时间序列加性离群点检测:基于残差统计的新方法
4 浏览量
更新于2024-08-31
收藏 440KB PDF 举报
"该文研究了一种基于残差统计的时间序列加性离群点检测算法,利用AR模型进行前向和后向拟合,通过数据相对变化率判别法减少离群点对拟合的影响,并基于高斯分布的假设检验确定离群点。这种方法在仿真中表现出高准确性,特别关注时间序列中的加性离群点检测。"
在时间序列分析中,离群点的检测是一项关键任务,因为它们可能掩盖真实模式或导致错误的分析结果。离群点可以分为多种类型,如孤立离群点和成片离群点,以及加性、更新、水平移位和暂时变更离群点。本文主要关注加性离群点,这类离群点直接改变了时间序列的平均值,而不会影响序列的结构。
传统的离群点检测方法包括统计、距离、密度和偏离方法。然而,针对有序的时间序列数据,需要更特定的策略。统计诊断和贝叶斯方法、遗传算法、神经网络和小波分析是常见的技术。文献中提到的粗糙集理论、多变量时间序列相似度矩阵和数据相对变化率等方法也展示了离群点检测的多样性。
本文提出了一种基于残差统计的加性离群点检测算法。首先,利用自回归(AR)模型对时间序列进行前向和后向拟合,以捕获序列的动态行为。AR模型是一种常用的线性预测模型,能够捕捉序列内的依赖关系。然后,通过数据相对变化率判别法,评估每个数据点与前后时刻的变化,这种方法有助于减弱离群点对拟合过程的干扰。最后,基于假设检验的原理,利用高斯分布的统计检验来分析残差。如果残差的统计特性显著偏离高斯分布,那么这可能表明存在离群点。
通过这样的流程,算法能够更准确地识别出加性离群点,尤其是在考虑时间序列趋势和其他复杂变化的情况下。在仿真实验中,该方法表现出了高精度,证明了其在检测加性离群点方面的有效性。这种方法的优势在于它能够适应时间序列的内在结构,并且通过统计分析减少了误判的可能性。
这种基于残差统计的加性离群点检测算法为时间序列分析提供了一个新的工具,特别是在监测和排除可能影响数据分析的异常值时。这种方法对于各种应用领域,如金融、环境监测、工业生产等,都有重要的实用价值,因为它可以帮助确保数据分析的准确性和可靠性。
基于残差统计的时间序列加性离群点检测算法研究基于残差统计的时间序列加性离群点检测算法研究
针对时间序列,提出了一种基于残差统计的加性离群点检测算法,利用AR模型对时间序列进行前向与后向拟
合;采用了数据相对变化率判别法减少离群点对拟合的影响;根据假设检验原理,以高斯分布统计检验对残差
进行统计分析并最终确定离群点。仿真结果表明,该方法对离群点检测有较高的准确性。
0 引言引言
在
时间序列中的离群点有很多类型,按照出现的个数,可以分为孤立离群点和成片离群点,按照产生的影响可以分为加性离
群点AO(Additive Outlier)、更新离群点IO(Innovational Outlier)、水平移位离群点LS(Level Shift Outlier)和暂时变更离群点
TC(Temporary Change Outlier)[1]。本文主要对时间序列中的加性离群点检测方法进行研究,并在此基础上提出了一种基于残
差统计的检测方法,仿真结果表明该方法在检测加性离群点方面具有较好的性能。
1 离群点检测方法研究离群点检测方法研究
针对无序的数据集,离群点检测方法主要有基于统计的方法、基于距离的方法[4]、基于密度的方法[5]和基于偏离的方法。
近年来,不少研究人员提出了专门针对时间序列的离群点检验算法,主要有统计诊断方法、贝叶斯方法、遗传算法、人工神经
网络、小波检测等。国内也有相关人员对此做了深入的研究[2-5]。文献[6]提出了基于粗糙集理论的序列离群点检测方法,它
利用粗糙集理论中的知识熵和属性重要性等概念来构建三种类型的序列,并通过分析序列中元素的变化情况来检测离群点。文
献[7]通过建立多变量时间序列数据相似度矩阵,对相似度矩阵进行转换以最大化数据之间的相关性,并采用随机游走模型计
算数据点之间的连接系数来检测数据点上的异常。文献[8]指出离群点与它所在时间段内的其他数据不具有相似性,从时序图
上看,离群点相对于它相邻区域内的数据具有很强的跳跃性,进而提出基于数据相对变化率的时间序列离群点识别方法。
2 基于残差统计的加性离群点检测算法基于残差统计的加性离群点检测算法
2.1 问题提出问题提出
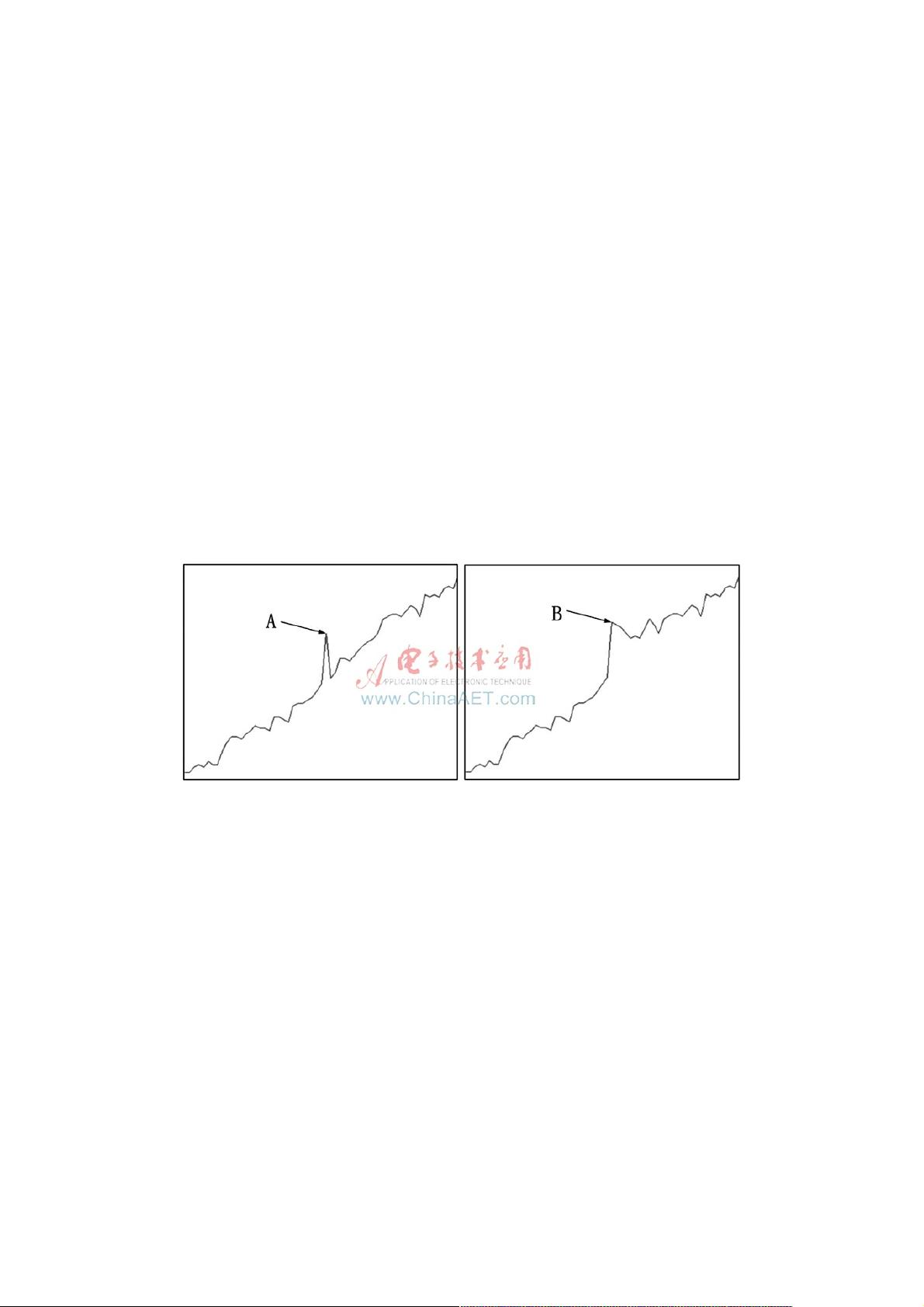
对于时间序列,离群点可能会隐藏在时间序列的趋势、季节或其他变化中,增加了检测难度。以图1所示的时间序列为例,
两个时间序列都处于上升趋势,A点明显偏离了整个趋势,应判定为离群点;B点虽然与前向时刻点在幅度变化率上发生了较
大变化,但符合后向时刻点的变化趋势,是一个正常时间序列点,因此不应判定为离群点。
图1 受加性离群点“干扰”的时间序列与正常时间序列
本文以一维时间序列为研究对象,提出了一种基于残差统计的加性离群点检测算法,基本思想是利用p阶
定义待检测时间序列数据样本为x
t
,t=1,2,3,4…M,x
t
∈R,并做如下假设:
(1)离群点随机分布;
(2)正常数据的数量远大于离群点数量。
2.2 算法描述算法描述
2.2.1 邻域区间变化率邻域区间变化率
定义1 邻域区间变化率:时间序列各时刻点与相邻前后时刻的幅度变化率。设时刻t的邻域区间变化率为δt,则:
δ
t
=|(x
t
-x
t-1
)+(x
t
-x
t
+1)|
对所有δ
t
进行考虑,选定门限δ,δ值的计算可以采用平均法或加权计算等。若δ
t
>δ,则将x
t
标志为LK点(疑似离群点),否
则标志为uLK点(非疑似离群点)。
离群点相对于它前后相邻数据都会有较大变化,因此邻域区间变化率要同时对前向时刻和后向时刻进行考虑。定义LK点和
uLK点是为了在拟合过程中尽量减少离群点的影响,对疑似离群点不作拟合参考。
2.2.2 AR模型拟合与参数计算模型拟合与参数计算
拟合常用的模型有AR模型、MA模型、ARIMA模型等。AR模型一般用于拟合平稳的时间序列,而时间序列从局部来看近似
一个平稳的过程,并且AR模型结构相对简单,拟合精度较高,因此本文选用p阶自回归AR模型。为了准确反应各检测点的局
部变化属性,并减少离群点对参数估计的影响,本文在文献[9]所采用的两窗口模型基础上,提出了改进的窗口计算模型,基
本原理是:检测窗口仅包含t时刻待检测点,前向学习窗口和后向学习窗口位于检测窗口邻近两侧,宽度为N,并且N>p,根据
前向和后向学习窗口中的数据分别对t时刻待检测点进行前向和后向拟合,采用剪枝思想,若学习窗口中包含疑似离群点LK,
则该点退出学习窗口不参与计算,其余时间轴上的uLK点向t时刻整体移位并填满窗口。如图2所示。
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38661466
- 粉丝: 7
- 资源: 930
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
