GrowingIO大数据实践:Spark在无埋点数据采集中的挑战与优化
PDF格式 | 1.11MB |
更新于2024-08-30
| 100 浏览量 | 举报
"Spark在GrowingIO数据无埋点全量采集场景下的实践"
在大数据领域,Spark作为一种快速、通用、可扩展的计算引擎,被广泛应用于处理海量数据。本实践分享了GrowingIO如何利用Spark应对数据无埋点全量采集带来的挑战。GrowingIO是一家专注于数据分析的初创公司,其核心业务特点是无需用户预先埋点即可获取全面的行为数据。这种全量采集的方式使得数据量庞大且增长迅速,对数据处理系统提出了极高的要求。
GrowingIO每天处理的数据量达到数百亿条,这在初创公司中是非常显著的规模,因此公司需要构建一个能够有效处理、存储和查询这些数据的大数据平台。面对这样的需求,Spark成为了理想的解决方案,因其在实时计算、批量处理和内存计算上的优势,可以有效地支持大数据的高效处理。
在构建数据平台的过程中,面临的主要问题包括数据处理压力大、数据量变化快、高峰时段的波峰波谷、实时查询需求以及多维度组合查询。Spark的弹性分布式数据集(Resilient Distributed Datasets, RDD)特性使得数据处理具有高吞吐量和容错能力,而Spark Streaming则能实现对实时数据流的快速处理。此外,Spark SQL的多维度查询支持,配合高效的索引技术,可以满足GrowingIO用户对数据的即时分析需求。
为了应对数据量的快速增长和处理需求的变化,GrowingIO的数据平台需要具备良好的伸缩性。Spark集群可以通过动态资源调度(Dynamic Resource Scheduling)来自动调整计算资源,以应对数据量的增减。同时,通过与Hadoop等存储系统的集成,Spark可以实现数据的高效存储和检索。
在实践中, GrowingIO可能还会面临诸如数据质量问题、性能优化、监控报警等问题。例如,数据清洗和预处理是大数据工作流中的关键步骤,Spark提供了丰富的数据处理库,如DataFrame和Dataset API,可以帮助进行数据转换和清洗。对于性能优化,可以采取如调整Executor内存分配、减少shuffle操作等方式提升效率。监控报警则能够及时发现并解决系统运行中的异常情况,确保平台稳定运行。
Spark在GrowingIO的数据无埋点全量采集场景下发挥了重要作用,它不仅支撑了公司的核心业务,还为解决大数据处理中的各种挑战提供了强大的工具。通过不断优化和调整,GrowingIO成功地构建了一个能够应对海量数据挑战的大数据平台,为用户提供快速、灵活的数据分析服务。
Spark在在GrowingIO数据无埋点全量采集场景下的实践数据无埋点全量采集场景下的实践
今天跟大家分享的是我们GrowingIO在使用Spark中的经验,遇见的一些问题,以及我们修复的方法。在来之前,昨天晚上我
在跟我们组同事讨论的时候,我说我发给他们简要写的我是GrowingIO的大数据工程师,我们组的几个工程师都非常的不屑,
说现在大数据已经烂大街了,所以他们对外自称数据工程师,不叫大数据工程师。
GrowingIO业务功能背后的考验
事实上,我们是一个刚成立一年的公司,今年5月份刚过了一周岁的生日,是一个标准的创业公司,但是到目前为止我们每天
处理的数据量已经超过了几百亿条,所以在我看来是一个标准的大数据公司。
每天处理这么多数据的话,我们当然会遇到很多问题,今天主要的内容就是首先介绍我们公司,我们的业务模型和我们遇到的
一些问题。第二部分我们会根据这些问题讲一下我们是如何思考和选择搭建我们自己的大数据平台。最后一部分,当我们平台
搭建完之后,会遇到一些问题,我们会想办法去优化在Spark使用过程中的这些问题。
第一部分就是我们公司介绍,我们是去年刚成立的一家公司,是做数据分析的,我们跟之前的数据公司不一样就是我们提供的
是全量采集的数据,不需要埋点,只要接入我们SDK之后,你就立刻能够获得你想要的数据分析的结果。我们现在提供iOS、
安卓、Web、H5的SDK。
我们采用的是全量采集的方案,所以不需要提前埋点,就是说所有的浏览、访问、点击所有的行为都会被采集到,这个数据量
是非常大的,而且我们提供按需筛选数据的功能,如果你想要知道某一个按键的点击量,我们会立刻帮你筛选出来。还有我们
支持随时回溯任意一个事件。我们也支持不同的图表功能、不同的维度、相互的拖拽和组合,我们提供40多种不同的维度。
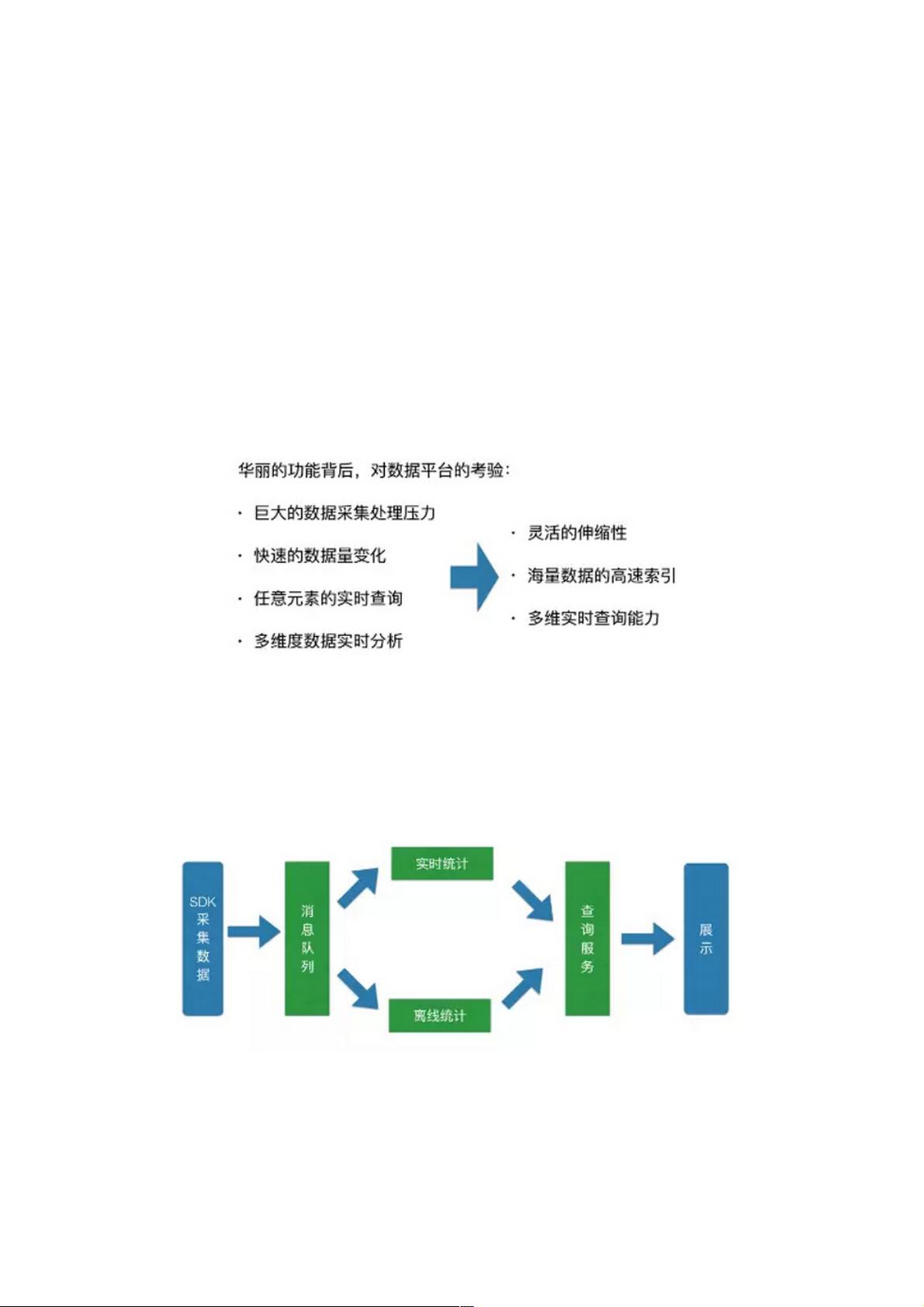
提供这么多功能的话对我们平台的压力是非常大的。首先就是我们的数据处理压力非常大,我们每天要处理好几百亿条数据,
我们的数据量变化也非常快,有些应用可能周五是高峰期,有些应用是周末的高峰期,所以我们的数据有一个波峰和波谷的概
念。我们支持任意元素的实时查询,以及支持多维度的组合,所以需要整个数据平台有很强的伸缩性。我们还要支持海量数据
的高速索引,不能让用户等待时间过长,同时我们要支持多维数据的实时查询。
GrowingIO数据平台搭建
为了支持这么多功能,我们怎么搭建我们的数据平台的呢?
先看一下我们数据处理的主要步骤,首先是我们SDK采集数据,采集数据之后,首先把它扔到我们的消息队列里做一个基础
的持久化,之后我们会有两部分,一部分是实时统计,一部分是离线统计,这两部分统计完之后会把统计结果存下来,然后提
供给我们的查询服务,最后是我们外部展示界面。我们的数据平台主要基于中间的四个绿色的部分。
关于要求,对消息队列来说肯定是吞吐量一定要大,要非常好的扩展性,如果有一个消息的波峰的话要随时能够扩展,因为所
有的东西都是分布式的,所以要保证节点故障不会影响我们正常的业务。
我们的实时计算目前采用的是分钟级别的实时,没有精确到秒级,离线计算需要计算速度非常快,这两部分我们当初在考虑的
时候就选用了Spark,因为Spark本身既支持实时,又支持离线,而且相对于其他的实时的方案来说,像Flink或者是Storm和
Samza来说,我们不需要到秒级的这种实时,我们需要的是吞吐量,所以我们选择Spark。实时部分用的是Spark streaming,
离线部分用的是Spark offline的方案。
下载后可阅读完整内容,剩余6页未读,立即下载
相关推荐




weixin_38539053
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Cucumber Java极简设置教程及源码分享
- LabVIEW实现任意类型文件快速打开方法
- 利用XML和XSLT创建下一代测序工作流
- 精选优质分散应用程序资源:awesome-dapps清单
- 深入解析TCP-IP协议核心原理与应用
- 深入理解jquery-easyui-datagridview的使用与实践
- 2010~2015年CEC测试函数集及MATLAB代码
- 用Arduino打造DIY酷炫手表的项目教程
- 实时视频流服务器:GifStreaming技术实现与应用
- 实现SSH框架下的多条件查询功能
- Ruby on Rails中before_actions Gem的使用与组织
- Crystal库实现ANSI转义序列控制终端
- Apache Maven 3.5.0:强化构建管理与项目工具
- 经典算法集锦:背包、最短路径、图论与分治技巧
- 全国反洗钱法项目开发中的全移动机器人技术
- Adafruit_SensorTester: C++驱动程序模板的简单使用指南
