Spark初学者实践:从环境配置到读取文件
需积分: 25 89 浏览量
更新于2024-08-05
15
收藏 1.9MB DOCX 举报
实验七:Spark初级编程实践是“大数据技术原理与应用”课程的重要组成部分,主要目标是让学生通过实际操作掌握Spark这一强大的分布式计算框架。本次实验在一台配置较高的设备上进行,包括Intel Core i5-10300H处理器、16GB RAM、Windows 10家庭中文版主机操作系统以及Ubuntu Kylin 16.04作为虚拟机操作系统。Hadoop版本为3.1.3,JDK版本为1.8,开发工具选用的是Eclipse。
实验开始于安装Hadoop和Spark,这涉及将下载的安装包解压到指定目录并按照标准流程进行安装。首先,学生需要打开命令行界面,执行`./bin/spark-shell`命令来启动Spark Shell,如图2所示,这一步是验证Spark是否成功安装和配置的关键步骤。
实验的核心内容是利用Spark处理数据,首先是读取Linux系统本地文件。在Spark Shell环境中,学生操作了Linux本地文件"/home/hadoop/test.txt",目的是统计该文件的行数,这展示了如何在分布式环境中对小规模数据进行简单操作,同时也展示了Spark的数据处理能力,如图3所示。
接着,实验进一步扩展到处理HDFS(Hadoop Distributed File System)中的数据,这在大数据场景中尤为重要。学生尝试读取HDFS中的文件"/user/hadoop/test.txt",尽管这部分内容在提供的部分并未详述,但可以推测学生会使用Spark的API来读取分布式存储中的数据,并可能执行类似统计分析的操作。
通过这些实践,学生能够理解Spark的分布式计算模型,学习如何高效地在大规模数据集上进行处理,包括数据读取、基本操作以及结果的可视化。此外,实验还强调了在不同文件系统间切换和协调的能力,这对于理解和使用现代大数据平台至关重要。
总结来说,这个实验不仅锻炼了学生的编程技能,还加深了他们对Hadoop和Spark生态系统及其在大数据处理中的应用的理解。通过解决实际问题,学生能够提升数据处理的效率,为后续深入研究或实际工作中处理大规模数据打下坚实的基础。
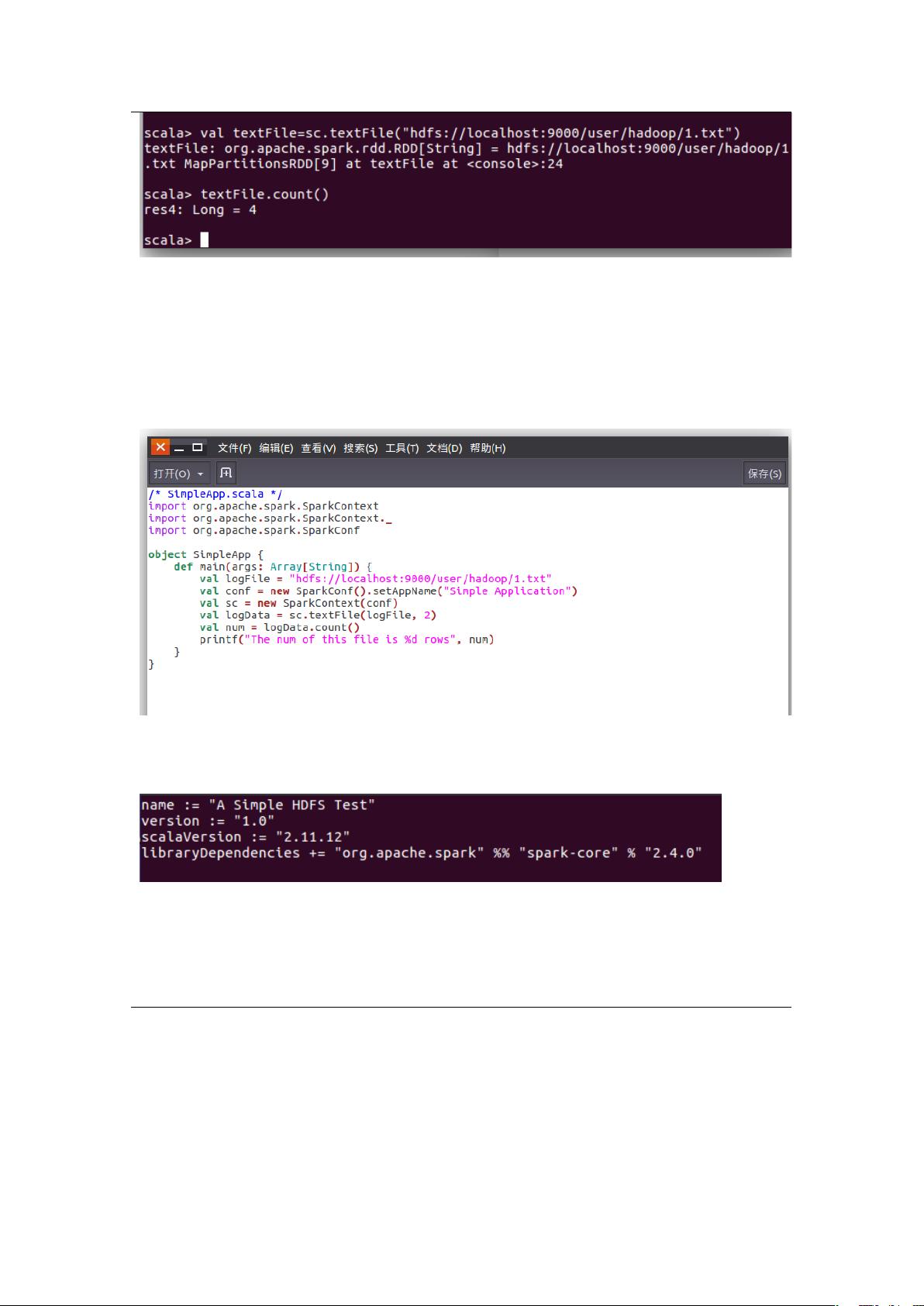
图 5 spark 统计 hdfs 文件 1.txt 行数
(3) 编写独立应用程序(推荐使用 Scala 语言),读取 HDFS 系统文件“/user/hadoop/test.txt”(如
果该文件不存在,请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打
包成 JAR 包,并将生成的 JAR 包通过 spark-submit 提交到 Spark 中运行命令。
SimpleApp.scala 文件内代码内容如下所示:
图 6 SimpleApp.scala 文件内容
simple.sbt 文件内代码如下:
图 7 simple.sbt 文件内容
使用、usr/local/sbt/sbt package 命令将以上代码文件夹打 jar 包,打包完成后可看到打包成
功的输出,如下图:
剩余10页未读,继续阅读
2024-01-16 上传
2023-11-07 上传
2024-04-24 上传
点击了解资源详情
点击了解资源详情
2023-05-28 上传

是小猪猪哦
- 粉丝: 135
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 主成分分析在SPSS中的操作应用(pdf格式)
- snmp++ document
- 2009年计算机考研大纲
- avr910下载线的制作原理图
- unix toolbox
- Excel2003函数应用完全手册
- sas统计分析基础(ppt格式)
- sasV8 操作入门(非常好的中文学习资料)
- SQL Server Express Edition eBook
- 测试驱动的设计和开发.pdf
- ARM应用系统开发详解全集
- 敏捷软件架构、开发方法与开放源码最佳实践.pdf
- 74HC164.PDF
- 4AM14电机驱动集成芯片
- Advanced CORBA® Programming with C++
- 嵌入式视频处理基本原理
