数据挖掘概念与技术第二版课后答案详解
需积分: 12 195 浏览量
更新于2024-07-24
收藏 800KB PDF 举报
"数据挖掘概念与技术(第二版)答案"
本书是《数据挖掘:概念与技术》第二版的课后习题解答,由Jiawei Han和Micheline Kamber编写,他们来自伊利诺伊大学厄巴纳-香槟分校。这本书是数据挖掘领域的经典教材,涵盖了从数据预处理到应用趋势的广泛主题。
1. 数据挖掘概述
数据挖掘是一种从大量数据中发现有价值知识的过程。它包括模式识别、关联规则学习和分类等方法。数据挖掘不仅仅涉及简单的数据分析,还包括高级统计分析、机器学习和人工智能等复杂技术。书中第一章的习题旨在帮助读者理解数据挖掘的基本概念及其在不同领域中的应用。
2. 数据预处理
数据预处理是数据挖掘的重要步骤,包括数据清洗(去除噪声和不一致性)、数据集成(合并来自多个源的数据)、数据转换(如规范化和归一化)以及数据规约(减少数据量但保持其信息含量)。这一章的习题可能涉及到如何处理缺失值、异常值以及如何进行特征选择。
3. 数据仓库和OLAP技术
数据仓库是为企业决策提供单一视图的大型数据存储系统,而在线分析处理(OLAP)则支持多维度数据分析。第三章讨论了数据仓库的构建、OLAP操作(如切片、 dice、钻取和旋转)及其在商业智能中的应用。
4. 数据立方体计算与数据泛化
数据立方体是数据仓库中的一个概念,用于快速汇总多维数据。数据泛化是数据匿名化的一种方式,用于保护敏感信息。第四章的习题可能涉及如何构造数据立方体、优化OLAP查询以及如何实施有效的数据泛化策略。
5. 模式挖掘、关联规则和相关性
第五章讲解了频繁模式挖掘、关联规则学习(如Apriori算法)和序列模式挖掘。这些技术常用于市场篮子分析和预测用户行为。
6. 分类与预测
分类是根据已知属性将数据划分为预定义类别的过程,预测则是基于历史数据对未知结果的估计。第六章涵盖了决策树、贝叶斯分类、神经网络和支持向量机等方法,并提供了相关习题来深化理解。
7. 聚类分析
聚类是无监督学习的一种形式,通过寻找相似性的对象来划分数据集。第七章介绍了一种发现自然群体的方法,如K-means、层次聚类和DBSCAN等,并提供了练习来实践这些算法。
8. 流数据、时间序列和序列数据挖掘
随着实时数据的增加,第八章探讨了如何在数据流、时间序列和序列数据上进行挖掘,如滑动窗口技术和演变聚类。
9. 图挖掘与社会网络分析
第九章讨论了图数据结构的挖掘,包括社区检测、社交网络中的影响力传播以及多关系数据挖掘。
10. 对象、空间、多媒体、文本和Web数据挖掘
第十章涵盖了非结构化数据的挖掘,如地理位置信息、图像、音频、文本和网页数据,强调了特定于这些数据类型的挖掘技术。
11. 数据挖掘的应用与趋势
最后一章总结了数据挖掘在各个领域的应用,如医疗、金融、电子商务等,并探讨了未来的发展方向,如深度学习和大数据分析。
每章末尾的习题设计旨在巩固所学概念,提高读者解决实际问题的能力,是理解和掌握数据挖掘技术的关键实践部分。通过解答这些习题,读者可以深化对数据挖掘理论和方法的理解,并为实际项目做好准备。

14 CHAPTER 2. DATA PREPROCESSING
2.3. Give three additional commonly used statistical measures (i.e., not illustrated in this chapter) for the
characterization of data dispersion, and discuss how they can be computed efficiently in large databases.
Answer:
Data dispersion, also known as variance analysis, is the degree to which numeric data tend to spread and can
be characterized by such statistical measures as mean deviation, measures of skewness, and the coefficient
of variation.
The mean deviation is defined as the arithmetic mean of the absolute deviations from the means and is
calculated as:
mean deviation =
P
N
i=1
|x − ¯x|
N
, (2.1)
where ¯x is the arithmetic mean of the values and N is the total number of values. This value will be greater
for distributions with a larger spread.
A common measure of skewness is:
¯x − mode
s
, (2.2)
which indicates how far (in standard deviations, s) the mean (¯x) is from the mode and whether it is greater
or less than the mode.
The coefficient of variation is the standard deviation expressed as a percentage of the arithmetic mean
and is calculated as:
coefficient of variation =
s
¯x
× 100 (2.3)
The variability in groups of observations with widely differing means can be compared using this measure.
Note that all of the input values used to calculate these three statistical measures are algebraic measures.
Thus, the value for the entire database can be efficiently calculated by partitioning the database, computing
the values for each of the separate partitions, and then merging theses values into an algebraic equation
that can be used to calculate the value for the entire database.
The measures of dispersion described here were obtained from: Statistical Methods in Research and Pro duc-
tion, fourth ed., edited by Owen L. Davies and Peter L. Goldsmith, Hafner Publishing Company, NY:NY,
1972.
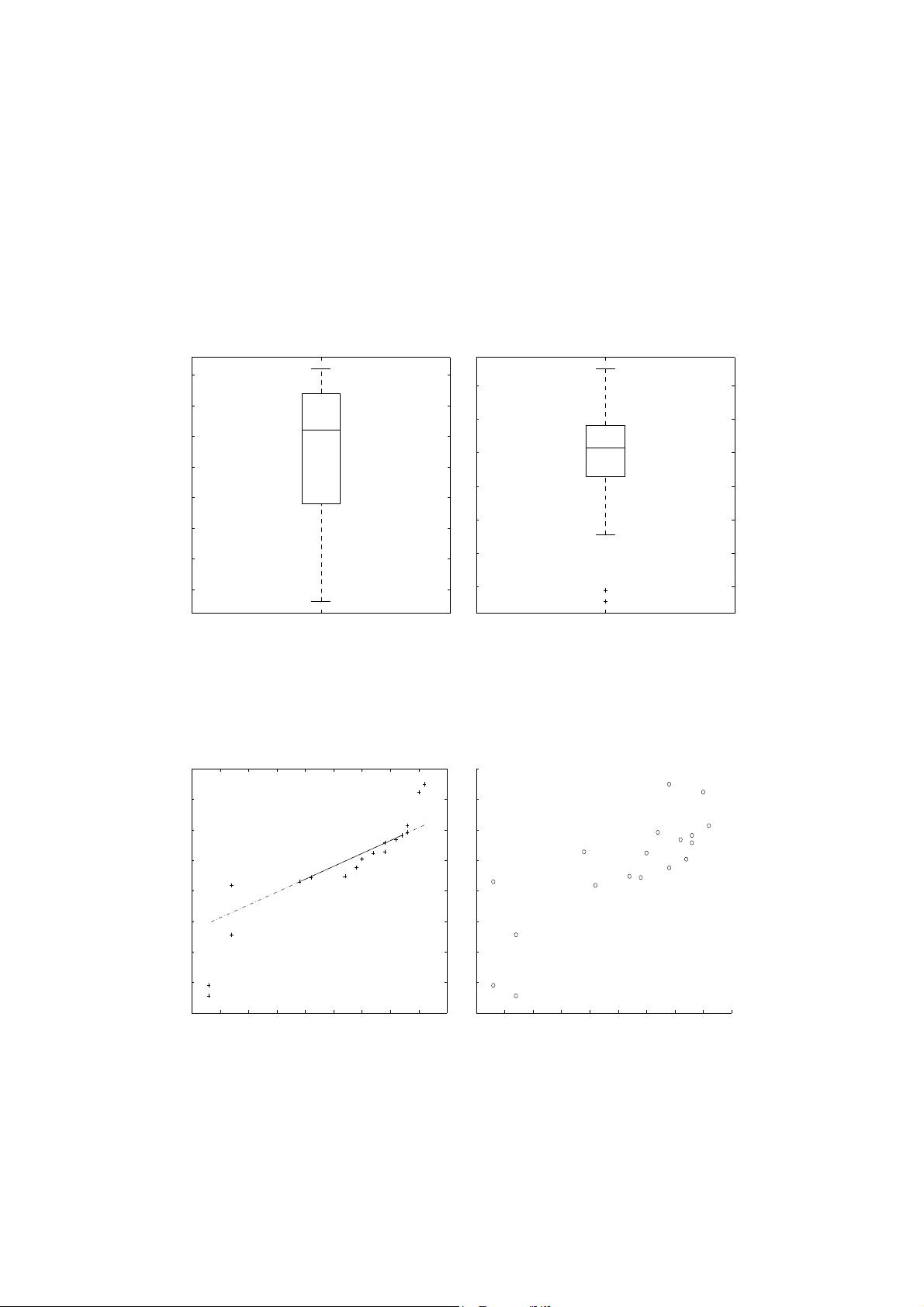
2.4. Suppose that the data for analysis includes the attribute age. The age values for the data tuples are (in
increasing order) 13, 15, 16, 16, 19, 20, 20, 21, 22, 22, 25, 25, 25, 25, 30, 33, 33, 35, 35, 35, 35, 36, 40, 45,
46, 52, 70.
(a) What is the mean of the data? What is the median?
(b) What is the mode of the data? Comment on the data’s modality (i.e., bimodal, trimodal, etc.).
(c) What is the midrange of the data?
(d) Can you find (roughly) the first quartile (Q1) and the third quartile (Q3) of the data?
(e) Give the five-number summary of the data.
(f) Show a boxplot of the data.
(g) How is a quantile-quantile plot different from a quantile plot?



剩余134页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
575 浏览量
289 浏览量
2010-03-19 上传
285 浏览量
186 浏览量

rkasdfg
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Saber仿真下的简化Buck环路分析与TDsa扫频
- Spring框架下使用FreeMarker发邮件实例解析
- Cocos2d捕鱼达人路线编辑器开发指南
- 深入解析CSS Flex布局与特性的应用
- 小学生加减法题库自动生成软件介绍
- JS颜色选择器示例:跨浏览器兼容性
- ios-fingerprinter:自动化匹配iOS配置文件与.p12证书
- 掌握移动Web前端高效开发技术要点
- 解决VS中OpenGL程序缺失GL/glut.h文件问题
- 快速掌握POI技术,轻松编辑Excel文件
- 实用ASCII码转换工具:轻松实现数制转换与查询
- Oracle ODBC补丁解决数据源配置问题
- C#集成连接器的开发与应用
- 电子书制作教程:你的文档整理助手
- OpenStack计费监控:使用collectd插件收集统计信息
- 深入理解SQL Server 2008 Reporting Services
