Hive查询流程详解:从SQL到MapReduce执行
需积分: 0 81 浏览量
更新于2024-08-04
收藏 652KB DOCX 举报
Hive查询详解
Hive是一种基于Hadoop的数据仓库工具,它提供了一个SQL-like的查询接口,用于在分布式存储系统中进行数据处理。本文主要介绍了Hive查询的基本流程和原理。
1. **实验目的**
- 理解Hive的SQL基础语法:学习Hive如何使用标准SQL语法进行数据操作。
- 掌握Hive查询方式:了解不同类型的查询如何转化为MapReduce作业,以充分利用Hadoop集群的计算能力。
2. **查询过程**
- **用户提交与编译器介入**:用户通过Hive的Driver提交SQL查询,编译器(Compiler)接收任务后,首先获取用户查询的计划(Plan)。
- **元数据获取**:编译器从MetaStore中检索所需的数据结构和表结构信息,这是执行查询的前提。
- **计划生成**:编译器将SQL语句解析为抽象语法树(AST),然后转换为查询块(QB),并通过逻辑计划(GenLogicalPlan)生成有向无环图(DAG)。
- **逻辑优化**:逻辑优化器对生成的DAG进行优化,如谓词下推、分区剪裁和关联排序等,提高查询效率。
- **物理计划**:优化后的DAG被转换为MapReduce任务,这是Hive将SQL查询实际执行到Hadoop集群的关键步骤。
- **执行与结果返回**:Driver将优化后的物理计划提交给ExecutionEngine,后者执行任务,从HDFS读取数据,最后返回执行结果给用户。
整个过程强调了Hive如何将SQL查询转化为底层的MapReduce作业,确保数据处理的性能和正确性。此外,使用Antlr解析SQL和SemanticAnalyzer进行语义分析也是理解Hive工作原理的重要部分。
Hive作为数据仓库工具,其核心价值在于提供了一种易于理解和使用的接口,让数据分析人员无需深入了解MapReduce就能进行复杂的数据查询和分析,极大地简化了大数据处理的开发流程。
16. Hive 查询
实验目的
(1)了解 Hive 的 SQL 基本语法
(2)掌握 Hive 多种查询方式
实验原理
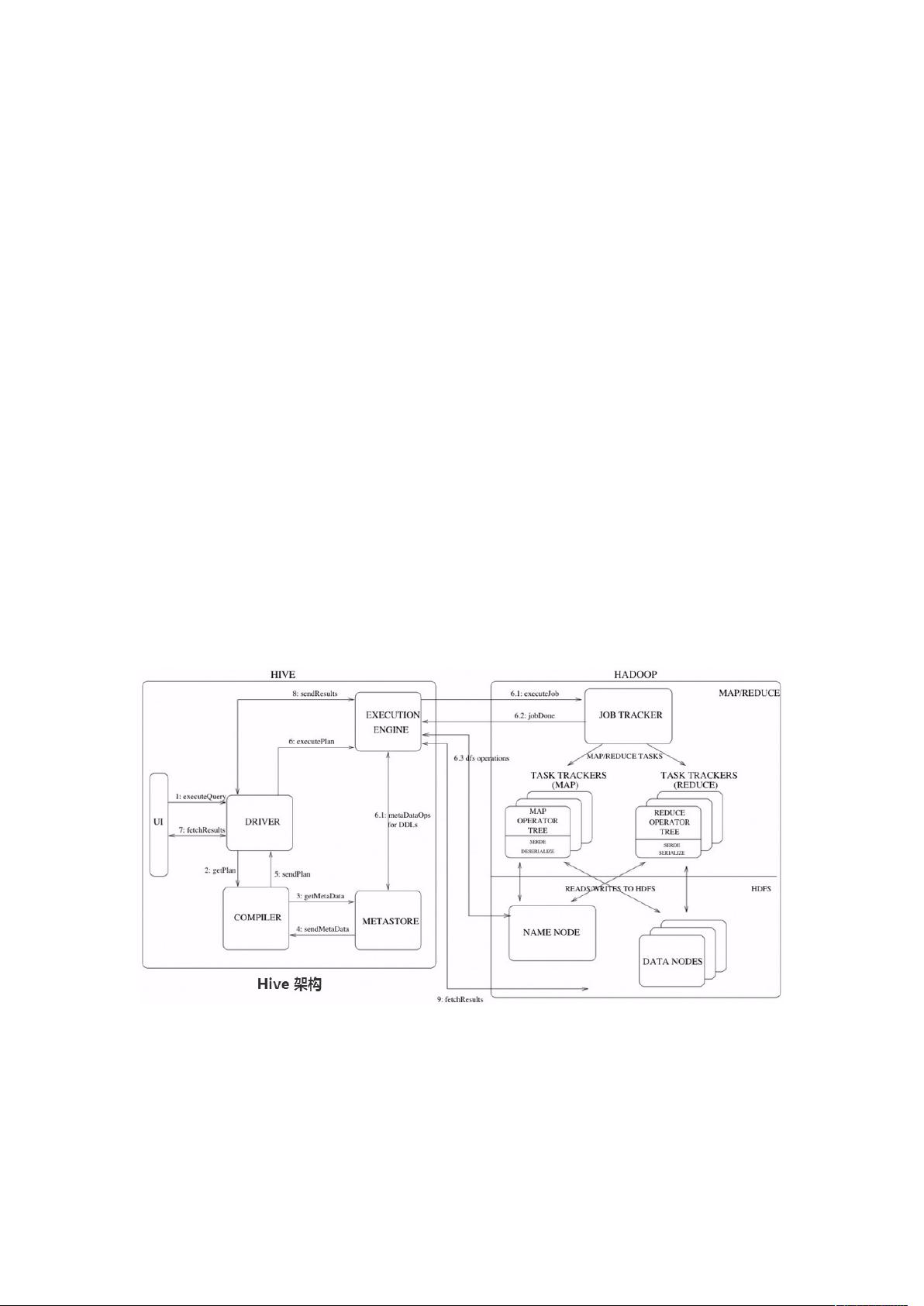
Hive 查询操作过程严格遵守 Hadoop MapReduce 的作业执行模型,Hive 将用户的 HQL 语句
通过解释器转换为 MapReduce 作业提交到 Hadoop 集群上,Hadoop 监控作业执行过程,然
后返回作业执行结果给用户。
如下图 Hive 执行流程大致步骤为:
(1)用户提交查询等任务给 Driver。
(2)编译器获得该用户的任务 Plan。
(3)编译器 Compiler 根据用户任务去 MetaStore 中获取需要的 Hive 的元数据信息。
(4)编译器 Compiler 得到元数据信息,对任务进行编译,先将 HiveQL 转换为抽象语法树,
然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将
逻辑计划转化为物理的计划(MapReduce),最后选择最佳的策略。
(5)将最终的计划提交给 Driver。
(6)Driver 将计划 Plan 转交给 ExecutionEngine 去执行,获取元数据信息,提交给 JobTracker
或者 SourceManager 执行该任务,任务会直接读取 HDFS 中文件进行相应的操作。
(7)获取执行的结果。
(8)取得并返回执行结果。
Hive 的入口是 Driver,执行的 SQL 语句首先提交到 Driver 驱动,然后调用 Compiler 解释驱
动,最终解释成 MapReduce 任务执行,最后将结果返回。
(编译流程)
一条 SQL 进入 Hive 经过上述过程,使得一个编译过程变成了一个作业。
(1)首先,Driver 会输入一个字符串 SQL,然后经过 Parser 变成 AST,这个变成 AST 的过
程是通过 Antlr 来完成的,也就是 Anltr 根据语法文件来将 SQL 变成 AST。
下载后可阅读完整内容,剩余7页未读,立即下载
2021-02-25 上传
2022-03-25 上传
点击了解资源详情
2019-06-06 上传
2021-02-24 上传
2021-06-19 上传
2011-06-11 上传
2015-10-16 上传
2019-01-09 上传

阿玫小酱当当囧
- 粉丝: 19
- 资源: 324
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
