Pandas中详尽NaN值处理与示例:提升数据质量的必修课
版权申诉
在Pandas中处理NaN值的方法是数据清洗过程中的重要环节,特别是在处理大型数据集时,因为缺失值可能会影响分析结果的准确性和模型的性能。本文将详细介绍如何在Pandas库中有效地识别、替换和删除NaN值。
首先,了解什么是NaN值。在数据分析中,NaN代表"Not a Number",它是一种特殊的值,表示数据缺失或者无效。在Pandas中,当数据集中出现无法解析或缺失的值时,Pandas会自动将其标记为NaN。处理这类数据是数据分析的第一步,因为它可能包含错误信息或需要额外的处理。
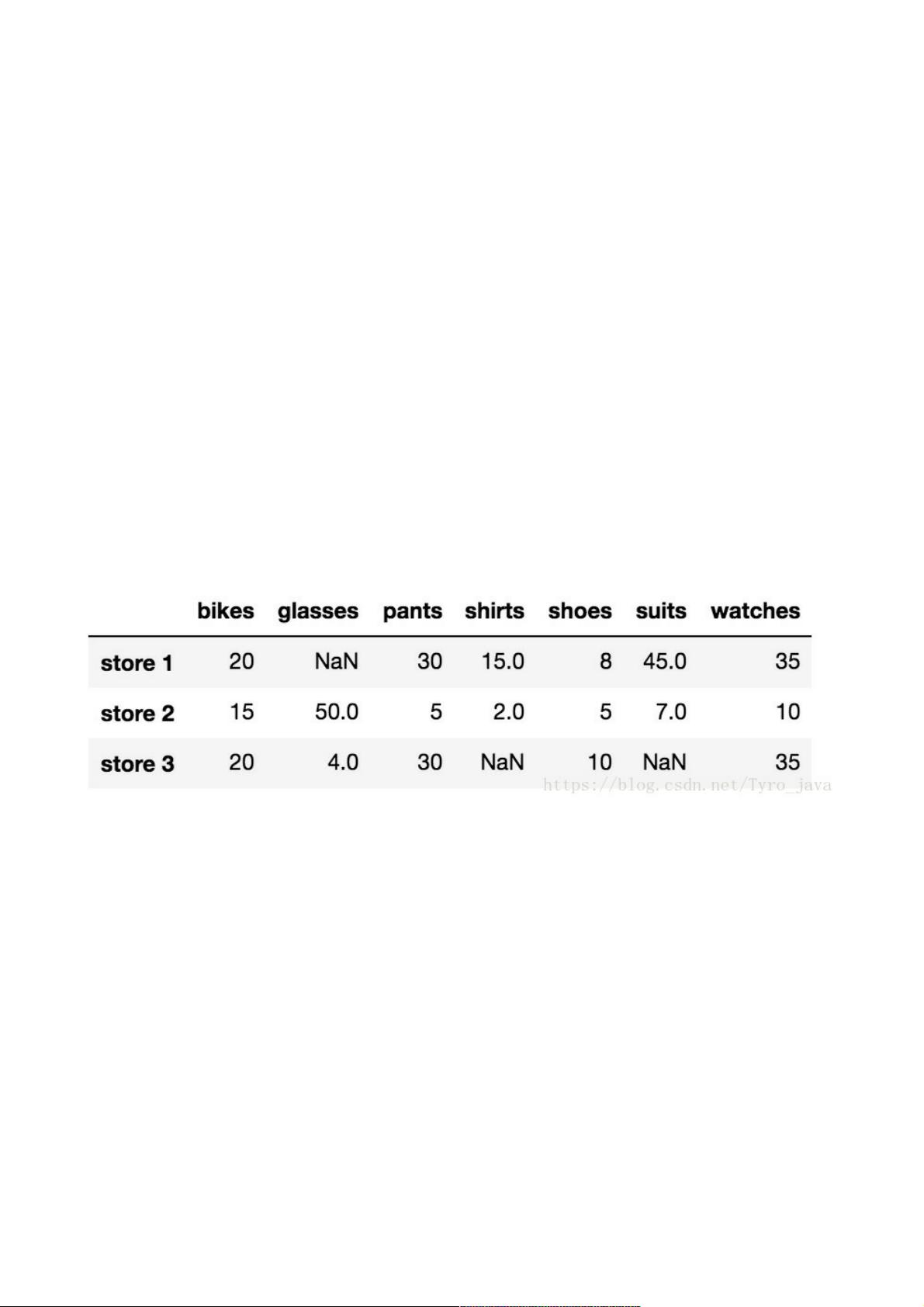
在创建一个包含NaN值的DataFrame时,如示例所示:
```python
import pandas as pd
# 创建一个字典列表
items2 = [{'bikes': 20, 'pants': 30, 'watches': 35, 'shirts': 15, 'shoes': 8, 'suits': 45},
{'watches': 10, 'glasses': 50, 'bikes': 15, 'pants': 5, 'shirts': 2, 'shoes': 5, 'suits': 7},
{'bikes': 20, 'pants': 30, 'watches': 35, 'glasses': 4, 'shoes': 10}]
# 创建DataFrame并设置行索引
store_items = pd.DataFrame(items2, index=['store1', 'store2', 'store3'])
# 显示DataFrame
store_items
```
在处理数据时,我们首先需要检查数据集中NaN值的存在情况。使用`.isnull()`方法可以得到一个布尔型DataFrame,其中True表示包含NaN,False表示不包含NaN。例如:
```python
# 计算在store_items中NaN值的个数
x = store_items.isnull().sum().sum()
print('在我们DataFrame中NaN的数量:', x)
```
输出结果表明有3个NaN值。
接着,我们可以根据需求对NaN值进行处理。常见的方法包括:
1. **删除含有NaN值的行或列**:使用`dropna()`函数,可以选择性地删除包含NaN值的行或列。
2. **填充(Fill)NaN值**:
- 使用`fillna()`函数,可以指定特定的值替换NaN,如平均值、中位数、众数或其他固定值。
- 使用`ffill()`或`bfill()`方法,分别向前填充(用前一行的非NaN值)或向后填充(用后一行的非NaN值)。
3. **插值(Interpolate)**:对于时间序列数据,可以使用`interpolate()`函数进行插值,以填充缺失值。
4. **模型预测**:如果数据集较大,且缺失值分布合理,可以尝试使用其他观测值来预测缺失值,然后进行填充。
处理Pandas中的NaN值是一个必不可少的数据预处理步骤,它涉及到识别、理解以及合理处理这些缺失值,以确保数据质量,从而提升后续分析的准确性和可靠性。通过理解并熟练运用上述方法,数据分析师和科学家能够更好地利用Pandas进行高效的数据清洗和分析工作。
在在Pandas中处理中处理NaN值的方法值的方法
主要介绍了在Pandas中处理NaN值的方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一
定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
关于关于NaN值值
-在能够使用大型数据集训练学习算法之前,我们通常需要先清理数据, 也就是说,我们需要通过某个方法检测并更正数据中的
错误。
- 任何给定数据集可能会出现各种糟糕的数据,例如离群值或不正确的值,但是我们几乎始终会遇到的糟糕数据类型是缺少
值。
- Pandas 会为缺少的值分配 NaN 值。
创建一个具有创建一个具有NaN值得值得 Data Frame
import pandas as pd
# We create a list of Python dictionaries
# 创建一个字典列表
items2 = [{'bikes': 20, 'pants': 30, 'watches': 35, 'shirts': 15, 'shoes':8, 'suits':45},
{'watches': 10, 'glasses': 50, 'bikes': 15, 'pants':5, 'shirts': 2, 'shoes':5, 'suits':7},
{'bikes': 20, 'pants': 30, 'watches': 35, 'glasses': 4, 'shoes':10}]
# 创建一个DataFrame并设置行索引
store_items = pd.DataFrame(items2, index = ['store 1', 'store 2', 'store 3'])
# 显示
store_items
显示:
数据量大时统计NaN的个数
# 计算在store_items中NaN值的个数
x = store_items.isnull().sum().sum()
# 输出
print('在我们DataFrame中NaN的数量:', x)
输出:
在我们DataFrame中NaN的数量: 3
.isnull() 方法返回一个大小和 store_items 一样的布尔型 DataFrame,并用 True 表示具有 NaN 值的元素,用 False 表示非 NaN
值的元素。
store_items.isnull()
显示:
下载后可阅读完整内容,剩余3页未读,立即下载
2020-09-20 上传
2020-12-31 上传
2020-09-19 上传
点击了解资源详情
点击了解资源详情
2024-09-13 上传
2023-09-06 上传
2023-10-26 上传
2023-05-09 上传

weixin_38628183
- 粉丝: 6
- 资源: 889
 我的内容管理
展开
我的内容管理
展开







最新资源
- CSS+DIV常用方法说明
- 《深入浅出Ext+JS》样章.pdf
- sudo应用的详细阐述
- sql金典.pdf sql金典.pdf
- tomcat配置手册
- webwork开发指南
- Ajax In Action 中文版
- 数据挖掘论文.。。。。
- Visual Studio 2008 可扩展性开发4:添加新的命令.doc
- Visual Studio 2008 可扩展性开发3:Add-In运行机制解析(下).doc
- Visual Studio 2008 可扩展性开发3:Add-In运行机制解析(上).doc
- 蚁群分区算法C#实现
- Visual Studio 2008 可扩展性开发2:Macro和Add-In初探
- C、C++高质量编程指导
- BIND9 管理员参考手册
- MiniGUI用户手册
