日志分析实战:从CentOS搭建到Hadoop Spark集群
需积分: 9 99 浏览量
更新于2024-07-18
收藏 10.93MB PDF 举报
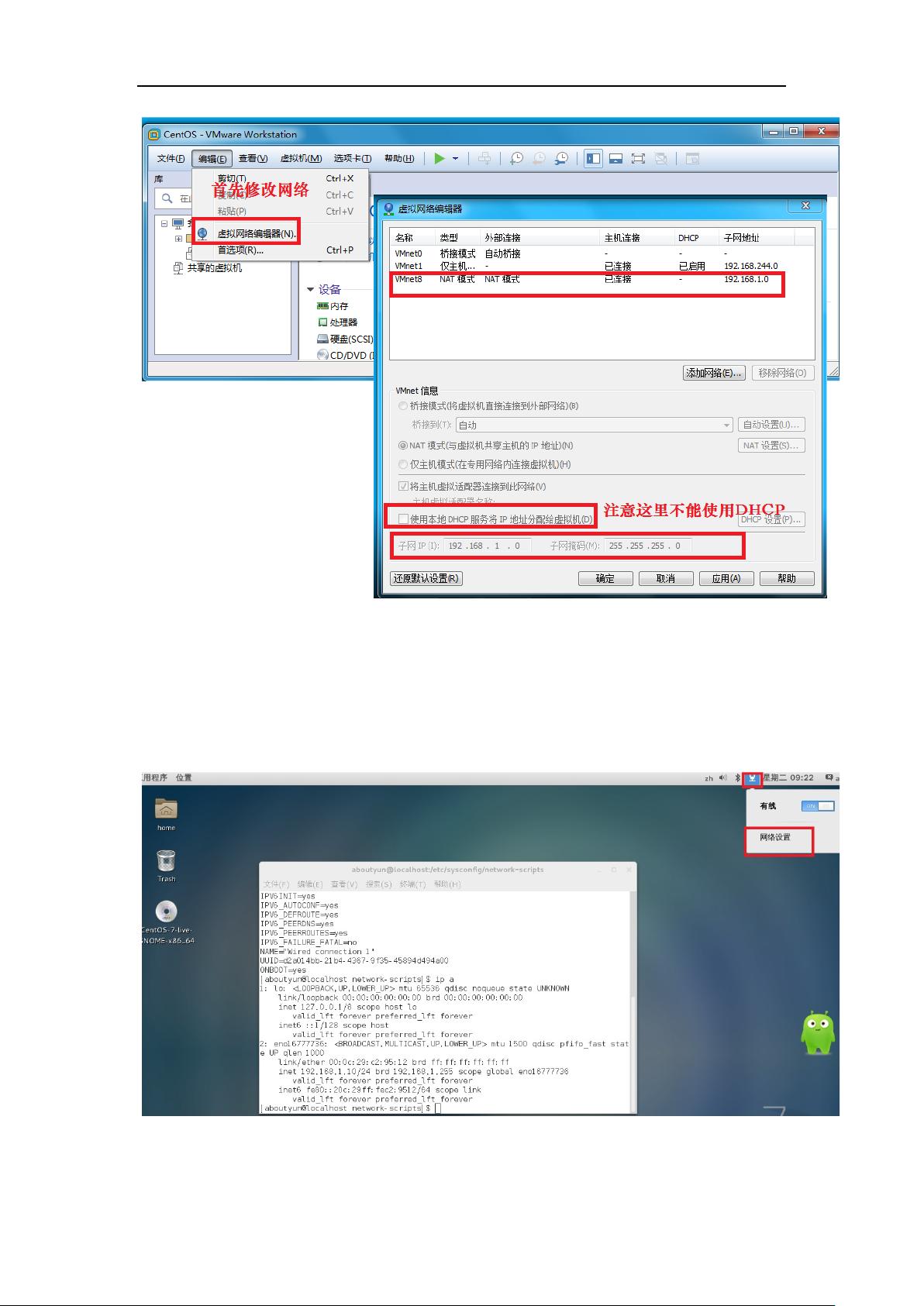
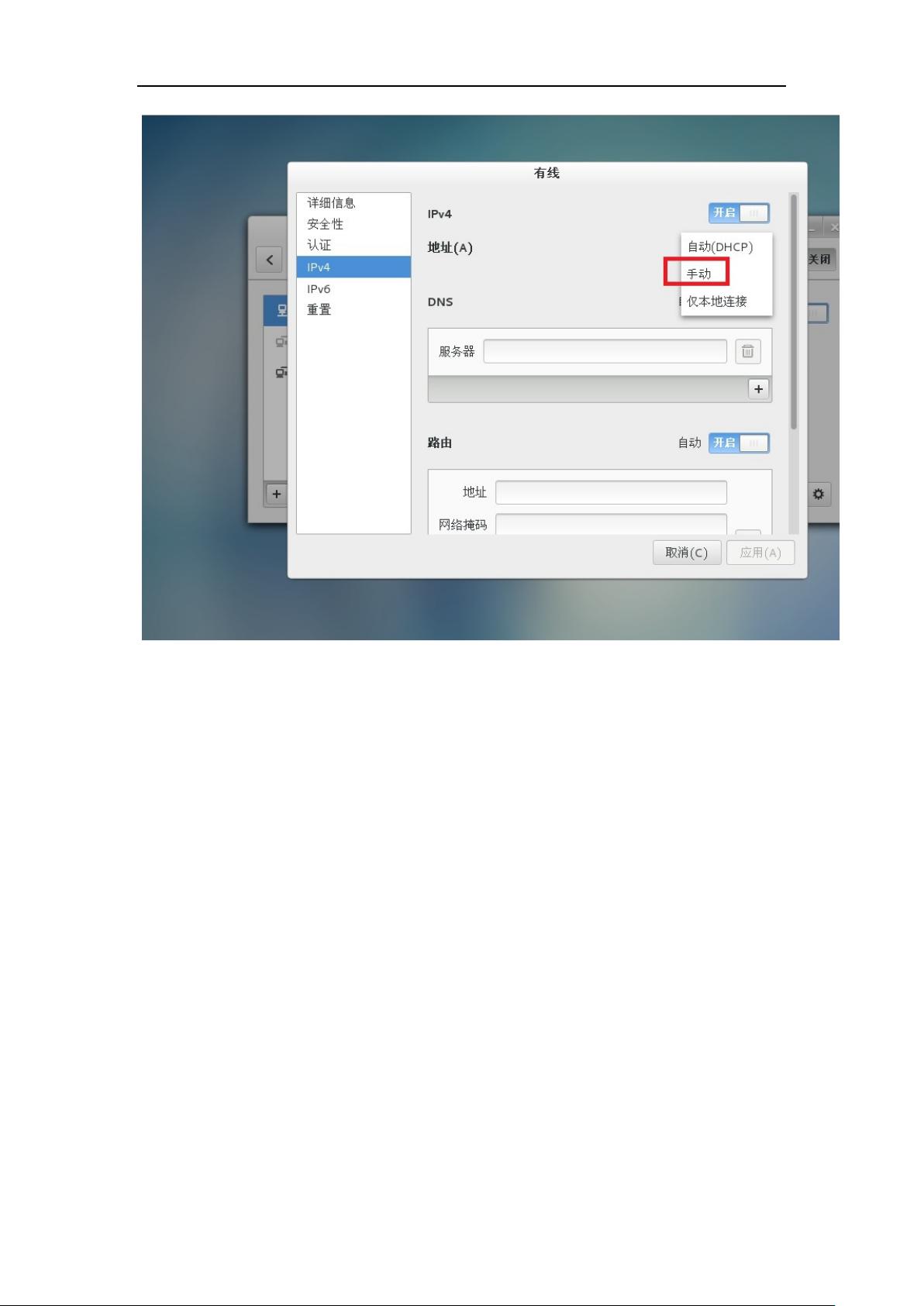
本篇文章主要关注的是一个全面的日制分析项目,涉及云计算背景下的日志分析实战。首先,项目从基础的Linux操作系统CentOS的安装与配置开始,选择CentOS作为Linux发行版是因为其稳定性高且适合大数据处理环境。文章详细介绍了如何安装CentOS,包括设置快捷键、网络配置以及远程连接,确保了后续操作的顺畅进行。
项目的核心是围绕大数据技术Hadoop、Spark、Kafka和Flume展开。作者强调了在选择这些工具时,需根据项目需求和版本兼容性来决定合适的版本。Hadoop和Spark的集群搭建是关键环节,其中,Scala的安装是Spark集群中的一个重要补充,而SparkSQL的精简总结则有助于理解其工作原理和在Spark应用程序中的应用。此外,Kafka集群的安装过程中,还提到了可能遇到的Zookeeper状态显示问题。
Flume的安装和使用是数据收集和传输的一部分,对于数据的实时监控和处理至关重要。文章还介绍了如何使用IntelliJ IDEA搭建Spark Streaming的开发环境,包括手动添加本地依赖、配置Scala开发环境,并展示了如何在SparkLocal模式下进行文本清洗,以及如何将Spark Streaming程序迁移至Spark集群中运行。
整个项目不仅涵盖了理论知识,更注重实践操作,旨在帮助读者掌握从基础环境配置到高级数据分析的一整套流程,体现了云计算时代日志分析项目的实际应用价值。无论是对云计算初学者还是经验丰富的开发者,这个项目都提供了丰富的学习资料和实践经验。
about 云--活到老学到老
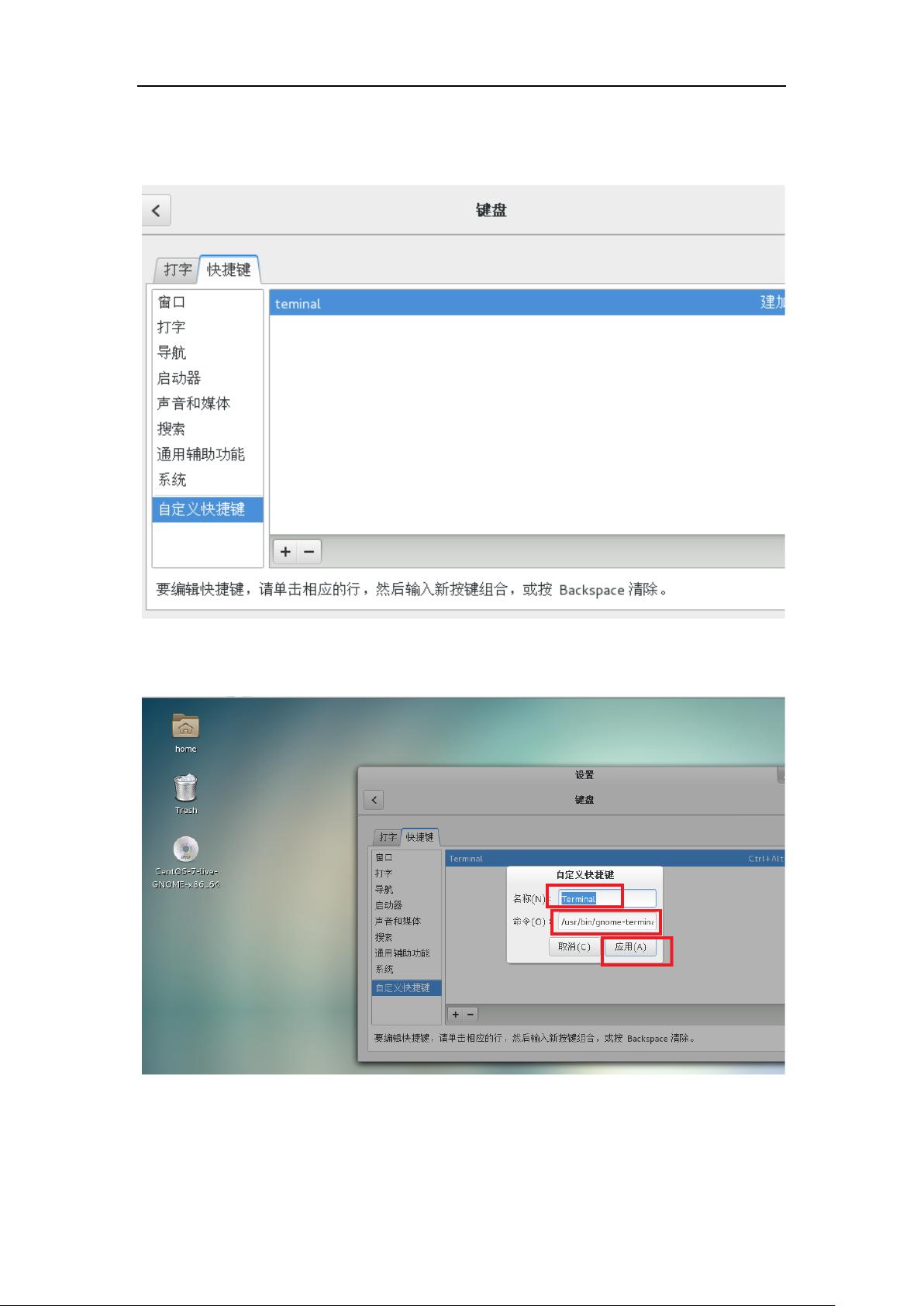
需要点击右侧,点击之后,会看到建加速键
【注意路径不要写错,否则自定义不成功,上图中我的路径就写错了】
,按下 ctrl+alt+t
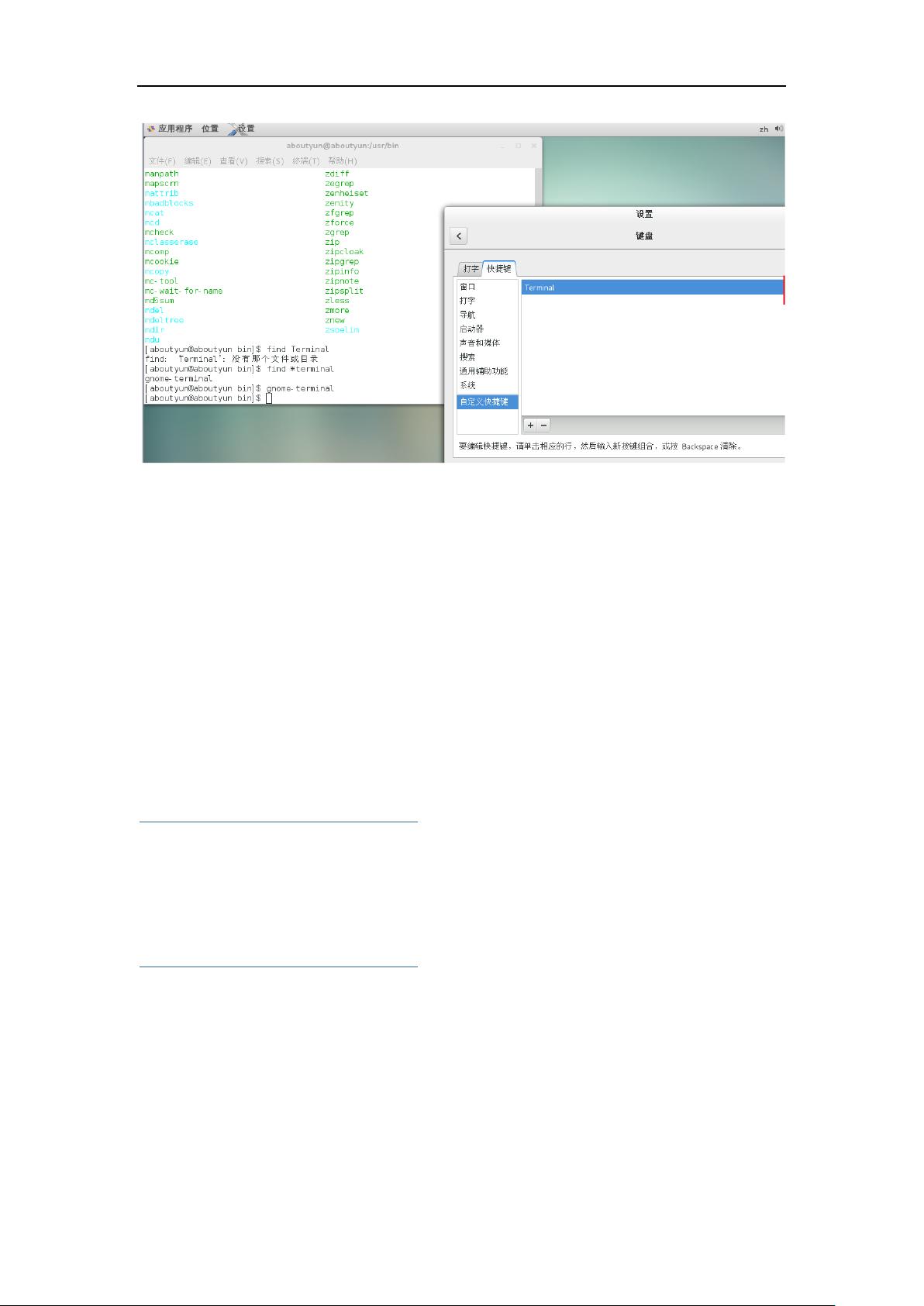
自定义就完成了,会看到相应的键,如下图所示。【比较难操作的是选定可能弹出上图所示内容】
剩余194页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-16 上传
2022-12-12 上传
2021-06-07 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情









