TDWSparkSQL开发与优化实战
需积分: 9 160 浏览量
更新于2024-07-16
收藏 9.13MB PDF 举报
"SparkSQL开发与优化实践.pdf"
在SparkSQL开发与优化实践中,我们主要探讨了以下几个关键知识点:
1. **TDWSparkSQL简介**:TDWSparkSQL是由TDBank开发的一个基于社区SparkSQL的改进版本,它设计用于处理大规模数据计算。此系统旨在提高数据处理效率,同时保持对TDWHive语法和数据格式的兼容性。其核心特性包括:
- **分区格式兼容性**:TDWSparkSQL能够处理与TDWHive相匹配的分区格式,这使得用户可以在不改变现有工作流程的情况下切换到SparkSQL。
- **Driver离散化**:这一特性增强了系统的可扩展性和并发能力,使得多个任务可以并行运行,从而提升整体性能。
- **自动分区功能**:自动分区功能简化了数据处理过程,减少了用户的操作复杂性,提高了数据处理的效率。
- **Python UDF/UDAF支持**:支持Python用户自定义函数(UDF)和用户自定义聚合函数(UDAF),扩展了SparkSQL的功能,使其能够处理更广泛的业务需求。
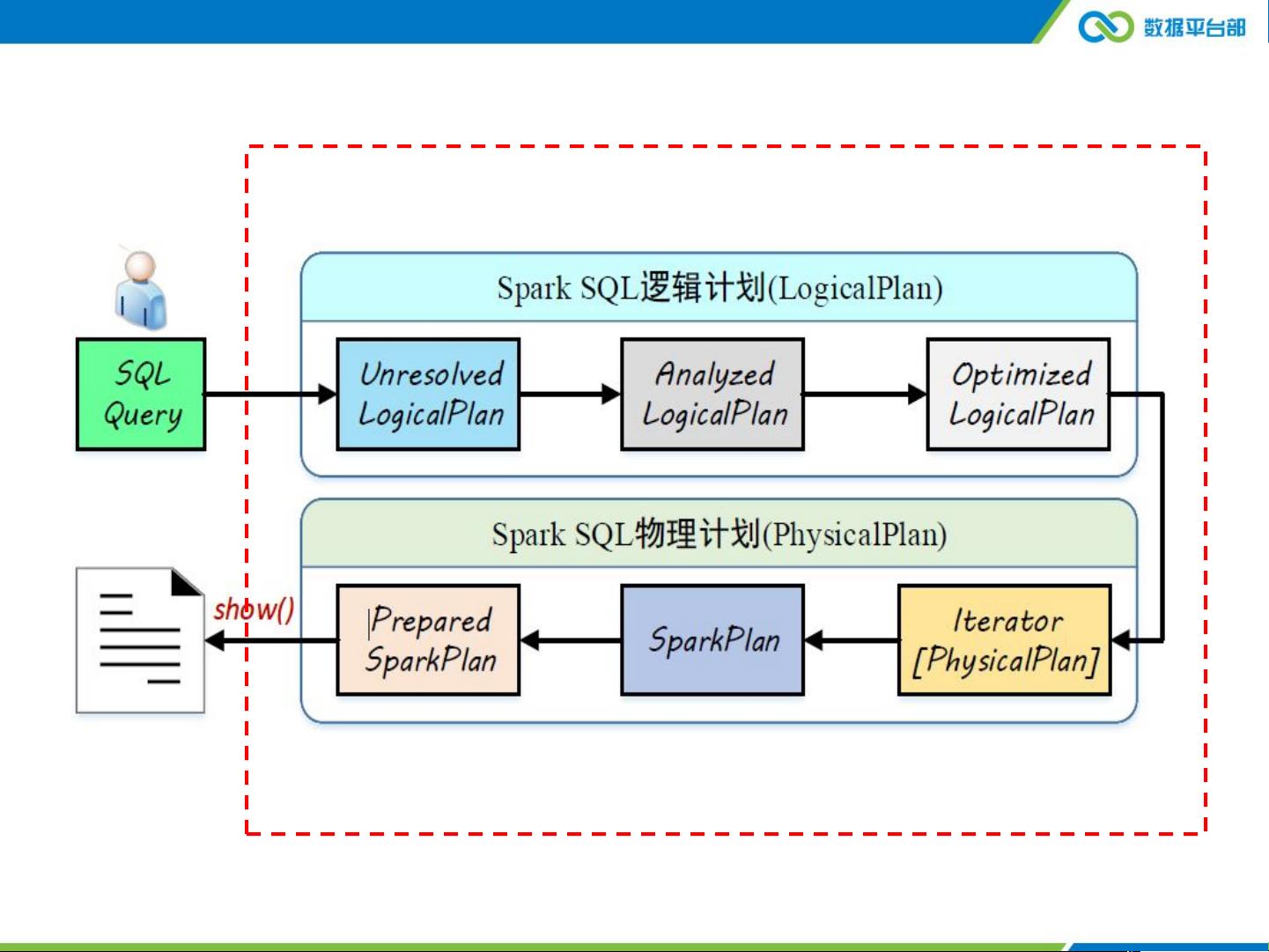
2. **TDWSparkSQL内部机制**:通过对内部机制的深入理解,我们可以更好地进行性能优化。例如,通过减少HDFS的读取和写入次数,SparkSQL相比Hive能显著提高处理速度。在示例中,我们看到Stage1、Stage2和Stage3的执行流程,这些阶段对应于数据扫描、映射、归约等操作,展示了SparkSQL如何并行处理数据。
3. **TDWSparkSQL实践与调优**:实际应用中,TDWSparkSQL的调优是一个重要的环节。这涉及到对SQL查询的优化,例如,避免全表扫描,合理使用分区键,以及优化数据加载和计算过程。此外,系统架构如YARN、HDFS和MetaStore的配置也对性能有很大影响。
4. **TDW大数据平台架构**:整个TDW大数据平台是一个复杂的生态系统,包括TDBank、Gaia、Hive、Angel、Ceph、HDFS、HBase等组件,涵盖了数据接入、存储、计算、调度、即时查询和机器学习等多个方面。SparkSQL在其中起到了关键作用,连接了多种数据源,并提供了高效的数据处理能力。
5. **SQL执行流程**:在TDWSQL-Engine架构中,插入和选择操作默认通过SparkSQL执行,如果失败,则回退到Hive。其他如DML(数据操纵语言)、DDL(数据定义语言)和ACL(访问控制列表)操作则通常由Hive处理。这种设计保证了灵活性和稳定性。
6. **系统交互**:用户可以通过Lhotse进行任务调度,IDE/IDEX用于即时查询,Tesla则服务于机器学习任务。SparkSQL与GraphX、MLib、MR、Caffe和Tensorflow等组件协同工作,提供了全面的数据处理和分析解决方案。
SparkSQL在TDW大数据平台中的应用不仅提高了数据处理速度,还提供了与Hive的无缝集成,使得开发人员能够利用其强大的并行计算能力进行复杂的数据分析和优化。通过深入理解SparkSQL的内部机制和实践调优,我们可以进一步提升系统的效能,满足大数据时代的需求。



2021-08-24 上传
2021-07-17 上传
2021-04-05 上传
2018-08-14 上传
2017-10-30 上传
2024-11-27 上传
2024-11-27 上传
2024-11-27 上传
2024-11-27 上传
2024-11-27 上传

kaneeasy
- 粉丝: 0
- 资源: 30
 我的内容管理
展开
我的内容管理
展开







最新资源
- Wrox.Professional.Ajax.2nd.Edition.Mar.2007
- java连接数据库驱动的代码.txt
- The C++ Standard Library
- java 如何打包成jar和exe.txt
- Arcgis Desktop 9.2 使用手册
- 互换性与测量技术基础复习与练习
- Effective STL
- 多变量时间序列异常样本的识别
- 英语学习的相关资料哦
- C语言面试题之华为篇.doc
- struts2 讲义
- PCB高级设计系列讲座
- c++编程思想(卷2)
- c++编程思想(卷1)
- AVR_单片机与GCC_编程
- 达内面试125题全,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
