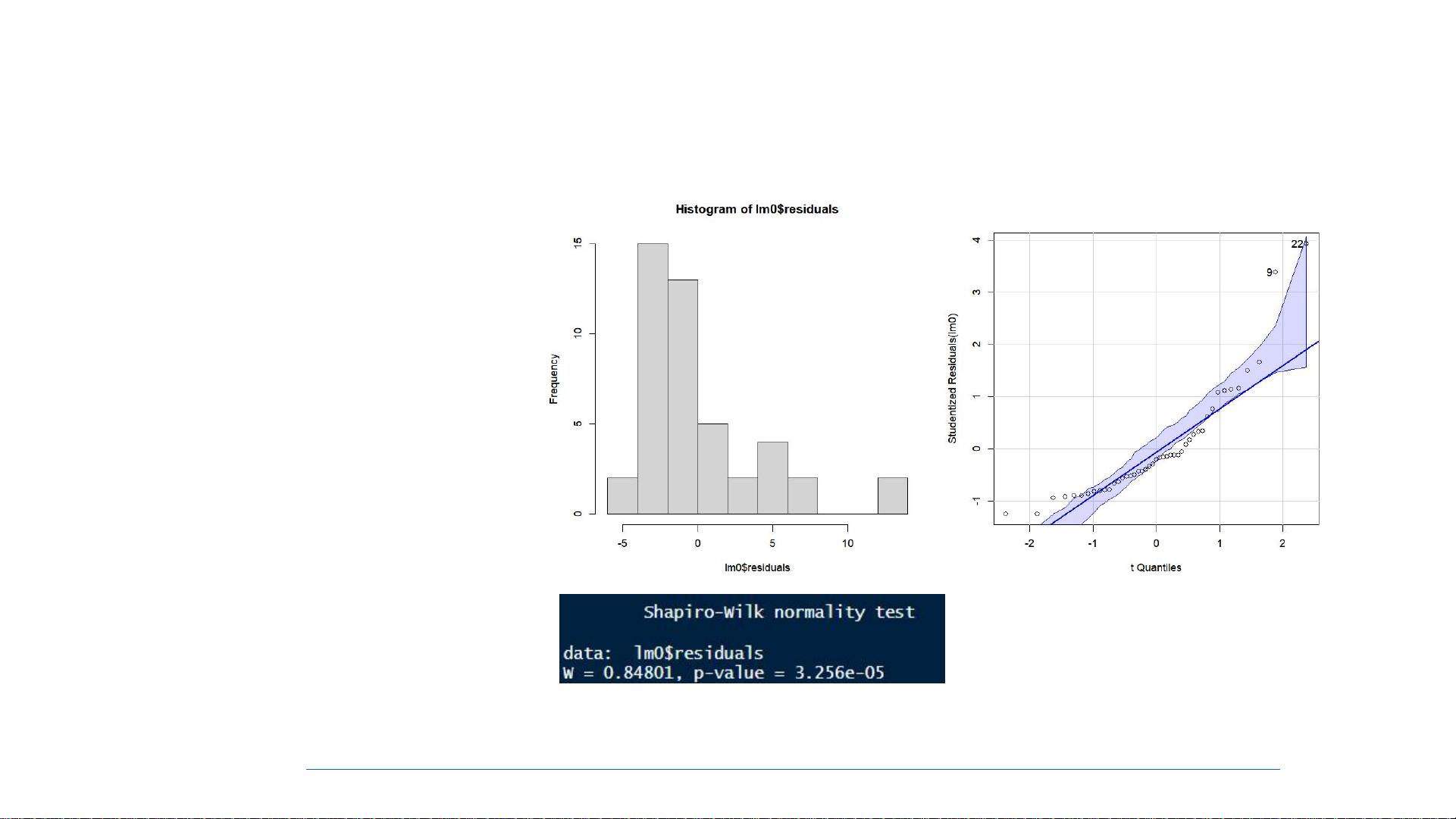
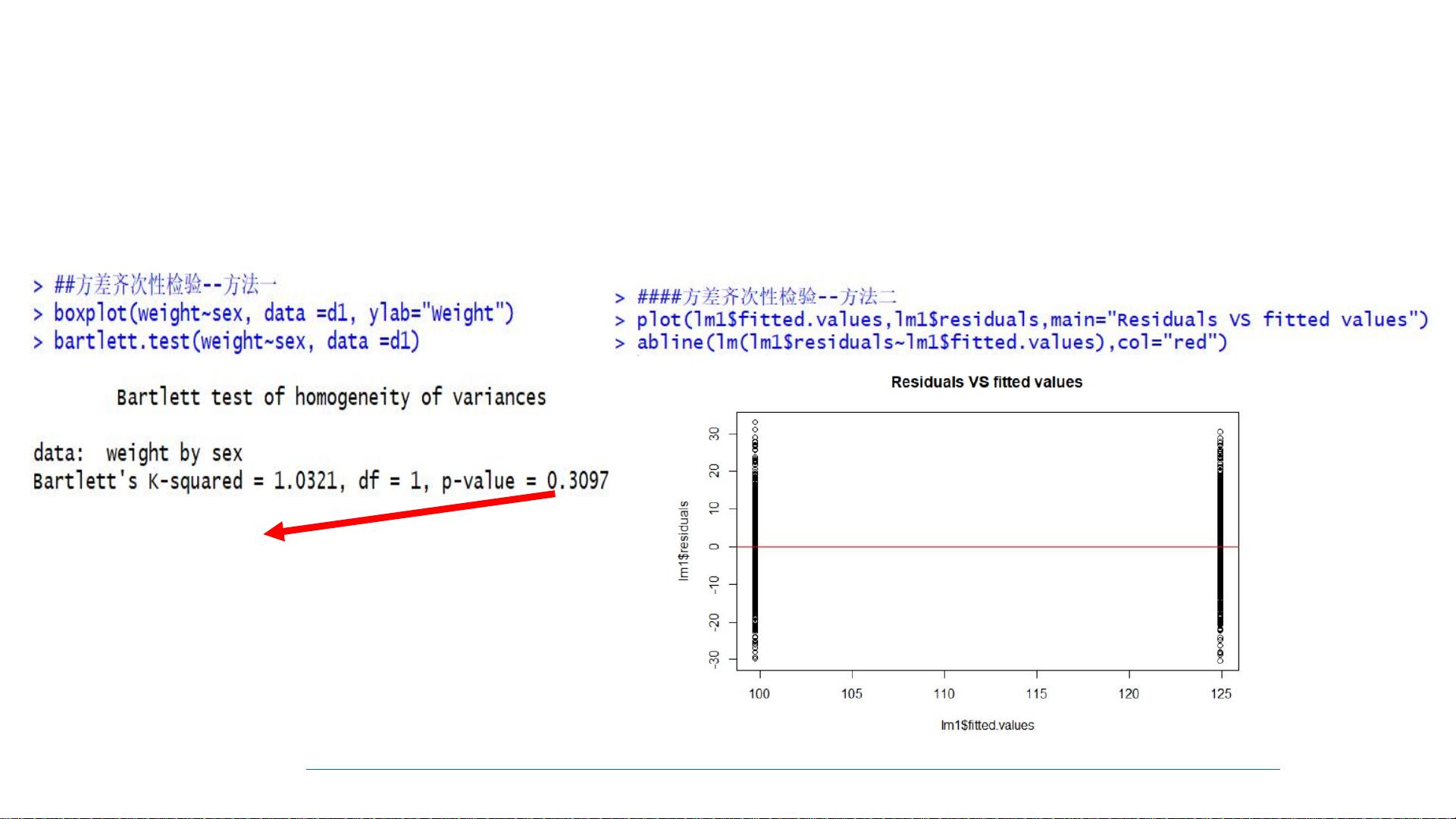
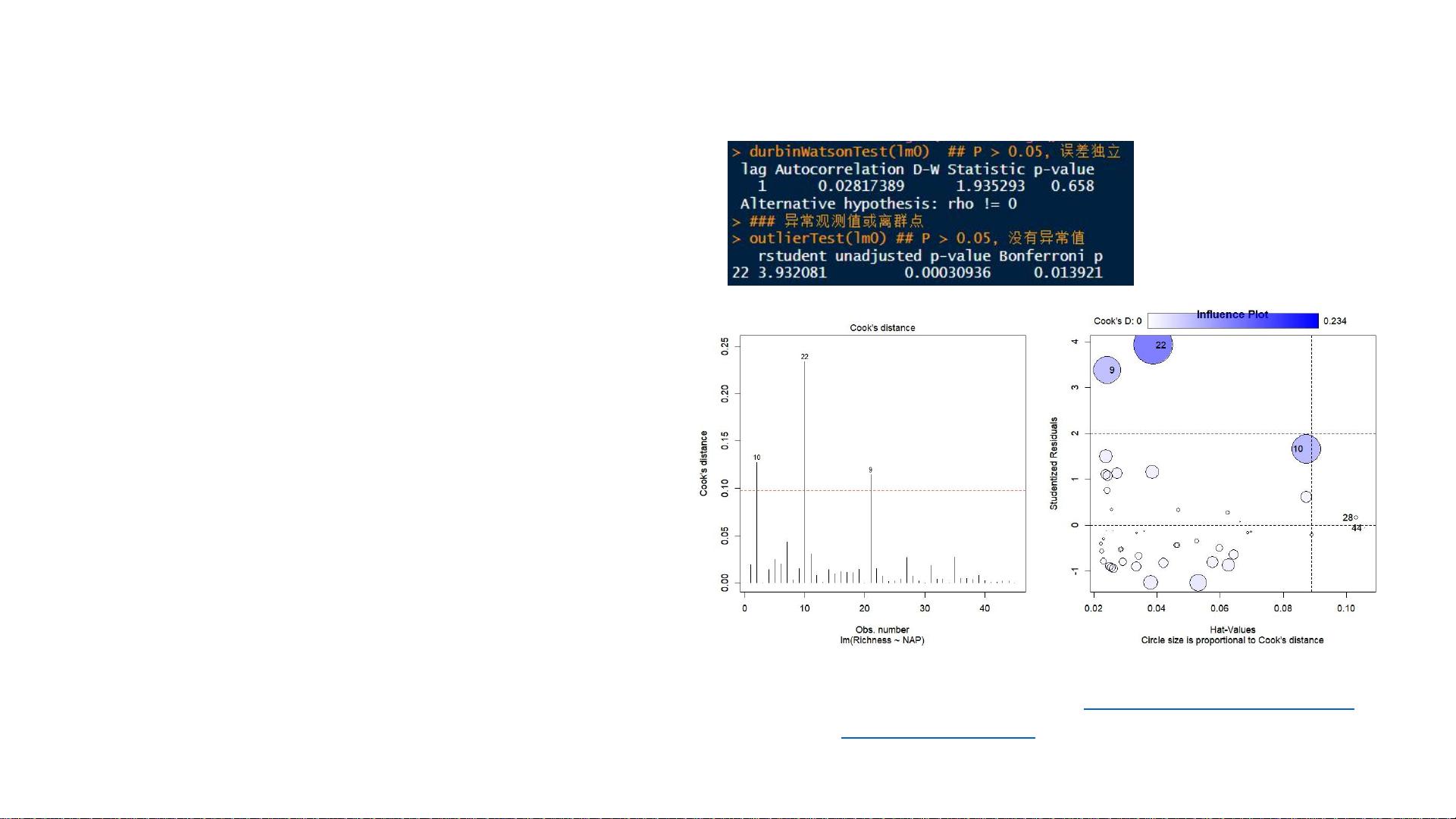
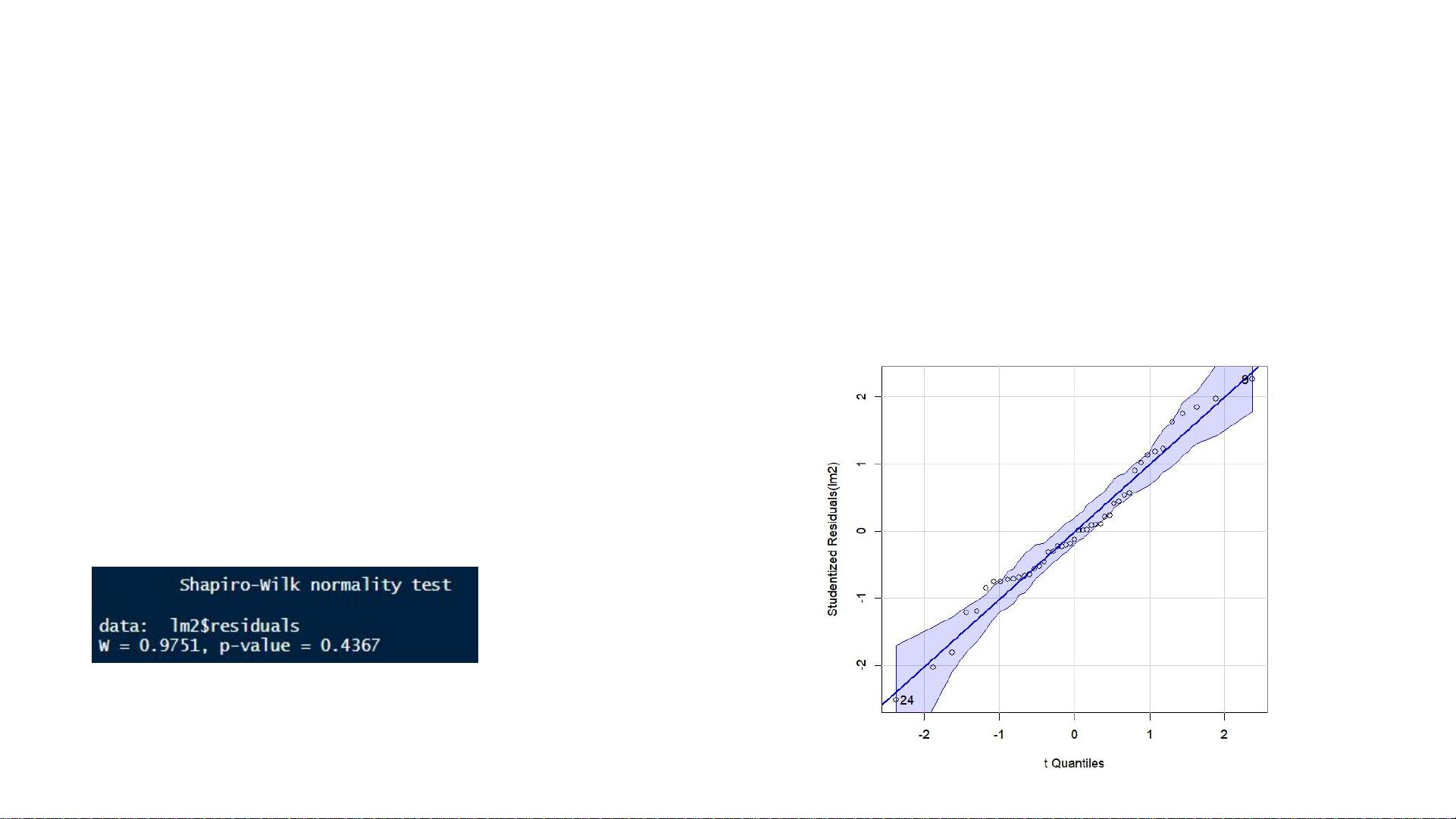
6. **统计方法的前提条件**: 所有的统计模型都基于特定的数据分布假设和独立性假设。在应用统计模型之前,必须确保数据满足这些前提,否则可能导致错误的推断。
7. **统计的目的**: 统计分析的核心目标是理解数据的变异来源,通过模型来解释和预测现象。在存在变异的数据中,统计方法帮助我们从不确定性中提取信息。
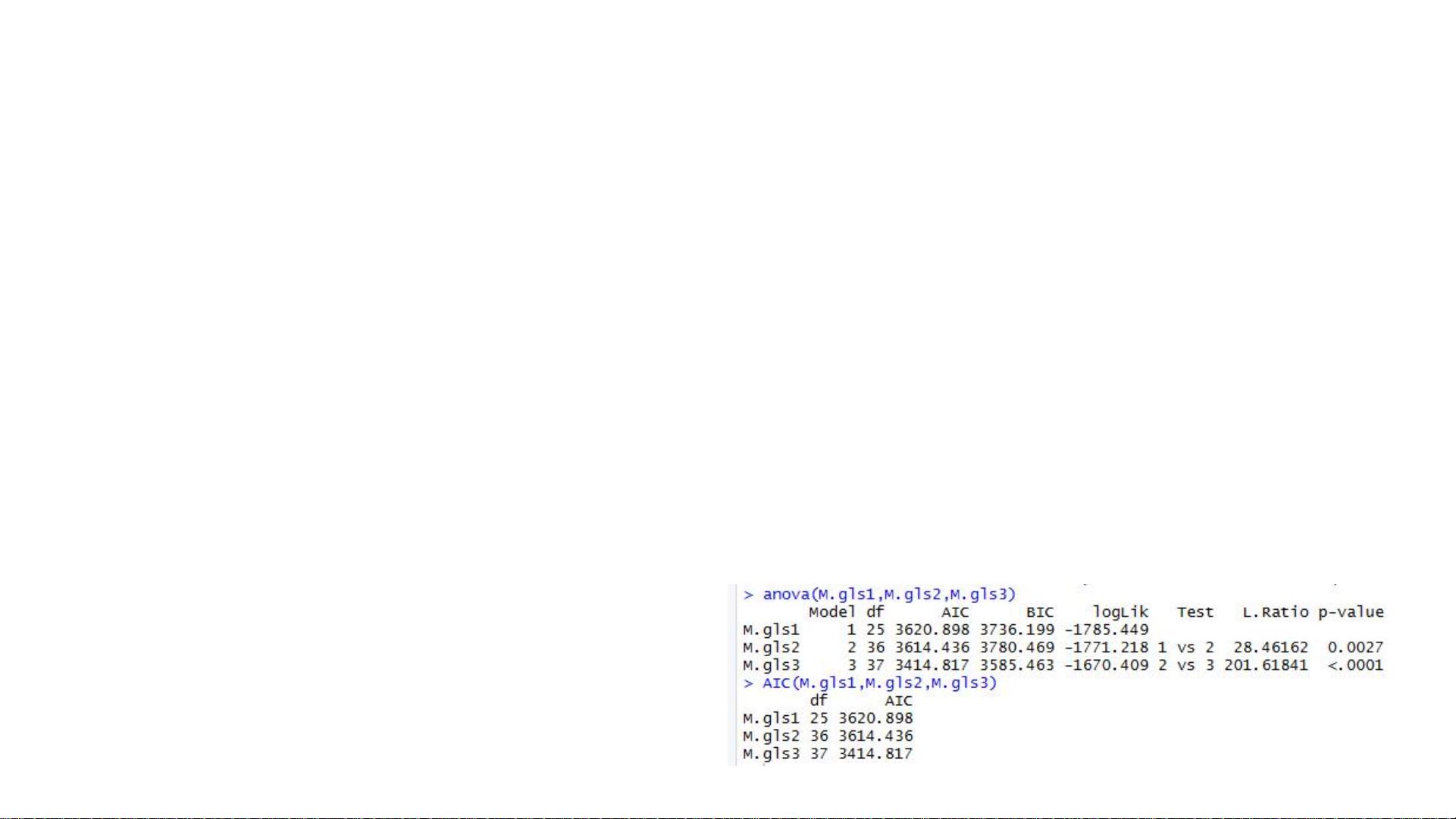
8. **模型选择原则**: 统计模型的选择应以问题为导向,模型越简单越好,只要它能充分捕捉数据的结构。然而,当数据结构复杂时,更复杂的模型可能更适合揭示隐藏的模式。
9. **实例展示**: 提供的实例展示了处理不同治疗组与对照组的数据,通过统计分析可以揭示各组间的差异,以及这些差异是否显著,从而评估不同处理的效果。
10. **理解变异**: 统计分析的关键是解析观测数据的变异,找出其内在的规律和潜在因素,帮助科学家做出决策和推论。
统计基础与混合效应模型是研究复杂数据结构和解决实际问题的重要工具,涉及多种统计方法,包括从基本的一般线性模型到更复杂的混合模型,强调了模型选择和数据质量的重要性。
点击了解资源详情
点击了解资源详情
点击了解资源详情
2015-08-25 上传
2020-09-10 上传
2019-10-10 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

编码农夫
- 粉丝: 6221
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
