优化SMP集群上线程化MPI执行
需积分: 9 195 浏览量
更新于2024-12-01
收藏 267KB PDF 举报
"这篇文档是关于在SMP(Symmetric Multi Processing)系统上优化线程化MPI(Message Passing Interface)执行的研究。作者Hong Tang和Tao Yang来自加利福尼亚大学圣巴巴拉分校的计算机科学系,他们提出了一种层次感知且适应性的通信方案,并设计了一个线程安全的网络设备抽象层,利用事件驱动同步来提高并行性能。实验表明,与进程基的MPI实现相比,这种线程化的MPI执行方式可以显著提升点对点和集体通信的性能。"
操作系统中的线程是操作系统资源管理的一种机制,它允许在单个进程中并发地执行多个代码流。线程比进程更轻量级,创建和销毁线程的开销远小于进程,因此在多核或多处理器系统中,线程能更高效地利用硬件资源,提高系统的并发性和性能。
MPI是一种广泛用于分布式内存并行计算的通信库,它允许不同计算节点(进程)之间的数据交换。在SMP集群中,每个节点通常包含多个处理器核心,而线程化MPI的目的是利用这些核心,让单个MPI进程内的多个线程并行执行任务,以实现更好的性能。
该研究指出,之前的实验证明,线程化执行MPI程序可以在多程序共享内存机器上带来显著的性能提升。然而,线程化MPI的实现并非没有挑战,关键在于如何设计有效的通信策略,使得线程间的通信既高效又不会引入过多的同步开销。
作者提出的层次感知和自适应通信方案针对这一问题,它考虑了系统层次结构,能够根据不同的系统状态和负载动态调整通信策略。同时,他们设计的线程安全网络设备抽象层通过事件驱动同步来处理点对点和集体通信,将这两者分离,可以进一步减少竞争条件和提高通信效率。
事件驱动同步是一种非阻塞的通信方式,它避免了传统同步机制可能导致的线程等待,从而减少了上下文切换的开销。通过这种方式,线程可以更有效地利用CPU时间,提高整体系统吞吐量。
在Linux SMP集群上的实验结果证实了这一设计的有效性,无论是在点对点通信还是集体通信(如广播、集合、扫描等)中,线程化MPI的性能都有显著改善。这表明,对于SMP集群环境,采用线程化执行策略是优化MPI应用性能的一个重要方向。
关键词包括:SMP集群、线程化MPI、性能优化、层次感知通信、事件驱动同步、集体通信和点对点通信。这些关键词反映了研究的核心内容和技术重点。
to large parallel systems or networked clusters. It maps
MPI nodes to individual processes. It is not easy to mod-
ify the current MPICH system to map each MPI node to
a lightweight thread because the low-level layers of MPICH
are not thread-safe. (Even though the latest MPICH re-
lease supports the MPI-2 standard, its MT level is actually
MPI_THREAD_SINGLE.)
WS- A cluster node
- MPI node (process)
- MPICH daemon process
- Inter-process pipe
- Shared memory
- TCP connection
WS
WSWS
WS
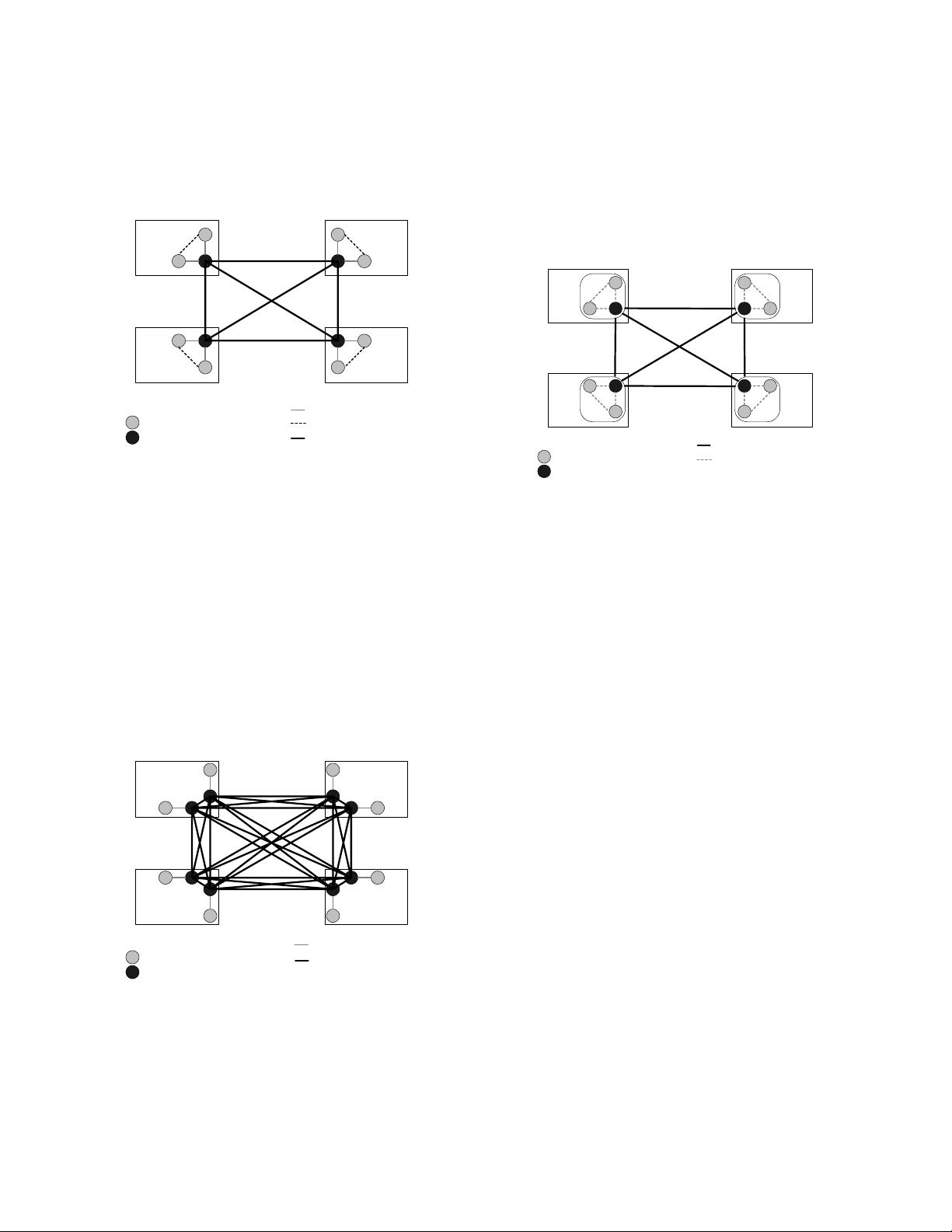
Figure 2: MPICH Using a Combination of TCP and
Shared Memory.
As shown in Figure 1, the current support for SMP clus-
ters in MPICH is basically a combination of two devices: a
shared-memory device and a network device such as TCP/IP.
Figure 2 shows a sample setup of such a configuration. In
this example, there are 8 MPI nodes evenly scattered on
4 cluster nodes. There are also 4 MPI daemon processes,
one on each cluster node, that are fully connected with each
other. The daemon processes are necessary to drain the mes-
sages from TCP connections and to deliver messages across
cluster-node boundaries. MPI nodes communicate with dae-
mon processes through standard inter-process communica-
tion mechanisms such as domain sockets. MPI nodes on
the same cluster node can also communicate through shared
memory.
WS
WSWS
WS
WS- A cluster node
- MPI node (process)
- MPICH daemon process
- Inter-process pipe
- TCP connection
Figure 3: MPICH Using TCP Only.
One can also configure MPICH at compile time to make
it completely oblivious to the shared-memory architecture
inside each cluster node and use loopback devices to com-
municate among MPI nodes running on the same cluster
node. In this case, the setup will look like Figure 3. In
theexample,weshowthesamenumberofMPInodeswith
the same node distribution as in the previous configuration.
What is different from the previous one is that there are now
8 daemon processes, one for each MPI node. Sending a mes-
sage between MPI nodes on the same cluster node will go
through the same path as sending a message between MPI
nodes on different cluster nodes, but possibly faster.
2.3 Threaded MPI Execution on SMP Clus-
ters
WS-Aclusternode
- MPI node (thread)
- TMPI daemon thread
- TCP connection
- Direct mem access
and thread sync
WS
WSWS
WS
Figure 4: Communication Structure for Threaded MPI
Execution.
In this section, we provide an overview of threaded MPI
execution on SMP clusters and describe the potential ad-
vantages of TMPI. To facilitate the understanding, we take
the same sample program used in Figure 2 and illustrate the
setup of communication channels for TMPI (or any thread-
based MPI system) in Figure 4. As we can see, we map MPI
nodes on the same cluster node into threads inside the same
process and we add an additional daemon thread in each
process. Despite the apparent similarities to Figure 2, there
are a number of differences between our design and MPICH.
1. In TMPI, the communication between MPI nodes on
the same cluster node uses direct memory access in-
stead of the shared-memory facility provided by oper-
ating systems.
2. In TMPI, the communication between the daemons
and the MPI nodes also uses direct memory access
instead of domain sockets.
3. Unlike a process-based design in which all the remote
message send or receive has to be delegated to the
daemon processes, in a thread-based MPI implemen-
tation, every MPI node can send to or receive from
any remote MPI node directly.
As will be shown in later sections, these differences have
an impact of the software design and provide potential per-
formance gain of TMPI or any thread-based MPI systems.
Additionally, TMPI gives us the following immediate ad-
vantages over process-based MPI systems. Comparing with
an MPICH system that uses a mixing of TCP and shared
memory (depicted in Figure 2):
383
剩余11页未读,继续阅读
2021-08-21 上传
2024-04-24 上传
2021-02-10 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

苍蝇①号
- 粉丝: 85
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
