Pytorch SSD模型详解与深度解析
175 浏览量
更新于2024-09-07
收藏 76KB PDF 举报
本文将深入分析基于Pytorch SSD (Single Shot MultiBox Detector) 模型的构建与理解。SSD 是一种目标检测算法,它通过一次前向传播就能同时预测多个尺度的目标,显著提高了检测速度。PyTorch 是一个流行的深度学习框架,其简洁易用的API使得模型实现变得更为方便。
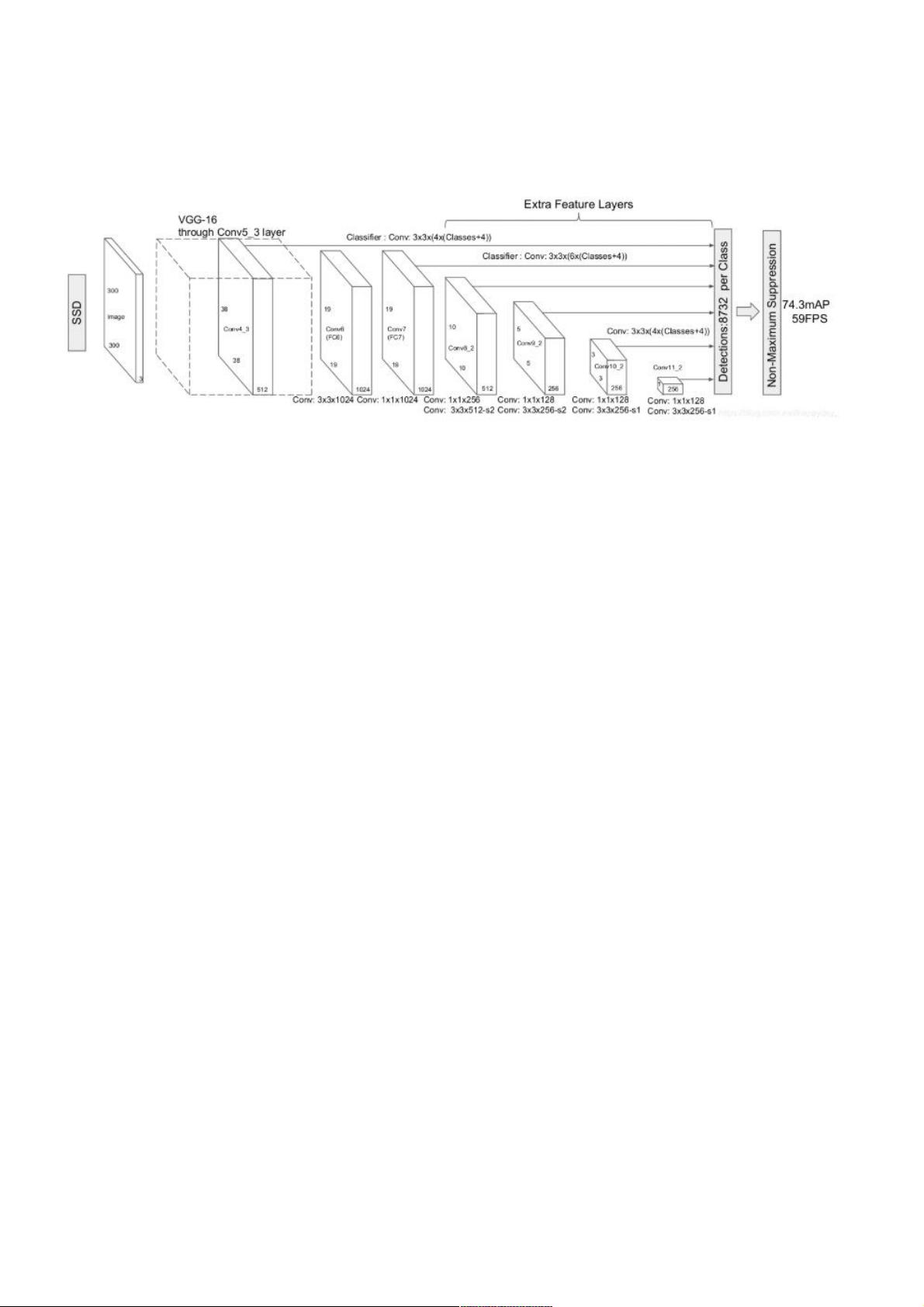
首先,我们回顾一下PyTorch SSD模型的基本构成。模型的核心是VGG(Visual Geometry Group)基础网络结构,它提供了一系列的卷积层和池化层作为特征提取部分。VGG基础网络定义了两个配置:'300' 和 '512',分别对应不同尺寸的输入图像。对于'300'配置,网络结构包括多个卷积块(Convolutional blocks),如卷积层、最大池化层(Max Pooling layers)以及在某些部分使用的Batch Normalization(批标准化)层。
在VGG结构之后,附加层(extras)被添加以处理更高层次的特征。对于'300'配置,这部分包括几个卷积层和步长为1的池化层,旨在捕捉更高级别的特征。每个附加层后的输出被用于不同尺度的特征金字塔(Feature Pyramid),这是SSD模型的一个关键特性,它允许检测不同大小的目标。
Mbox层是模型的核心组成部分,它定义了每个特征图位置上要产生的候选框的数量(例如'300'配置中为4, 6, 6, 6, 4, 4)。这些候选框会在后续的步骤中进行非极大值抑制(Non-Maximum Suppression, NMS),以减少重复检测并选择最有可能的对象。
每输入一张图像,经过这个SSD模型后,会产生8732个候选框作为输出。这反映了模型在不同特征层上生成的多尺度物体检测可能性。输入图像的大小会影响到网络的计算复杂度和最终的检测性能。
文章作者参考了GitHub上的SSD实现,并对模型进行了详细的分析,有助于读者理解其内部工作原理,包括如何调整网络参数、如何处理多尺度目标检测以及优化过程中的关键决策。对于那些希望在计算机视觉任务中使用深度学习特别是目标检测技术的开发者来说,这篇基于Pytorch SSD模型的分析文章无疑提供了宝贵的学习资源。
基于基于Pytorch SSD模型分析模型分析
今天小编就为大家分享一篇基于Pytorch SSD模型分析,具有很好的参考价值,希望对大家有所帮助。一起跟随
小编过来看看吧
本文参考github上SSD实现,对模型进行分析,主要分析模型组成及输入输出大小.SSD网络结构如下图:
每输入的图像有8732个框输出;
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
#from layers import *
from data import voc, coco
import os
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [],
}
extras = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [],
}
mbox = {
'300': [4, 6, 6, 6, 4, 4], # number of boxes per feature map location
'512': [],
}
VGG基础网络结构基础网络结构:
def vgg(cfg, i, batch_norm=False):
layers = []
in_channels = i
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
size=300
vgg=vgg(base[str(size)], 3)
print(vgg)
输出为:
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-02-20 上传
2021-03-28 上传
2024-01-16 上传
2024-09-06 上传
点击了解资源详情
点击了解资源详情

weixin_38614112
- 粉丝: 3
- 资源: 930
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
